2026
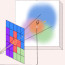
ConeGS: Error–Guided Densification Using Pixel Cones for Improved Reconstruction with Fewer Primitives (oral)
B. Baranowski, S. Esposito, P. Gschoßmann, A. Chen and A. Geiger
International Conference on 3D Vision (3DV), 2026
B. Baranowski, S. Esposito, P. Gschoßmann, A. Chen and A. Geiger
International Conference on 3D Vision (3DV), 2026
Abstract: 3D Gaussian Splatting (3DGS) achieves state-of-the-art image quality and real-time performance in novel view synthesis but often suffers from a suboptimal spatial distribution of primitives. This issue stems from cloning-based densification, which propagates Gaussians along existing geometry, limiting exploration and requiring many primitives to adequately cover the scene. We present ConeGS, an image-space-informed densification framework that is independent of existing scene geometry state. ConeGS first creates a fast Instant Neural Graphics Primitives (iNGP) reconstruction as a geometric proxy to estimate per-pixel depth. During the subsequent 3DGS optimization, it identifies high-error pixels and inserts new Gaussians along the corresponding viewing cones at the predicted depth values, initializing their size according to the cone diameter. A pre-activation opacity penalty rapidly removes redundant Gaussians, while a primitive budgeting strategy controls the total number of primitives, either by a fixed budget or by adapting to scene complexity, ensuring high reconstruction quality. Experiments show that ConeGS consistently enhances reconstruction quality and rendering performance across Gaussian budgets, with especially strong gains under tight primitive constraints where efficient placement is crucial.
Latex Bibtex Citation:
@inproceedings{Baranowski2026THREEDV,
author = {Bartłomiej Baranowski and Stefano Esposito and Patricia Gschoßmann and Anpei Chen and Andreas Geiger},
title = {ConeGS: Error–Guided Densification Using Pixel Cones for Improved Reconstruction with Fewer Primitives},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2026}
}
Latex Bibtex Citation:
@inproceedings{Baranowski2026THREEDV,
author = {Bartłomiej Baranowski and Stefano Esposito and Patricia Gschoßmann and Anpei Chen and Andreas Geiger},
title = {ConeGS: Error–Guided Densification Using Pixel Cones for Improved Reconstruction with Fewer Primitives},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2026}
}
2025

Transforming Science with Large Language Models: A Survey on AI-assisted Scientific Discovery, Experimentation, ...
S. Eger, Y. Cao, J. D'Souza, A. Geiger, C. Greisinger, S. Gross, Y. Hou, B. Krenn, A. Lauscher, Y. Li, et al.
Arxiv, 2025
S. Eger, Y. Cao, J. D'Souza, A. Geiger, C. Greisinger, S. Gross, Y. Hou, B. Krenn, A. Lauscher, Y. Li, et al.
Arxiv, 2025
Abstract: With the advent of large multimodal language models, science is now at a threshold of an AI-based technological transformation. Recently, a plethora of new AI models and tools has been proposed, promising to empower researchers and academics worldwide to conduct their research more effectively and efficiently. This includes all aspects of the research cycle, especially (1) searching for relevant literature; (2) generating research ideas and conducting experimentation; generating (3) text-based and (4) multimodal content (e.g., scientific figures and diagrams); and (5) AI-based automatic peer review. In this survey, we provide an in-depth overview over these exciting recent developments, which promise to fundamentally alter the scientific research process for good. Our survey covers the five aspects outlined above, indicating relevant datasets, methods and results (including evaluation) as well as limitations and scope for future research. Ethical concerns regarding shortcomings of these tools and potential for misuse (fake science, plagiarism, harms to research integrity) take a particularly prominent place in our discussion. We hope that our survey will not only become a reference guide for newcomers to the field but also a catalyst for new AI-based initiatives in the area of "AI4Science".
Latex Bibtex Citation:
@article{Eger2025ARXIV,
author = {Steffen Eger and Yong Cao and Jennifer D'Souza and Andreas Geiger and Christian Greisinger and Stephanie Gross and Yufang Hou and Brigitte Krenn and Anne Lauscher and Yizhi Li and Chenghua Lin and Nafise Sadat Moosavi and Wei Zhao and Tristan Miller},
title = {Transforming Science with Large Language Models: A Survey on AI-assisted Scientific Discovery, Experimentation, Content Generation, and Evaluation},
journal = {Arxiv},
year = {2025}
}
Latex Bibtex Citation:
@article{Eger2025ARXIV,
author = {Steffen Eger and Yong Cao and Jennifer D'Souza and Andreas Geiger and Christian Greisinger and Stephanie Gross and Yufang Hou and Brigitte Krenn and Anne Lauscher and Yizhi Li and Chenghua Lin and Nafise Sadat Moosavi and Wei Zhao and Tristan Miller},
title = {Transforming Science with Large Language Models: A Survey on AI-assisted Scientific Discovery, Experimentation, Content Generation, and Evaluation},
journal = {Arxiv},
year = {2025}
}

ReSim: Reliable World Simulation for Autonomous Driving
J. Yang, K. Chitta, S. Gao, L. Chen, Y. Shao, X. Jia, H. Li, A. Geiger, X. Yue and L. Chen
Advances in Neural Information Processing Systems (NeurIPS), 2025
J. Yang, K. Chitta, S. Gao, L. Chen, Y. Shao, X. Jia, H. Li, A. Geiger, X. Yue and L. Chen
Advances in Neural Information Processing Systems (NeurIPS), 2025
Abstract: How can we reliably simulate future driving scenarios under a wide range of ego driving behaviors? Recent driving world models, developed exclusively on real-world driving data composed mainly of safe expert trajectories, struggle to follow hazardous or non-expert behaviors, which are rare in such data. This limitation restricts their applicability to tasks such as policy evaluation. In this work, we address this challenge by enriching real-world human demonstrations with diverse non-expert data collected from a driving simulator (e.g., CARLA), and building a controllable world model trained on this heterogeneous corpus. Starting with a video generator featuring a diffusion transformer architecture, we devise several strategies to effectively integrate conditioning signals and improve prediction controllability and fidelity. The resulting model, ReSim, enables Reliable Simulation of diverse open-world driving scenarios under various actions, including hazardous non-expert ones. To close the gap between high-fidelity simulation and applications that require reward signals to judge different actions, we introduce a Video2Reward module that estimates a reward from ReSim's simulated future. Our ReSim paradigm achieves up to 44% higher visual fidelity, improves controllability for both expert and non-expert actions by over 50%, and boosts planning and policy selection performance on NAVSIM by 2% and 25%, respectively.
Latex Bibtex Citation:
@inproceedings{Yang2025NEURIPS,
author = {Jiazhi Yang and Kashyap Chitta and Shenyuan Gao and Long Chen and Yuqian Shao and Xiaosong Jia and Hongyang Li and Andreas Geiger and Xiangyu Yue and Li Chen},
title = {ReSim: Reliable World Simulation for Autonomous Driving},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2025}
}
Latex Bibtex Citation:
@inproceedings{Yang2025NEURIPS,
author = {Jiazhi Yang and Kashyap Chitta and Shenyuan Gao and Long Chen and Yuqian Shao and Xiaosong Jia and Hongyang Li and Andreas Geiger and Xiangyu Yue and Li Chen},
title = {ReSim: Reliable World Simulation for Autonomous Driving},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2025}
}

PanopticNeRF-360: Panoramic 3D-to-2D Label Transfer in Urban Scenes
X. Fu, S. Zhang, T. Chen, Y. Lu, X. Zhou, A. Geiger and Y. Liao
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
X. Fu, S. Zhang, T. Chen, Y. Lu, X. Zhou, A. Geiger and Y. Liao
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
Abstract: Training perception systems for self-driving cars requires substantial 2D annotations that are labor-intensive to manual label. While existing datasets provide rich annotations on pre-recorded sequences, they fall short in labeling rarely encountered viewpoints, potentially hampering the generalization ability for perception models. In this paper, we present PanopticNeRF-360, a novel approach that combines coarse 3D annotations with noisy 2D semantic cues to generate high-quality panoptic labels and images from any viewpoint. Our key insight lies in exploiting the complementarity of 3D and 2D priors to mutually enhance geometry and semantics. Specifically, we propose to leverage coarse 3D bounding primitives and noisy 2D semantic and instance predictions to guide geometry optimization, by encouraging predicted labels to match panoptic pseudo ground truth. Simultaneously, the improved geometry assists
in filtering 3D&2D annotation noise by fusing semantics in 3D space via a learned semantic field. To further enhance appearance, we combine MLP and hash grids to yield hybrid scene features, striking a balance between high-frequency appearance and contiguous semantics. Our experiments demonstrate PanopticNeRF-360’s state-of-the-art performance over label transfer methods on the challenging urban scenes of the KITTI-360 dataset. Moreover, PanopticNeRF-360 enables omnidirectional rendering of high-fidelity, multi-view and spatiotemporally consistent appearance, semantic and instance labels.
Latex Bibtex Citation:
@article{Fu2025PAMI,
author = {Xiao Fu and Shangzhan Zhang and Tianrun Chen and Yichong Lu and Xiaowei Zhou and Andreas Geiger and Yiyi Liao},
title = {PanopticNeRF-360: Panoramic 3D-to-2D Label Transfer in Urban Scenes},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2025}
}
Latex Bibtex Citation:
@article{Fu2025PAMI,
author = {Xiao Fu and Shangzhan Zhang and Tianrun Chen and Yichong Lu and Xiaowei Zhou and Andreas Geiger and Yiyi Liao},
title = {PanopticNeRF-360: Panoramic 3D-to-2D Label Transfer in Urban Scenes},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2025}
}

