The depth completion and depth prediction evaluation are related to our work published in Sparsity Invariant CNNs (THREEDV 2017). It contains over 93 thousand depth maps with
corresponding raw LiDaR scans and RGB images, aligned with the "raw data" of the KITTI dataset. Given the large amount of training data, this
dataset shall allow a training of complex deep learning models for the tasks of depth completion and single image depth prediction. Also, we provide
manually selected images with unpublished depth maps to serve as a benchmark for those two challenging tasks.
The structure of all provided depth maps is aligned with the structure of our raw data to easily find corresponding left and right images,
or other provided information.
Note: On 12.04.2018 we have fixed a small error in the file data_depth_velodyne.zip, please download this file again if you have an old version.
All methods providing less than 100 % density have been interpolated using simple background interpolation as explained in the corresponding header file in the development kit.
Our evaluation table ranks all methods according to square root of the scale invariant logarithmic error (SILog).
However, we also provide other metrics:
SILog: Scale invariant logarithmic error [log(m)*100] (for more info click on the formula below)
sqErrorRel: Relative squared error (percent)
absErrorRel: Relative absolute error (percent)
iRMSE: Root mean squared error of the inverse depth [1/km]
Important Policy Update: As more and more non-published work and re-implementations of existing work is submitted to KITTI, we have established a new policy: from now on, only submissions with significant novelty that are leading to a peer-reviewed paper in a conference or journal are allowed. Minor modifications of existing algorithms or student research projects are not allowed. Such work must be evaluated on a split of the training set. To ensure that our policy is adopted, new users must detail their status, describe their work and specify the targeted venue during registration. Furthermore, we will regularly delete all entries that are 6 months old but are still anonymous or do not have a paper associated with them. For conferences, 6 month is enough to determine if a paper has been accepted and to add the bibliography information. For longer review cycles, you need to resubmit your results.
Additional information used by the methods
Additional training data: Use of additional data sources for training (see details)
SYNTHIA Dataset: SYNTHIA is a collection of photo-realistic frames rendered from a virtual city and comes with precise pixel-level semantic annotations as well as pixel-wise depth information. The dataset consists of +200,000 HD images from video streams and +20,000 HD images from independent snapshots.
Middlebury Stereo Evaluation: The classic stereo evaluation benchmark, featuring four test images in version 2 of the benchmark, with very accurate ground truth from a structured light system. 38 image pairs are provided in total.
Make3D Range Image Data: Images with small-resolution ground truth used to learn and evaluate depth from single monocular images.
Virtual KITTI Dataset: Virtual KITTI contains 50 high-resolution monocular videos (21,260 frames) generated from five different virtual worlds in urban settings under different imaging and weather conditions.
Scene Flow Dataset: The Freiburg Scene Flow Dataset collection has been used to train convolutional networks for disparity, optical flow, and scene flow estimation. The collection contains more than 39000 stereo frames in 960x540 pixel resolution, rendered from various synthetic sequences.
Citation
When using this dataset in your research, we will be happy if you cite us:
@inproceedings{Uhrig2017THREEDV,
author = {Jonas Uhrig and Nick Schneider and Lukas Schneider and Uwe Franke and Thomas Brox and Andreas Geiger},
title = {Sparsity Invariant CNNs}, booktitle = {International Conference on 3D Vision (3DV)},
year = {2017}
}




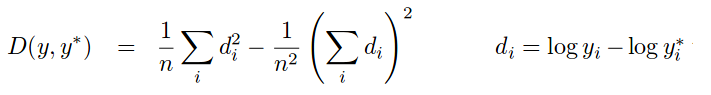
 Additional training data: Use of additional data sources for training (see details)
Additional training data: Use of additional data sources for training (see details)