


Method
Detailed Results
This page provides detailed results for the method(s) selected. For the first 20 test images, we display the original image, the color-coded result and an error image.
The error image contains 4 colors:
red: the pixel has the wrong label and the wrong category
yellow: the pixel has the wrong label but the correct category
green: the pixel has the correct label
black: the groundtruth label is not used for evaluation
Test Set Average
|
Test Image 0
 Input Image  Prediction  Error |
Test Image 1
 Input Image  Prediction  Error |
Test Image 2
 Input Image  Prediction  Error |
Test Image 3
 Input Image  Prediction 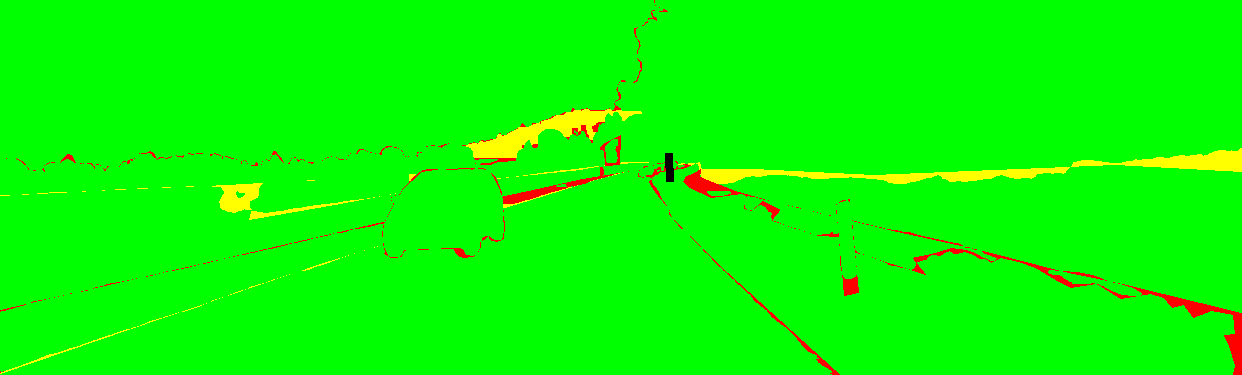 Error |
Test Image 4
 Input Image  Prediction  Error |
Test Image 5
 Input Image  Prediction  Error |
Test Image 6
 Input Image  Prediction  Error |
Test Image 7
 Input Image  Prediction  Error |
Test Image 8
 Input Image  Prediction  Error |
Test Image 9
 Input Image  Prediction  Error |