Easi3R: Estimating Disentangled Motion from DUSt3R Without Training
X. Chen, Y. Chen, Y. Xiu, A. Geiger and A. Chen
International Conference on Computer Vision (ICCV), 2025
X. Chen, Y. Chen, Y. Xiu, A. Geiger and A. Chen
International Conference on Computer Vision (ICCV), 2025
Abstract: Recent advances in DUSt3R have enabled robust estimation of dense point clouds and camera parameters of static scenes, leveraging Transformer network architectures and direct supervision on large-scale 3D datasets. In contrast, the limited scale and diversity of available 4D datasets present a major bottleneck for training a highly generalizable 4D model. This constraint has driven conventional 4D methods to fine-tune 3D models on scalable dynamic video data with additional geometric priors such as optical flow and depths. In this work, we take an opposite path and introduce Easi3R, a simple yet efficient training-free method for 4D reconstruction. Our approach applies attention adaptation during inference, eliminating the need for from-scratch pre-training or network fine-tuning. We find that the attention layers in DUSt3R inherently encode rich information about camera and object motion. By carefully disentangling these attention maps, we achieve accurate dynamic region segmentation, camera pose estimation, and 4D dense point map reconstruction. Extensive experiments on real-world dynamic videos demonstrate that our lightweight attention adaptation significantly outperforms previous state-of-the-art methods that are trained or finetuned on extensive dynamic datasets.
Latex Bibtex Citation:
@inproceedings{Chen2025ICCV,
author = {Xingyu Chen and Yue Chen and Yuliang Xiu and Andreas Geiger and Anpei Chen},
title = {Easi3R: Estimating Disentangled Motion from DUSt3R Without Training},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2025}
}
Latex Bibtex Citation:
@inproceedings{Chen2025ICCV,
author = {Xingyu Chen and Yue Chen and Yuliang Xiu and Andreas Geiger and Anpei Chen},
title = {Easi3R: Estimating Disentangled Motion from DUSt3R Without Training},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2025}
}

LoftUp: Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models (oral)
H. Huang, A. Chen, V. Havrylov, A. Geiger and D. Zhang
International Conference on Computer Vision (ICCV), 2025
H. Huang, A. Chen, V. Havrylov, A. Geiger and D. Zhang
International Conference on Computer Vision (ICCV), 2025
Abstract: Vision foundation models (VFMs) such as DINOv2 and CLIP have achieved impressive results on various downstream tasks, but their limited feature resolution hampers performance in applications requiring pixel-level understanding. Feature upsampling offers a promising direction to address this challenge. In this work, we identify two critical factors for enhancing feature upsampling: the upsampler architecture and the training objective. For the upsampler architecture, we introduce a coordinate-based cross-attention transformer that integrates the high-resolution images with coordinates and low-resolution VFM features to generate sharp, high-quality features. For the training objective, we propose constructing high-resolution pseudo-groundtruth features by leveraging class-agnostic masks and self-distillation. Our approach effectively captures fine-grained details and adapts flexibly to various input and feature resolutions. Through experiments, we demonstrate that our approach significantly outperforms existing feature upsampling techniques across various downstream tasks.
Latex Bibtex Citation:
@inproceedings{Huang2025ICCV,
author = {Haiwen Huang and Anpei Chen and Volodymyr Havrylov and Andreas Geiger and Dan Zhang},
title = {LoftUp: Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2025}
}
Latex Bibtex Citation:
@inproceedings{Huang2025ICCV,
author = {Haiwen Huang and Anpei Chen and Volodymyr Havrylov and Andreas Geiger and Dan Zhang},
title = {LoftUp: Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2025}
}

MoGA: 3D Generative Avatar Prior for Monocular Gaussian Avatar Reconstruction (highlight)
Z. Dong, L. Duan, J. Song, M. Black and A. Geiger
International Conference on Computer Vision (ICCV), 2025
Z. Dong, L. Duan, J. Song, M. Black and A. Geiger
International Conference on Computer Vision (ICCV), 2025
Abstract: We present MoGA, a novel method to reconstruct high-fidelity 3D Gaussian avatars from a single-view image. The main challenge lies in inferring unseen appearance and geometric details while ensuring 3D consistency and realism. Most previous methods rely on 2D diffusion models to synthesize unseen views; however, these generated views are sparse and inconsistent, resulting in unrealistic 3D artifacts and blurred appearance. To address these limitations, we leverage a generative avatar model, that can generate diverse 3D avatars by sampling deformed Gaussians from a learned prior distribution. Due to the limited amount of 3D training data, such a 3D model alone cannot capture all image details of unseen identities. Consequently, we integrate it as a prior, ensuring 3D consistency by projecting input images into its latent space and enforcing additional 3D appearance and geometric constraints. Our novel approach formulates Gaussian avatar creation as model inversion by fitting the generative avatar to synthetic views from 2D diffusion models. The generative avatar provides a meaningful initialization for model fitting, enforces 3D regularization, and helps in refining pose estimation. Experiments show that our method surpasses state-of-the-art techniques and generalizes well to real-world scenarios. Our Gaussian avatars are also inherently animatable.
Latex Bibtex Citation:
@inproceedings{Dong2025ICCV,
author = {Zijian Dong and Longteng Duan and Jie Song and Michael J. Black and Andreas Geiger},
title = {MoGA: 3D Generative Avatar Prior for Monocular Gaussian Avatar Reconstruction},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2025}
}
Latex Bibtex Citation:
@inproceedings{Dong2025ICCV,
author = {Zijian Dong and Longteng Duan and Jie Song and Michael J. Black and Andreas Geiger},
title = {MoGA: 3D Generative Avatar Prior for Monocular Gaussian Avatar Reconstruction},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2025}
}

CaRL: Learning Scalable Planning Policies with Simple Rewards
B. Jaeger, D. Dauner, J. Beißwenger, S. Gerstenecker, K. Chitta and A. Geiger
Conference on Robot Learning (CoRL), 2025
B. Jaeger, D. Dauner, J. Beißwenger, S. Gerstenecker, K. Chitta and A. Geiger
Conference on Robot Learning (CoRL), 2025
Abstract: We investigate reinforcement learning (RL) for privileged planning in autonomous driving. State-of-the-art approaches for this task are rule-based, but these methods do not scale to the long tail. RL, on the other hand, is scalable and does not suffer from compounding errors like imitation learning. Contemporary RL approaches for driving use complex shaped rewards that sum multiple individual rewards, e.g.\ progress, position, or orientation rewards. We show that PPO fails to optimize a popular version of these rewards when the mini-batch size is increased, which limits the scalability of these approaches. Instead, we propose a new reward design based primarily on optimizing a single intuitive reward term: route completion. Infractions are penalized by terminating the episode or multiplicatively reducing route completion. We find that PPO scales well with higher mini-batch sizes when trained with our simple reward, even improving performance. Training with large mini-batch sizes enables efficient scaling via distributed data parallelism. We scale PPO to 300M samples in CARLA and 500M samples in nuPlan with a single 8-GPU node. The resulting model achieves 64 DS on the CARLA longest6 v2 benchmark, outperforming other RL methods with more complex rewards by a large margin. Requiring only minimal adaptations from its use in CARLA, the same method is the best learning-based approach on nuPlan. It scores 91.3 in non-reactive and 90.6 in reactive traffic on the Val14 benchmark while being an order of magnitude faster than prior work.
Latex Bibtex Citation:
@inproceedings{Jaeger2025CORL,
author = {Bernhard Jaeger and Daniel Dauner and Jens Beißwenger and Simon Gerstenecker and Kashyap Chitta and Andreas Geiger},
title = {CaRL: Learning Scalable Planning Policies with Simple Rewards},
booktitle = {Conference on Robot Learning (CoRL)},
year = {2025}
}
Latex Bibtex Citation:
@inproceedings{Jaeger2025CORL,
author = {Bernhard Jaeger and Daniel Dauner and Jens Beißwenger and Simon Gerstenecker and Kashyap Chitta and Andreas Geiger},
title = {CaRL: Learning Scalable Planning Policies with Simple Rewards},
booktitle = {Conference on Robot Learning (CoRL)},
year = {2025}
}
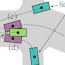
Pseudo-Simulation for Autonomous Driving
W. Cao, M. Hallgarten, T. Li, D. Dauner, X. Gu, C. Wang, Y. Miron, M. Aiello, H. Li, I. Gilitschenski, et al.
Conference on Robot Learning (CoRL), 2025
W. Cao, M. Hallgarten, T. Li, D. Dauner, X. Gu, C. Wang, Y. Miron, M. Aiello, H. Li, I. Gilitschenski, et al.
Conference on Robot Learning (CoRL), 2025
Abstract: Existing evaluation paradigms for Autonomous Vehicles (AVs) face critical limitations. Real-world evaluation is often challenging due to safety concerns and a lack of reproducibility, whereas closed-loop simulation can face insufficient realism or high computational costs. Open-loop evaluation, while being efficient and data-driven, relies on metrics that generally overlook compounding errors. In this paper, we propose pseudo-simulation, a novel paradigm that addresses these limitations. Pseudo-simulation operates on real datasets, similar to open-loop evaluation, but augments them with synthetic observations generated prior to evaluation using 3D Gaussian Splatting. Our key idea is to approximate potential future states the AV might encounter by generating a diverse set of observations that vary in position, heading, and speed. Our method then assigns a higher importance to synthetic observations that best match the AV’s likely behavior using a novel proximity-based weighting scheme. This enables evaluating error recovery and the mitigation of causal confusion, as in closed-loop benchmarks, without requiring sequential interactive simulation. We show that pseudo-simulation is better correlated with closed-loop simulations (R² = 0.8) than the best existing open-loop approach (R² = 0.7). We also establish a public leaderboard for the community to benchmark new methodologies with pseudo-simulation.
Latex Bibtex Citation:
@inproceedings{Cao2025CORL,
author = {Wei Cao and Marcel Hallgarten and Tianyu Li and Daniel Dauner and Xunjiang Gu and Caojun Wang and Yakov Miron and Marco Aiello and Hongyang Li and Igor Gilitschenski and Boris Ivanovic and Marco Pavone and Andreas Geiger and Kashyap Chitta},
title = {Pseudo-Simulation for Autonomous Driving},
booktitle = {Conference on Robot Learning (CoRL)},
year = {2025}
}
Latex Bibtex Citation:
@inproceedings{Cao2025CORL,
author = {Wei Cao and Marcel Hallgarten and Tianyu Li and Daniel Dauner and Xunjiang Gu and Caojun Wang and Yakov Miron and Marco Aiello and Hongyang Li and Igor Gilitschenski and Boris Ivanovic and Marco Pavone and Andreas Geiger and Kashyap Chitta},
title = {Pseudo-Simulation for Autonomous Driving},
booktitle = {Conference on Robot Learning (CoRL)},
year = {2025}
}

UrbanGen: Urban Generation with Compositional and Controllable Neural Fields
Y. Yang, Y. Shen, Y. Wang, A. Geiger and Y. Liao
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
Y. Yang, Y. Shen, Y. Wang, A. Geiger and Y. Liao
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
Abstract: Despite the rapid progress in generative radiance fields, most existing methods focus on object-centric applications and are not able to generate complex urban scenes. In this paper, we propose UrbanGen, a solution for the challenging task of generating urban radiance fields with photorealistic rendering, accurate geometry, high controllability, and diverse city styles. Our key idea is to leverage a coarse 3D panoptic prior, represented by a semantic voxel grid for stuff and bounding boxes for countable objects, to condition a compositional generative radiance field. This panoptic prior simplifies the task of learning complex urban geometry, enables disentanglement of stuff and objects, and provides versatile control over both. Moreover, by combining semantic and geometry losses with adversarial training, our method faithfully adheres to the input conditions, allowing for joint rendering of semantic and depth maps alongside RGB images. In addition, we collect a unified dataset with images and their panoptic priors in the same format from 3 diverse real-world datasets: KITTI-360, nuScenes, and Waymo, and train a city style-aware model on this data. Our systematic study shows that UrbanGen outperforms state-of-the-art generative radiance field baselines in terms of image fidelity and geometry accuracy for urban scene generation. Furthermore, UrbenGen brings a new set of controllability features, including large camera movements, stuff editing, and city style control.
Latex Bibtex Citation:
@article{Yang2025PAMI,
author = {Yuanbo Yang and Yujun Shen and Yue Wang and Andreas Geiger and Yiyi Liao},
title = {UrbanGen: Urban Generation with Compositional and Controllable Neural Fields},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2025}
}
Latex Bibtex Citation:
@article{Yang2025PAMI,
author = {Yuanbo Yang and Yujun Shen and Yue Wang and Andreas Geiger and Yiyi Liao},
title = {UrbanGen: Urban Generation with Compositional and Controllable Neural Fields},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2025}
}

Scholar Inbox: Personalized Paper Recommendations for Scientists
M. Flicke, G. Angrabeit, M. Iyengar, V. Protsenko, I. Shakun, J. Cicvaric, B. Kargi, H. He, L. Schuler, L. Scholz, et al.
Annual Meeting of the Association for Computational Linguistics (ACL), System Demonstrations, 2025
M. Flicke, G. Angrabeit, M. Iyengar, V. Protsenko, I. Shakun, J. Cicvaric, B. Kargi, H. He, L. Schuler, L. Scholz, et al.
Annual Meeting of the Association for Computational Linguistics (ACL), System Demonstrations, 2025
Abstract: Scholar Inbox is a new open-access platform designed to address the challenges researchers face in staying current with the rapidly expanding volume of scientific literature. We provide personalized recommendations, continuous updates from open-access archives (arXiv, bioRxiv, etc.), visual paper summaries, semantic search, and a range of tools to streamline research workflows and promote open research access. The platform's personalized recommendation system is trained on user ratings, ensuring that recommendations are tailored to individual researchers' interests. To further enhance the user experience, Scholar Inbox also offers a map of science that provides an overview of research across domains, enabling users to easily explore specific topics. We use this map to address the cold start problem common in recommender systems, as well as an active learning strategy that iteratively prompts users to rate a selection of papers, allowing the system to learn user preferences quickly. We evaluate the quality of our recommendation system on a novel dataset of 800k user ratings, which we make publicly available, as well as via an extensive user study. https://www.scholar-inbox.com/
Latex Bibtex Citation:
@inproceedings{Flicke2025ACLSDT,
author = {Markus Flicke and Glenn Angrabeit and Madhav Iyengar and Vitalii Protsenko and Illia Shakun and Jovan Cicvaric and Bora Kargi and Haoyu He and Lukas Schuler and Lewin Scholz and Kavyanjali Agnihotri and Yong Cao and Andreas Geiger},
title = {Scholar Inbox: Personalized Paper Recommendations for Scientists},
booktitle = {Annual Meeting of the Association for Computational Linguistics (ACL), System Demonstrations},
year = {2025}
}
Latex Bibtex Citation:
@inproceedings{Flicke2025ACLSDT,
author = {Markus Flicke and Glenn Angrabeit and Madhav Iyengar and Vitalii Protsenko and Illia Shakun and Jovan Cicvaric and Bora Kargi and Haoyu He and Lukas Schuler and Lewin Scholz and Kavyanjali Agnihotri and Yong Cao and Andreas Geiger},
title = {Scholar Inbox: Personalized Paper Recommendations for Scientists},
booktitle = {Annual Meeting of the Association for Computational Linguistics (ACL), System Demonstrations},
year = {2025}
}

Relightable Full-Body Gaussian Codec Avatars
S. Wang, T. Simon, I. Santesteban, T. Bagautdinov, J. Li, V. Agrawal, F. Prada, S. Yu, P. Nalbone, M. Gramlich, et al.
International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), 2025
S. Wang, T. Simon, I. Santesteban, T. Bagautdinov, J. Li, V. Agrawal, F. Prada, S. Yu, P. Nalbone, M. Gramlich, et al.
International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), 2025
Abstract: We propose Relightable Full-Body Gaussian Codec Avatars, a new approach for modeling relightable full-body avatars with fine-grained details including face and hands. The unique challenge for relighting full-body avatars lies in the large deformations caused by body articulation and the resulting impact on appearance caused by light transport. Changes in body pose can dramatically change the orientation of body surfaces with respect to lights, resulting in both local appearance changes due to changes in local light transport functions, as well as non-local changes due to occlusion between body parts. To address this, we decompose the light transport into local and non-local effects. Local appearance changes are modeled using learnable zonal harmonics for diffuse radiance transfer. Unlike spherical harmonics, zonal harmonics are highly efficient to rotate under articulation. This allows us to learn diffuse radiance transfer in a local coordinate frame, which disentangles the local radiance transfer from the articulation of the body. To account for non-local appearance changes, we introduce a shadow network that predicts shadows given precomputed incoming irradiance on a base mesh. This facilitates the learning of non-local shadowing between the body parts. Finally, we use a deferred shading approach to model specular radiance transfer and better capture reflections and highlights such as eye glints. We demonstrate that our approach successfully models both the local and non-local light transport required for relightable full-body avatars, with a superior generalization ability under novel illumination conditions and unseen poses.
Latex Bibtex Citation:
@inproceedings{Wang2025SIGGRAPH,
author = {Shaofei Wang and Tomas Simon and Igor Santesteban and Timur Bagautdinov and Junxuan Li and Vasu Agrawal and Fabian Prada and Shoou-I Yu and Pace Nalbone and Matt Gramlich and Roman Lubachersky and Chenglei Wu and Javier Romero and Jason Saragih and Michael Zollhoefer and Andreas Geiger and Siyu Tang and Shunsuke Saito},
title = {Relightable Full-Body Gaussian Codec Avatars},
booktitle = {International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH)},
year = {2025}
}
Latex Bibtex Citation:
@inproceedings{Wang2025SIGGRAPH,
author = {Shaofei Wang and Tomas Simon and Igor Santesteban and Timur Bagautdinov and Junxuan Li and Vasu Agrawal and Fabian Prada and Shoou-I Yu and Pace Nalbone and Matt Gramlich and Roman Lubachersky and Chenglei Wu and Javier Romero and Jason Saragih and Michael Zollhoefer and Andreas Geiger and Siyu Tang and Shunsuke Saito},
title = {Relightable Full-Body Gaussian Codec Avatars},
booktitle = {International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH)},
year = {2025}
}
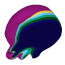
Volumetric Surfaces: Representing Fuzzy Geometries with Layered Meshes
S. Esposito, A. Chen, C. Reiser, S. Bulò, L. Porzi, K. Schwarz, C. Richardt, M. Zollhöfer, P. Kontschieder and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2025
S. Esposito, A. Chen, C. Reiser, S. Bulò, L. Porzi, K. Schwarz, C. Richardt, M. Zollhöfer, P. Kontschieder and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Abstract: High-quality view synthesis relies on volume rendering, splatting, or surface rendering. While surface rendering is typically the fastest, it struggles to accurately model fuzzy geometry like hair. In turn, alpha-blending techniques excel at representing fuzzy materials but require an unbounded number of samples per ray (P1). Further overheads are induced by empty space skipping in volume rendering (P2) and sorting input primitives in splatting (P3). We present a novel representation for real-time view synthesis where the (P1) number of sampling locations is small and bounded, (P2) sampling locations are efficiently found via rasterization, and (P3) rendering is sorting-free. We achieve this by representing objects as semi-transparent multi-layer meshes rendered in a fixed order. First, we model surface layers as signed distance function (SDF) shells with optimal spacing learned during training. Then, we bake them as meshes and fit UV textures. Unlike single-surface methods, our multi-layer representation effectively models fuzzy objects. In contrast to volume and splatting-based methods, our approach enables real-time rendering on low-power laptops and smartphones.
Latex Bibtex Citation:
@inproceedings{Esposito2025CVPR,
author = {Stefano Esposito and Anpei Chen and Christian Reiser and Samuel Rota Bulò and Lorenzo Porzi and Katja Schwarz and Christian Richardt and Michael Zollhöfer and Peter Kontschieder and Andreas Geiger},
title = {Volumetric Surfaces: Representing Fuzzy Geometries with Layered Meshes},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025}
}
Latex Bibtex Citation:
@inproceedings{Esposito2025CVPR,
author = {Stefano Esposito and Anpei Chen and Christian Reiser and Samuel Rota Bulò and Lorenzo Porzi and Katja Schwarz and Christian Richardt and Michael Zollhöfer and Peter Kontschieder and Andreas Geiger},
title = {Volumetric Surfaces: Representing Fuzzy Geometries with Layered Meshes},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025}
}

Prometheus: 3D-Aware Latent Diffusion Models for Feed-Forward Text-to-3D Scene Generation
Y. Yang, J. Shao, X. Li, Y. Shen, A. Geiger and Y. Liao
Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Y. Yang, J. Shao, X. Li, Y. Shen, A. Geiger and Y. Liao
Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Abstract: In this work, we introduce Prometheus, a 3D-aware latent diffusion model for text-to-3D generation at both object and scene levels in seconds. We formulate 3D scene generation as multi-view, feed-forward, pixel-aligned 3D Gaussian generation within the latent diffusion paradigm. To ensure generalizability, we build our model upon pre-trained text-to-image generation model with only minimal adjustments, and further train it using a large number of images from both single-view and multi-view datasets. Furthermore, we introduce an RGB-D latent space into 3D Gaussian generation to disentangle appearance and geometry information, enabling efficient feed-forward generation of 3D Gaussians with better fidelity and geometry. Extensive experimental results demonstrate the effectiveness of our method in both feed-forward 3D Gaussian reconstruction and text-to-3D generation. Project page: https://freemty.github.io/project-prometheus/.
Latex Bibtex Citation:
@inproceedings{Yang2025CVPR,
author = {Yuanbo Yang and Jiahao Shao and Xinyang Li and Yujun Shen and Andreas Geiger and Yiyi Liao},
title = {Prometheus: 3D-Aware Latent Diffusion Models for Feed-Forward Text-to-3D Scene Generation},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025}
}
Latex Bibtex Citation:
@inproceedings{Yang2025CVPR,
author = {Yuanbo Yang and Jiahao Shao and Xinyang Li and Yujun Shen and Andreas Geiger and Yiyi Liao},
title = {Prometheus: 3D-Aware Latent Diffusion Models for Feed-Forward Text-to-3D Scene Generation},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025}
}

GenFusion: Closing the Loop between Reconstruction and Generation via Videos
S. Wu, C. Xu, B. Huang, A. Geiger and A. Chen
Conference on Computer Vision and Pattern Recognition (CVPR), 2025
S. Wu, C. Xu, B. Huang, A. Geiger and A. Chen
Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Abstract: Recently, 3D reconstruction and generation have demonstrated impressive novel view synthesis results, achieving high fidelity and efficiency. However, a notable conditioning gap can be observed between these two fields, e.g., scalable 3D scene reconstruction often requires densely captured views, whereas 3D generation typically relies on a single or no input view, which significantly limits their applications. We found that the source of this phenomenon lies in the misalignment between 3D constraints and generative priors. To address this problem, we propose a reconstruction-driven video diffusion model that learns to condition video frames on artifact-prone RGB-D renderings. Moreover, we propose a cyclical fusion pipeline that iteratively adds restoration frames from the generative model to the training set, enabling progressive expansion and addressing the viewpoint saturation limitations seen in previous reconstruction and generation pipelines. Our evaluation, including view synthesis from sparse view and masked input, validates the effectiveness of our approach. More details at https://genfusion.sibowu.com.
Latex Bibtex Citation:
@inproceedings{Wu2025CVPR,
author = {Sibo Wu and Congrong Xu and Binbin Huang and Andreas Geiger and Anpei Chen},
title = {GenFusion: Closing the Loop between Reconstruction and Generation via Videos},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025}
}
Latex Bibtex Citation:
@inproceedings{Wu2025CVPR,
author = {Sibo Wu and Congrong Xu and Binbin Huang and Andreas Geiger and Anpei Chen},
title = {GenFusion: Closing the Loop between Reconstruction and Generation via Videos},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025}
}

DepthSplat: Connecting Gaussian Splatting and Depth
H. Xu, S. Peng, F. Wang, H. Blum, D. Barath, A. Geiger and M. Pollefeys
Conference on Computer Vision and Pattern Recognition (CVPR), 2025
H. Xu, S. Peng, F. Wang, H. Blum, D. Barath, A. Geiger and M. Pollefeys
Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Abstract: Gaussian splatting and single-view depth estimation are typically studied in isolation. In this paper, we present DepthSplat to connect Gaussian splatting and depth estimation and study their interactions. More specifically, we first contribute a robust multi-view depth model by leveraging pre-trained monocular depth features, leading to high-quality feed-forward 3D Gaussian splatting reconstructions. We also show that Gaussian splatting can serve as an unsupervised pre-training objective for learning powerful depth models from large-scale multi-view posed datasets. We validate the synergy between Gaussian splatting and depth estimation through extensive ablation and cross-task transfer experiments. Our DepthSplat achieves state-of-the-art performance on ScanNet, RealEstate10K and DL3DV datasets in terms of both depth estimation and novel view synthesis, demonstrating the mutual benefits of connecting both tasks. In addition, DepthSplat enables feed-forward reconstruction from 12 input views (512x960 resolutions) in 0.6 seconds.
Latex Bibtex Citation:
@inproceedings{Xu2025CVPR,
author = {Haofei Xu and Songyou Peng and Fangjinhua Wang and Hermann Blum and Daniel Barath and Andreas Geiger and Marc Pollefeys},
title = {DepthSplat: Connecting Gaussian Splatting and Depth},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025}
}
Latex Bibtex Citation:
@inproceedings{Xu2025CVPR,
author = {Haofei Xu and Songyou Peng and Fangjinhua Wang and Hermann Blum and Daniel Barath and Andreas Geiger and Marc Pollefeys},
title = {DepthSplat: Connecting Gaussian Splatting and Depth},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025}
}

EVolSplat: Efficient Volume-based Gaussian Splatting for Urban View Synthesis
S. Miao, J. Huang, D. Bai, X. Yan, H. Zhou, Y. Wang, B. Liu, A. Geiger and Y. Liao
Conference on Computer Vision and Pattern Recognition (CVPR), 2025
S. Miao, J. Huang, D. Bai, X. Yan, H. Zhou, Y. Wang, B. Liu, A. Geiger and Y. Liao
Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Abstract: Novel view synthesis of urban scenes is essential for autonomous driving-related applications.Existing NeRF and 3DGS-based methods show promising results in achieving photorealistic renderings but require slow, per-scene optimization. We introduce EVolSplat, an efficient 3D Gaussian Splatting model for urban scenes that works in a feed-forward manner. Unlike existing feed-forward, pixel-aligned 3DGS methods, which often suffer from issues like multi-view inconsistencies and duplicated content, our approach predicts 3D Gaussians across multiple frames within a unified volume using a 3D convolutional network. This is achieved by initializing 3D Gaussians with noisy depth predictions, and then refining their geometric properties in 3D space and predicting color based on 2D textures. Our model also handles distant views and the sky with a flexible hemisphere background model. This enables us to perform fast, feed-forward reconstruction while achieving real-time rendering. Experimental evaluations on the KITTI-360 and Waymo datasets show that our method achieves state-of-the-art quality compared to existing feed-forward 3DGS- and NeRF-based methods.
Latex Bibtex Citation:
@inproceedings{Miao2025CVPR,
author = {Sheng Miao and Jiaxin Huang and Dongfeng Bai and Xu Yan and Hongyu Zhou and Yue Wang and Bingbing Liu and Andreas Geiger and Yiyi Liao},
title = {EVolSplat: Efficient Volume-based Gaussian Splatting for Urban View Synthesis},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025}
}
Latex Bibtex Citation:
@inproceedings{Miao2025CVPR,
author = {Sheng Miao and Jiaxin Huang and Dongfeng Bai and Xu Yan and Hongyu Zhou and Yue Wang and Bingbing Liu and Andreas Geiger and Yiyi Liao},
title = {EVolSplat: Efficient Volume-based Gaussian Splatting for Urban View Synthesis},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025}
}
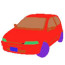
UrbanCAD: Towards Highly Controllable and Photorealistic 3D Vehicles for Urban Scene Simulation
Y. Lu, Y. Cai, S. Zhang, H. Zhou, H. Hu, H. Yu, A. Geiger and Y. Liao
Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Y. Lu, Y. Cai, S. Zhang, H. Zhou, H. Hu, H. Yu, A. Geiger and Y. Liao
Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Abstract: Photorealistic 3D vehicle models with high controllability are essential for autonomous driving simulation and data augmentation. While handcrafted CAD models provide flexible controllability, free CAD libraries often lack the high-quality materials necessary for photorealistic rendering. Conversely, reconstructed 3D models offer high-fidelity rendering but lack controllability. In this work, we introduce UrbanCAD, a framework that generates highly controllable and photorealistic 3D vehicle digital twins from a single urban image, leveraging a large collection of free 3D CAD models and handcrafted materials. To achieve this, we propose a novel pipeline that follows a retrieval-optimization manner, adapting to observational data while preserving fine-grained expert-designed priors for both geometry and material. This enables vehicles' realistic 360-degree rendering, background insertion, material transfer, relighting, and component manipulation. Furthermore, given multi-view background perspective and fisheye images, we approximate environment lighting using fisheye images and reconstruct the background with 3DGS, enabling the photorealistic insertion of optimized CAD models into rendered novel view backgrounds. Experimental results demonstrate that UrbanCAD outperforms baselines in terms of photorealism. Additionally, we show that various perception models maintain their accuracy when evaluated on UrbanCAD with in-distribution configurations but degrade when applied to realistic out-of-distribution data generated by our method. This suggests that UrbanCAD is a significant advancement in creating photorealistic, safety-critical driving scenarios for downstream applications.
Latex Bibtex Citation:
@inproceedings{Lu2025CVPR,
author = {Yichong Lu and Yichi Cai and Shangzhan Zhang and Hongyu Zhou and Haoji Hu and Huimin Yu and Andreas Geiger and Yiyi Liao},
title = {UrbanCAD: Towards Highly Controllable and Photorealistic 3D Vehicles for Urban Scene Simulation},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025}
}
Latex Bibtex Citation:
@inproceedings{Lu2025CVPR,
author = {Yichong Lu and Yichi Cai and Shangzhan Zhang and Hongyu Zhou and Haoji Hu and Huimin Yu and Andreas Geiger and Yiyi Liao},
title = {UrbanCAD: Towards Highly Controllable and Photorealistic 3D Vehicles for Urban Scene Simulation},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025}
}
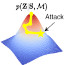
EMPERROR: A Flexible Generative Perception Error Model for Probing Self-Driving Planners
N. Hanselmann, S. Doll, M. Cordts, H. Lensch and A. Geiger
Robotics and Automation Letters (RA-L), 2025
N. Hanselmann, S. Doll, M. Cordts, H. Lensch and A. Geiger
Robotics and Automation Letters (RA-L), 2025
Abstract: To handle the complexities of real-world traffic, learning planners for self-driving from data is a promising direction. While recent approaches have shown great progress, they typically assume a setting in which the ground-truth world state is available as input. However, when deployed, planning needs to be robust to the long-tail of errors incurred by a noisy perception system, which is often neglected in evaluation. To address this, previous work has proposed drawing adversarial samples from a perception error model (PEM) mimicking the noise characteristics of a target object detector. However, these methods use simple PEMs that fail to accurately capture all failure modes of detection. In this paper, we present EMPERROR, a novel transformer-based generative PEM, apply it to stress-test an imitation learning (IL)-based planner and show that it imitates modern detectors more faithfully than previous work. Furthermore, it is able to produce realistic noisy inputs that increase the planner's collision rate by up to 85%, demonstrating its utility as a valuable tool for a more complete evaluation of self-driving planners.
Latex Bibtex Citation:
@article{Hanselmann2025RAL,
author = {Niklas Hanselmann and Simon Doll and Marius Cordts and Hendrik P. A. Lensch and Andreas Geiger},
title = {EMPERROR: A Flexible Generative Perception Error Model for Probing Self-Driving Planners},
journal = {Robotics and Automation Letters (RA-L)},
year = {2025}
}
Latex Bibtex Citation:
@article{Hanselmann2025RAL,
author = {Niklas Hanselmann and Simon Doll and Marius Cordts and Hendrik P. A. Lensch and Andreas Geiger},
title = {EMPERROR: A Flexible Generative Perception Error Model for Probing Self-Driving Planners},
journal = {Robotics and Automation Letters (RA-L)},
year = {2025}
}

Is Single-View Mesh Reconstruction Ready for Robotics?
F. Nolte, A. Geiger, B. Schölkopf and I. Posner
Arxiv, 2025
F. Nolte, A. Geiger, B. Schölkopf and I. Posner
Arxiv, 2025
Abstract: This paper evaluates single-view mesh reconstruction models for their potential in enabling instant digital twin creation for real-time planning and dynamics prediction using physics simulators for robotic manipulation. Recent single-view 3D reconstruction advances offer a promising avenue toward an automated real-to-sim pipeline: directly mapping a single observation of a scene into a simulation instance by reconstructing scene objects as individual, complete, and physically plausible 3D meshes. However, their suitability for physics simulations and robotics applications under immediacy, physical fidelity, and simulation readiness remains underexplored. We establish robotics-specific benchmarking criteria for 3D reconstruction, including handling typical inputs, collision-free and stable geometry, occlusions robustness, and meeting computational constraints. Our empirical evaluation using realistic robotics datasets shows that despite success on computer vision benchmarks, existing approaches fail to meet robotics-specific requirements. We quantitively examine limitations of single-view reconstruction for practical robotics implementation, in contrast to prior work that focuses on multi-view approaches. Our findings highlight critical gaps between computer vision advances and robotics needs, guiding future research at this intersection.
Latex Bibtex Citation:
@article{Nolte2025ARXIV,
author = {Frederik Nolte and Andreas Geiger and Bernhard Schölkopf and Ingmar Posner},
title = {Is Single-View Mesh Reconstruction Ready for Robotics?},
journal = {Arxiv},
year = {2025}
}
Latex Bibtex Citation:
@article{Nolte2025ARXIV,
author = {Frederik Nolte and Andreas Geiger and Bernhard Schölkopf and Ingmar Posner},
title = {Is Single-View Mesh Reconstruction Ready for Robotics?},
journal = {Arxiv},
year = {2025}
}

Artificial Kuramoto Oscillatory Neurons (oral)
T. Miyato, S. Löwe, A. Geiger and M. Welling
International Conference on Learning Representations (ICLR), 2025
T. Miyato, S. Löwe, A. Geiger and M. Welling
International Conference on Learning Representations (ICLR), 2025
Abstract: It has long been known in both neuroscience and AI that ``binding'' between neurons leads to a form of competitive learning where representations are compressed in order to represent more abstract concepts in deeper layers of the network. More recently, it was also hypothesized that dynamic (spatiotemporal) representations play an important role in both neuroscience and AI. Building on these ideas, we introduce Artificial Kuramoto Oscillatory Neurons (AKOrN) as a dynamical alternative to threshold units, which can be combined with arbitrary connectivity designs such as fully connected, convolutional, or attentive mechanisms. Our generalized Kuramoto updates bind neurons together through their synchronization dynamics. We show that this idea provides performance improvements across a wide spectrum of tasks such as unsupervised object discovery, adversarial robustness, calibrated uncertainty quantification, and reasoning. We believe that these empirical results show the importance of rethinking our assumptions at the most basic neuronal level of neural representation, and in particular show the importance of dynamical representations.
Latex Bibtex Citation:
@inproceedings{Miyato2025ICLR,
author = {Takeru Miyato and Sindy Löwe and Andreas Geiger and Max Welling},
title = {Artificial Kuramoto Oscillatory Neurons},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2025}
}
Latex Bibtex Citation:
@inproceedings{Miyato2025ICLR,
author = {Takeru Miyato and Sindy Löwe and Andreas Geiger and Max Welling},
title = {Artificial Kuramoto Oscillatory Neurons},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2025}
}

Unimotion: Unifying 3D Human Motion Synthesis and Understanding (oral)
C. Li, J. Chibane, Y. He, N. Pearl, A. Geiger and G. Pons-Moll
International Conference on 3D Vision (3DV), 2025
C. Li, J. Chibane, Y. He, N. Pearl, A. Geiger and G. Pons-Moll
International Conference on 3D Vision (3DV), 2025
Abstract: We introduce Unimotion, the first unified multi-task human motion model capable of both flexible motion control and frame-level motion understanding. While existing works control avatar motion with global text conditioning, or with fine-grained per frame scripts, none can do both at once. In addition, none of the existing works can output frame-level text paired with the generated poses. In contrast, Unimotion allows to control motion with global text, or local frame-level text, or both at once, providing more flexible control for users. Importantly, Unimotion is the first model which by design outputs local text paired with the generated poses, allowing users to know what motion happens and when, which is necessary for a wide range of applications. We show Unimotion opens up new applications: 1.) Hierarchical control, allowing users to specify motion at different levels of detail, 2.) Obtaining motion text descriptions for existing MoCap data or YouTube videos 3.) Allowing for editability, generating motion from text, and editing the motion via text edits. Moreover, Unimotion attains state-of-the-art results for the frame-level text-to-motion task on the established HumanML3D dataset.
Latex Bibtex Citation:
@inproceedings{Li2025THREEDV,
author = {Chuqiao Li and Julian Chibane and Yannan He and Naama Pearl and Andreas Geiger and Gerard Pons-Moll},
title = {Unimotion: Unifying 3D Human Motion Synthesis and Understanding},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2025}
}
Latex Bibtex Citation:
@inproceedings{Li2025THREEDV,
author = {Chuqiao Li and Julian Chibane and Yannan He and Naama Pearl and Andreas Geiger and Gerard Pons-Moll},
title = {Unimotion: Unifying 3D Human Motion Synthesis and Understanding},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2025}
}
2024

Renovating Names in Open-Vocabulary Segmentation Benchmarks
H. Huang, S. Peng, D. Zhang and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2024
H. Huang, S. Peng, D. Zhang and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2024
Abstract: Names are essential to both human cognition and vision-language models. Open-vocabulary models utilize class names as text prompts to generalize to categories unseen during training. However, the precision of these names is often overlooked in existing datasets. In this paper, we address this underexplored problem by presenting a framework for "renovating" names in open-vocabulary segmentation benchmarks (RENOVATE). Our framework features a renaming model that enhances the quality of names for each visual segment. Through experiments, we demonstrate that our renovated names help train stronger open-vocabulary models with up to 15% relative improvement and significantly enhance training efficiency with improved data quality. We also show that our renovated names improve evaluation by better measuring misclassification and enabling fine-grained model analysis. We will provide our code and relabelings for several popular segmentation datasets (MS COCO, ADE20K, Cityscapes) to the research community.
Latex Bibtex Citation:
@inproceedings{Huang2024NEURIPS,
author = {Haiwen Huang and Songyou Peng and Dan Zhang and Andreas Geiger},
title = {Renovating Names in Open-Vocabulary Segmentation Benchmarks},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Huang2024NEURIPS,
author = {Haiwen Huang and Songyou Peng and Dan Zhang and Andreas Geiger},
title = {Renovating Names in Open-Vocabulary Segmentation Benchmarks},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2024}
}
Vista: A Generalizable Driving World Model with High Fidelity and Versatile Controllability
S. Gao, J. Yang, L. Chen, K. Chitta, Y. Qiu, A. Geiger, J. Zhang and H. Li
Advances in Neural Information Processing Systems (NeurIPS), 2024
S. Gao, J. Yang, L. Chen, K. Chitta, Y. Qiu, A. Geiger, J. Zhang and H. Li
Advances in Neural Information Processing Systems (NeurIPS), 2024
Abstract: World models can foresee the outcomes of different actions, which is of paramount importance for autonomous driving. Nevertheless, existing driving world models still have limitations in generalization to unseen environments, prediction fidelity of critical details, and action controllability for flexible application. In this paper, we present Vista, a generalizable driving world model with high fidelity and versatile controllability. Based on a systematic diagnosis of existing methods, we introduce several key ingredients to address these limitations. To accurately predict real-world dynamics at high resolution, we propose two novel losses to promote the learning of moving instances and structural information. We also devise an effective latent replacement approach to inject historical frames as priors for coherent long-horizon rollouts. For action controllability, we incorporate a versatile set of controls from high-level intentions (command, goal point) to low-level maneuvers (trajectory, angle, and speed) through an efficient learning strategy. After large-scale training, the capabilities of Vista can seamlessly generalize to different scenarios. Extensive experiments on multiple datasets show that Vista outperforms the most advanced general-purpose video generator in over 70% of comparisons and surpasses the best-performing driving world model by 55% in FID and 27% in FVD. Moreover, for the first time, we utilize the capacity of Vista itself to establish a generalizable reward for real-world action evaluation without accessing the ground truth actions.
Latex Bibtex Citation:
@inproceedings{Gao2024NEURIPS,
author = {Shenyuan Gao and Jiazhi Yang and Li Chen and Kashyap Chitta and Yihang Qiu and Andreas Geiger and Jun Zhang and Hongyang Li},
title = {Vista: A Generalizable Driving World Model with High Fidelity and Versatile Controllability},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Gao2024NEURIPS,
author = {Shenyuan Gao and Jiazhi Yang and Li Chen and Kashyap Chitta and Yihang Qiu and Andreas Geiger and Jun Zhang and Hongyang Li},
title = {Vista: A Generalizable Driving World Model with High Fidelity and Versatile Controllability},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2024}
}

NAVSIM: Data-Driven Non-Reactive Autonomous Vehicle Simulation and Benchmarking
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavone, et al.
Advances in Neural Information Processing Systems (NeurIPS), 2024
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavone, et al.
Advances in Neural Information Processing Systems (NeurIPS), 2024
Abstract: Benchmarking vision-based driving policies is challenging. On one hand, open-loop evaluation with real data is easy, but these results do not reflect closed-loop performance. On the other, closed-loop evaluation is possible in simulation, but is hard to scale due to its significant computational demands. Further, the simulators available today exhibit a large domain gap to real data. This has resulted in an inability to draw clear conclusions from the rapidly growing body of research on end-to-end autonomous driving. In this paper, we present NAVSIM, a middle ground between these evaluation paradigms, where we use large datasets in combination with a non-reactive simulator to enable large-scale real-world benchmarking. Specifically, we gather simulation-based metrics, such as progress and time to collision, by unrolling bird's eye view abstractions of the test scenes for a short simulation horizon. Our simulation is non-reactive, i.e., the evaluated policy and environment do not influence each other. As we demonstrate empirically, this decoupling allows open-loop metric computation while being better aligned with closed-loop evaluations than traditional displacement errors. NAVSIM enabled a new competition held at CVPR 2024, where 143 teams submitted 463 entries, resulting in several new insights. On a large set of challenging scenarios, we observe that simple methods with moderate compute requirements such as TransFuser can match recent large-scale end-to-end driving architectures such as UniAD. Our modular framework can potentially be extended with new datasets, data curation strategies, and metrics, and will be continually maintained to host future challenges.
Latex Bibtex Citation:
@inproceedings{Dauner2024NEURIPS,
author = {Daniel Dauner and Marcel Hallgarten and Tianyu Li and Xinshuo Weng and Zhiyu Huang and Zetong Yang and Hongyang Li and Igor Gilitschenski and Boris Ivanovic and Marco Pavone and Andreas Geiger and Kashyap Chitta},
title = {NAVSIM: Data-Driven Non-Reactive Autonomous Vehicle Simulation and Benchmarking},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Dauner2024NEURIPS,
author = {Daniel Dauner and Marcel Hallgarten and Tianyu Li and Xinshuo Weng and Zhiyu Huang and Zetong Yang and Hongyang Li and Igor Gilitschenski and Boris Ivanovic and Marco Pavone and Andreas Geiger and Kashyap Chitta},
title = {NAVSIM: Data-Driven Non-Reactive Autonomous Vehicle Simulation and Benchmarking},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2024}
}

Gaussian Opacity Fields: Efficient Adaptive Surface Reconstruction in Unbounded Scenes
Z. Yu, T. Sattler and A. Geiger
Conference and Exhibition on Computer Graphics and Interactive Techniques in Asia (SIGGRAPH ASIA), 2024
Z. Yu, T. Sattler and A. Geiger
Conference and Exhibition on Computer Graphics and Interactive Techniques in Asia (SIGGRAPH ASIA), 2024
Abstract: Recently, 3D Gaussian Splatting (3DGS) has demonstrated impressive novel view synthesis results, while allowing the rendering of high-resolution images in real-time. However, leveraging 3D Gaussians for surface reconstruction poses significant challenges due to the explicit and disconnected nature of 3D Gaussians. In this work, we present Gaussian Opacity Fields (GOF), a novel approach for efficient, high-quality, and adaptive surface reconstruction in unbounded scenes. Our GOF is derived from ray-tracing-based volume rendering of 3D Gaussians, enabling direct geometry extraction from 3D Gaussians by identifying its levelset, without resorting to Poisson reconstruction or TSDF fusion as in previous work. We approximate the surface normal of Gaussians as the normal of the ray-Gaussian intersection plane, enabling the application of regularization that significantly enhances geometry. Furthermore, we develop an efficient geometry extraction method utilizing Marching Tetrahedra, where the tetrahedral grids are induced from 3D Gaussians and thus adapt to the scene's complexity. Our evaluations reveal that GOF surpasses existing 3DGS-based methods in surface reconstruction and novel view synthesis. Further, it compares favorably to or even outperforms, neural implicit methods in both quality and speed.
Latex Bibtex Citation:
@inproceedings{Yu2024SIGGRAPHASIA,
author = {Zehao Yu and Torsten Sattler and Andreas Geiger},
title = {Gaussian Opacity Fields: Efficient Adaptive Surface Reconstruction in Unbounded Scenes},
booktitle = {Conference and Exhibition on Computer Graphics and Interactive Techniques in Asia (SIGGRAPH ASIA)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Yu2024SIGGRAPHASIA,
author = {Zehao Yu and Torsten Sattler and Andreas Geiger},
title = {Gaussian Opacity Fields: Efficient Adaptive Surface Reconstruction in Unbounded Scenes},
booktitle = {Conference and Exhibition on Computer Graphics and Interactive Techniques in Asia (SIGGRAPH ASIA)},
year = {2024}
}

An Invitation to Deep Reinforcement Learning
B. Jaeger and A. Geiger
Foundations and Trends in Optimization, 2024
B. Jaeger and A. Geiger
Foundations and Trends in Optimization, 2024
Abstract: Training a deep neural network to maximize a target objective has become the standard recipe for successful machine learning over the last decade. These networks can be optimized with supervised learning if the target objective is differentiable. However, this is not the case for many interesting problems. Common objectives like intersection over union (IoU), and bilingual evaluation understudy (BLEU) scores or rewards cannot be optimized with supervised learning. A common workaround is to define differentiable surrogate losses, leading to suboptimal solutions with respect to the actual objective. Reinforcement learning (RL) has emerged as a promising alternative for optimizing deep neural networks to maximize non-differentiable objectives in recent years. Examples include aligning large language models via human feedback, code generation, object detection or control problems. This makes RL techniques relevant to the larger machine learning audience. The subject is, however, timeintensive to approach due to the large range of methods, as well as the often highly theoretical presentation. This monograph takes an alternative approach that is different from classic RL textbooks. Rather than focusing on tabular problems, we introduce RL as a generalization of supervised learning, which we first apply to non-differentiable objectives and later to temporal problems. Assuming only basic knowledge of supervised learning, the reader will be able to understand state-of-the-art deep RL algorithms like proximal policy optimization (PPO) after reading this tutorial.
Latex Bibtex Citation:
@book{Jaeger2024,
author = {Bernhard Jaeger and Andreas Geiger},
title = {An Invitation to Deep Reinforcement Learning},
publisher = {Foundations and Trends in Optimization},
year = {2024}
}
Latex Bibtex Citation:
@book{Jaeger2024,
author = {Bernhard Jaeger and Andreas Geiger},
title = {An Invitation to Deep Reinforcement Learning},
publisher = {Foundations and Trends in Optimization},
year = {2024}
}
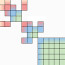
HDT: Hierarchical Document Transformer
H. He, M. Flicke, J. Buchmann, I. Gurevych and A. Geiger
Conference on Language Modeling (COLM), 2024
H. He, M. Flicke, J. Buchmann, I. Gurevych and A. Geiger
Conference on Language Modeling (COLM), 2024
Abstract: In this paper, we propose the Hierarchical Document Transformer (HDT), a novel sparse Transformer architecture tailored for structured hierarchical documents. Such documents are extremely important in numerous domains, including science, law or medicine. However, most existing solutions are inefficient and fail to make use of the structure inherent to documents. HDT exploits document structure by introducing auxiliary anchor tokens and redesigning the attention mechanism into a sparse multi-level hierarchy. This approach facilitates information exchange between tokens at different levels while maintaining sparsity, thereby enhancing computational and memory efficiency while exploiting the document structure as an inductive bias. We address the technical challenge of implementing HDT's sample-dependent hierarchical attention pattern by developing a novel sparse attention kernel that considers the hierarchical structure of documents. As demonstrated by our experiments, utilizing structural information present in documents leads to faster convergence, higher sample efficiency and better performance on downstream tasks.
Latex Bibtex Citation:
@inproceedings{He2024COLM,
author = {Haoyu He and Markus Flicke and Jan Buchmann and Iryna Gurevych and Andreas Geiger},
title = {HDT: Hierarchical Document Transformer},
booktitle = {Conference on Language Modeling (COLM)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{He2024COLM,
author = {Haoyu He and Markus Flicke and Jan Buchmann and Iryna Gurevych and Andreas Geiger},
title = {HDT: Hierarchical Document Transformer},
booktitle = {Conference on Language Modeling (COLM)},
year = {2024}
}

LISO: Lidar-only Self-Supervised 3D Object Detection
S. Baur, F. Moosmann and A. Geiger
European Conference on Computer Vision (ECCV), 2024
S. Baur, F. Moosmann and A. Geiger
European Conference on Computer Vision (ECCV), 2024
Abstract: 3D object detection is one of the most important components in any Self-Driving stack, but current state-of-the-art (SOTA) lidar object detectors require costly & slow manual annotation of 3D bounding boxes to perform well. Recently, several methods emerged to generate pseudo ground truth without human supervision, however, all of these methods have various drawbacks: Some methods require sensor rigs with full camera coverage and accurate calibration, partly supplemented by an auxiliary optical flow engine. Others require expensive high-precision localization to find objects that disappeared over multiple drives. We introduce a novel self-supervised method to train SOTA lidar object detection networks which works on unlabeled sequences of lidar point clouds only, which we call trajectory-regularized self-training. It utilizes a SOTA self-supervised lidar scene flow network under the hood to generate, track, and iteratively refine pseudo ground truth. We demonstrate the effectiveness of our approach for multiple SOTA object detection networks across multiple real-world datasets. Code will be released.
Latex Bibtex Citation:
@inproceedings{Baur2024ECCV,
author = {Stefan Baur and Frank Moosmann and Andreas Geiger},
title = {LISO: Lidar-only Self-Supervised 3D Object Detection},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Baur2024ECCV,
author = {Stefan Baur and Frank Moosmann and Andreas Geiger},
title = {LISO: Lidar-only Self-Supervised 3D Object Detection},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}

LaRa: Efficient Large-Baseline Radiance Fields
A. Chen, H. Xu, S. Esposito, S. Tang and A. Geiger
European Conference on Computer Vision (ECCV), 2024
A. Chen, H. Xu, S. Esposito, S. Tang and A. Geiger
European Conference on Computer Vision (ECCV), 2024
Abstract: Radiance field methods have achieved photorealistic novel view synthesis and geometry reconstruction. But they are mostly applied in per-scene optimization or small-baseline settings. While several recent works investigate feed-forward reconstruction with large baselines by utilizing transformers, they all operate with a standard global attention mechanism and hence ignore the local nature of 3D reconstruction. We propose a method that unifies local and global reasoning in transformer layers, resulting in improved quality and faster convergence. Our model represents scenes as Gaussian Volumes and combines this with an image encoder and Group Attention Layers for efficient feed-forward reconstruction. Experimental results demonstrate that our model, trained for two days on four GPUs, demonstrates high fidelity in reconstructing 360° radiance fields, and robustness to zero-shot and out-of-domain testing.
Latex Bibtex Citation:
@inproceedings{Chen2024ECCV,
author = {Anpei Chen and Haofei Xu and Stefano Esposito and Siyu Tang and Andreas Geiger},
title = {LaRa: Efficient Large-Baseline Radiance Fields},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Chen2024ECCV,
author = {Anpei Chen and Haofei Xu and Stefano Esposito and Siyu Tang and Andreas Geiger},
title = {LaRa: Efficient Large-Baseline Radiance Fields},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}
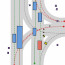
SLEDGE: Synthesizing Driving Environments with Generative Models and Rule-Based Traffic
K. Chitta, D. Dauner and A. Geiger
European Conference on Computer Vision (ECCV), 2024
K. Chitta, D. Dauner and A. Geiger
European Conference on Computer Vision (ECCV), 2024
Abstract: SLEDGE is the first generative simulator for vehicle motion planning trained on real-world driving logs. Its core component is a learned model that is able to generate agent bounding boxes and lane graphs. The model's outputs serve as an initial state for rule-based traffic simulation. The unique properties of the entities to be generated for SLEDGE, such as their connectivity and variable count per scene, render the naive application of most modern generative models to this task non-trivial. Therefore, together with a systematic study of existing lane graph representations, we introduce a novel raster-to-vector autoencoder. It encodes agents and the lane graph into distinct channels in a rasterized latent map. This facilitates both lane-conditioned agent generation and combined generation of lanes and agents with a Diffusion Transformer. Using generated entities in SLEDGE enables greater control over the simulation, e.g. upsampling turns or increasing traffic density. Further, SLEDGE can support 500m long routes, a capability not found in existing data-driven simulators like nuPlan. It presents new challenges for planning algorithms, evidenced by failure rates of over 40% for PDM, the winner of the 2023 nuPlan challenge, when tested on hard routes and dense traffic generated by our model. Compared to nuPlan, SLEDGE requires 500x less storage to set up (<4 GB), making it a more accessible option and helping with democratizing future research in this field.
Latex Bibtex Citation:
@inproceedings{Chitta2024ECCV,
author = {Kashyap Chitta and Daniel Dauner and Andreas Geiger},
title = {SLEDGE: Synthesizing Driving Environments with Generative Models and Rule-Based Traffic},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Chitta2024ECCV,
author = {Kashyap Chitta and Daniel Dauner and Andreas Geiger},
title = {SLEDGE: Synthesizing Driving Environments with Generative Models and Rule-Based Traffic},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}

Efficient Depth-Guided Urban View Synthesis
S. Miao, J. Huang, D. Bai, W. Qiu, B. Liu, A. Geiger and Y. Liao
European Conference on Computer Vision (ECCV), 2024
S. Miao, J. Huang, D. Bai, W. Qiu, B. Liu, A. Geiger and Y. Liao
European Conference on Computer Vision (ECCV), 2024
Abstract: Recent advances in implicit scene representation enable high-fidelity street view novel view synthesis. However, existing methods optimize a neural radiance field for each scene, relying heavily on dense training images and extensive computation resources. To mitigate this shortcoming, we introduce a new method called Efficient Depth-Guided Urban View Synthesis (EDUS) for fast feed-forward inference and efficient per-scene fine-tuning. Different from prior generalizable methods that infer geometry based on feature matching, EDUS leverages noisy predicted geometric priors as guidance to enable generalizable urban view synthesis from sparse input images. The geometric priors allow us to apply our generalizable model directly in the 3D space, gaining robustness across various sparsity levels. Through comprehensive experiments on the KITTI-360 and Waymo datasets, we demonstrate promising generalization abilities on novel street scenes. Moreover, our results indicate that EDUS achieves state-of-the-art performance in sparse view settings when combined with fast test-time optimization.
Latex Bibtex Citation:
@inproceedings{Miao2024ECCV,
author = {Sheng Miao and Jiaxin Huang and Dongfeng Bai and Weichao Qiu and Bingbing Liu and Andreas Geiger and Yiyi Liao},
title = {Efficient Depth-Guided Urban View Synthesis},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Miao2024ECCV,
author = {Sheng Miao and Jiaxin Huang and Dongfeng Bai and Weichao Qiu and Bingbing Liu and Andreas Geiger and Yiyi Liao},
title = {Efficient Depth-Guided Urban View Synthesis},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}

MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images (oral)
Y. Chen, H. Xu, C. Zheng, B. Zhuang, M. Pollefeys, A. Geiger, T. Cham and J. Cai
European Conference on Computer Vision (ECCV), 2024
Y. Chen, H. Xu, C. Zheng, B. Zhuang, M. Pollefeys, A. Geiger, T. Cham and J. Cai
European Conference on Computer Vision (ECCV), 2024
Abstract: We propose MVSplat, an efficient feed-forward 3D Gaussian Splatting model learned from sparse multi-view images. To accurately localize the Gaussian centers, we propose to build a cost volume representation via plane sweeping in the 3D space, where the cross-view feature similarities stored in the cost volume can provide valuable geometry cues to the estimation of depth. We learn the Gaussian primitives' opacities, covariances, and spherical harmonics coefficients jointly with the Gaussian centers while only relying on photometric supervision. We demonstrate the importance of the cost volume representation in learning feed-forward Gaussian Splatting models via extensive experimental evaluations. On the large-scale RealEstate10K and ACID benchmarks, our model achieves state-of-the-art performance with the fastest feed-forward inference speed (22 fps). Compared to the latest state-of-the-art method pixelSplat, our model uses 10x fewer parameters and infers more than 2x faster while providing higher appearance and geometry quality as well as better cross-dataset generalization.
Latex Bibtex Citation:
@inproceedings{Chen2024ECCVb,
author = {Yuedong Chen and Haofei Xu and Chuanxia Zheng and Bohan Zhuang and Marc Pollefeys and Andreas Geiger and Tat-Jen Cham and Jianfei Cai},
title = {MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Chen2024ECCVb,
author = {Yuedong Chen and Haofei Xu and Chuanxia Zheng and Bohan Zhuang and Marc Pollefeys and Andreas Geiger and Tat-Jen Cham and Jianfei Cai},
title = {MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}
DriveLM: Driving with Graph Visual Question Answering (oral)
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, P. Luo, A. Geiger and H. Li
European Conference on Computer Vision (ECCV), 2024
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, P. Luo, A. Geiger and H. Li
European Conference on Computer Vision (ECCV), 2024
Abstract: We study how vision-language models (VLMs) trained on web-scale data can be integrated into end-to-end driving systems to boost generalization and enable interactivity with human users. While recent approaches adapt VLMs to driving via single-round visual question answering (VQA), human drivers reason about decisions in multiple steps. Starting from the localization of key objects, humans estimate object interactions before taking actions. The key insight is that with our proposed task, Graph VQA, where we model graph-structured reasoning through perception, prediction and planning question-answer pairs, we obtain a suitable proxy task to mimic the human reasoning process. We instantiate datasets (DriveLM-Data) built upon nuScenes and CARLA, and propose a VLM-based baseline approach (DriveLM-Agent) for jointly performing Graph VQA and end-to-end driving. The experiments demonstrate that Graph VQA provides a simple, principled framework for reasoning about a driving scene, and DriveLM-Data provides a challenging benchmark for this task. Our DriveLM-Agent baseline performs end-to-end autonomous driving competitively in comparison to state-of-the-art driving-specific architectures. Notably, its benefits are pronounced when it is evaluated zero-shot on unseen objects or sensor configurations. We hope this work can be the starting point to shed new light on how to apply VLMs for autonomous driving. To facilitate future research, all code, data, and models are available to the public.
Latex Bibtex Citation:
@inproceedings{Sima2024ECCV,
author = {Chonghao Sima and Katrin Renz and Kashyap Chitta and Li Chen and Hanxue Zhang and Chengen Xie and Ping Luo and Andreas Geiger and Hongyang Li},
title = {DriveLM: Driving with Graph Visual Question Answering},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Sima2024ECCV,
author = {Chonghao Sima and Katrin Renz and Kashyap Chitta and Li Chen and Hanxue Zhang and Chengen Xie and Ping Luo and Andreas Geiger and Hongyang Li},
title = {DriveLM: Driving with Graph Visual Question Answering},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}

End-to-end Autonomous Driving: Challenges and Frontiers
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger and H. Li
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger and H. Li
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024
Abstract: The autonomous driving community has witnessed a rapid growth in approaches that embrace an end-to-end algorithm framework, utilizing raw sensor input to generate vehicle motion plans, instead of concentrating on individual tasks such as detection and motion prediction. End-to-end systems, in comparison to modular pipelines, benefit from joint feature optimization for perception and planning. This field has flourished due to the availability of large-scale datasets, closed-loop evaluation, and the increasing need for autonomous driving algorithms to perform effectively in challenging scenarios. In this survey, we provide a comprehensive analysis of more than 250 papers, covering the motivation, roadmap, methodology, challenges, and future trends in end-to-end autonomous driving. We delve into several critical challenges, including multi-modality, interpretability, causal confusion, robustness, and world models, amongst others. Additionally, we discuss current advancements in foundation models and visual pre-training, as well as how to incorporate these techniques within the end-to-end driving framework. To facilitate future research, we maintain an active repository that contains up-to-date links to relevant literature and open-source projects at https://github.com/OpenDriveLab/End-to-end-Autonomous-Driving.
Latex Bibtex Citation:
@article{Chen2024PAMI,
author = {Li Chen and Penghao Wu and Kashyap Chitta and Bernhard Jaeger and Andreas Geiger and Hongyang Li},
title = {End-to-end Autonomous Driving: Challenges and Frontiers},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2024}
}
Latex Bibtex Citation:
@article{Chen2024PAMI,
author = {Li Chen and Penghao Wu and Kashyap Chitta and Bernhard Jaeger and Andreas Geiger and Hongyang Li},
title = {End-to-end Autonomous Driving: Challenges and Frontiers},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2024}
}

Binary Opacity Grids: Capturing Fine Geometric Detail for Mesh-Based View Synthesis
C. Reiser, S. Garbin, P. Srinivasan, D. Verbin, R. Szeliski, B. Mildenhall, J. Barron, P. Hedman and A. Geiger
International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), 2024
C. Reiser, S. Garbin, P. Srinivasan, D. Verbin, R. Szeliski, B. Mildenhall, J. Barron, P. Hedman and A. Geiger
International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), 2024
Abstract: While surface-based view synthesis algorithms are appealing due to their low computational requirements, they often struggle to reproduce thin structures. In contrast, more expensive methods that model the scene's geometry as a volumetric density field (e.g. NeRF) excel at reconstructing fine geometric detail. However, density fields often represent geometry in a "fuzzy" manner, which hinders exact localization of the surface. In this work, we modify density fields to encourage them to converge towards surfaces, without compromising their ability to reconstruct thin structures. First, we employ a discrete opacity grid representation instead of a continuous density field, which allows opacity values to discontinuously transition from zero to one at the surface. Second, we anti-alias by casting multiple rays per pixel, which allows occlusion boundaries and subpixel structures to be modelled without using semi-transparent voxels. Third, we minimize the binary entropy of the opacity values, which facilitates the extraction of surface geometry by encouraging opacity values to binarize towards the end of training. Lastly, we develop a fusion-based meshing strategy followed by mesh simplification and appearance model fitting. The compact meshes produced by our model can be rendered in real-time on mobile devices and achieve significantly higher view synthesis quality compared to existing mesh-based approaches.
Latex Bibtex Citation:
@inproceedings{Reiser2024SIGGRAPH,
author = {Christian Reiser and Stephan Garbin and Pratul P. Srinivasan and Dor Verbin and Richard Szeliski and Ben Mildenhall and Jonathan T. Barron and Peter Hedman and Andreas Geiger},
title = {Binary Opacity Grids: Capturing Fine Geometric Detail for Mesh-Based View Synthesis},
booktitle = {International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Reiser2024SIGGRAPH,
author = {Christian Reiser and Stephan Garbin and Pratul P. Srinivasan and Dor Verbin and Richard Szeliski and Ben Mildenhall and Jonathan T. Barron and Peter Hedman and Andreas Geiger},
title = {Binary Opacity Grids: Capturing Fine Geometric Detail for Mesh-Based View Synthesis},
booktitle = {International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH)},
year = {2024}
}
2D Gaussian Splatting for Geometrically Accurate Radiance Fields
B. Huang, Z. Yu, A. Chen, A. Geiger and S. Gao
International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), 2024
B. Huang, Z. Yu, A. Chen, A. Geiger and S. Gao
International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), 2024
Abstract: 3D Gaussian Splatting (3DGS) has recently revolutionized radiance field reconstruction, achieving high quality novel view synthesis and fast rendering speed without baking. However, 3DGS fails to accurately represent surfaces due to the multi-view inconsistent nature of 3D Gaussians. We present 2D Gaussian Splatting (2DGS), a novel approach to model and reconstruct geometrically accurate radiance fields from multi-view images. Our key idea is to collapse the 3D volume into a set of 2D oriented planar Gaussian disks. Unlike 3D Gaussians, 2D Gaussians provide view-consistent geometry while modeling surfaces intrinsically. To accurately recover thin surfaces and achieve stable optimization, we introduce a perspective-correct 2D splatting process utilizing ray-splat intersection and rasterization. Additionally, we incorporate depth distortion and normal consistency terms to further enhance the quality of the reconstructions. We demonstrate that our differentiable renderer allows for noise-free and detailed geometry reconstruction while maintaining competitive appearance quality, fast training speed, and real-time rendering.
Latex Bibtex Citation:
@inproceedings{Huang2024SIGGRAPH,
author = {Binbin Huang and Zehao Yu and Anpei Chen and Andreas Geiger and Shenghua Gao},
title = {2D Gaussian Splatting for Geometrically Accurate Radiance Fields},
booktitle = {International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Huang2024SIGGRAPH,
author = {Binbin Huang and Zehao Yu and Anpei Chen and Andreas Geiger and Shenghua Gao},
title = {2D Gaussian Splatting for Geometrically Accurate Radiance Fields},
booktitle = {International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH)},
year = {2024}
}

MuRF: Multi-Baseline Radiance Fields
H. Xu, A. Chen, Y. Chen, C. Sakaridis, Y. Zhang, M. Pollefeys, A. Geiger and F. Yu
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
H. Xu, A. Chen, Y. Chen, C. Sakaridis, Y. Zhang, M. Pollefeys, A. Geiger and F. Yu
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Abstract: We present Multi-Baseline Radiance Fields (MuRF), a general feed-forward approach to solving sparse view synthesis under multiple different baseline settings (small and large baselines, and different number of input views). To render a target novel view, we discretize the 3D space into planes parallel to the target image plane, and accordingly construct a target view frustum volume. Such a target volume representation is spatially aligned with the target view, which effectively aggregates relevant information from the input views for high-quality rendering. It also facilitates subsequent radiance field regression with a convolutional network thanks to its axis-aligned nature. The 3D context modeled by the convolutional network enables our method to synthesis sharper scene structures than prior works. Our MuRF achieves state-of-the-art performance across multiple different baseline settings and diverse scenarios ranging from simple objects (DTU) to complex indoor and outdoor scenes (RealEstate10K and LLFF). We also show promising zero-shot generalization abilities on the Mip-NeRF 360 dataset, demonstrating the general applicability of MuRF.
Latex Bibtex Citation:
@inproceedings{Xu2024CVPR,
author = {Haofei Xu and Anpei Chen and Yuedong Chen and Christos Sakaridis and Yulun Zhang and Marc Pollefeys and Andreas Geiger and Fisher Yu},
title = {MuRF: Multi-Baseline Radiance Fields},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Xu2024CVPR,
author = {Haofei Xu and Anpei Chen and Yuedong Chen and Christos Sakaridis and Yulun Zhang and Marc Pollefeys and Andreas Geiger and Fisher Yu},
title = {MuRF: Multi-Baseline Radiance Fields},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}

3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting
Z. Qian, S. Wang, M. Mihajlovic, A. Geiger and S. Tang
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Z. Qian, S. Wang, M. Mihajlovic, A. Geiger and S. Tang
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Abstract: We introduce an approach that creates animatable human avatars from monocular videos using 3D Gaussian Splatting (3DGS). Existing methods based on neural radiance fields (NeRFs) achieve high-quality novel-view/novel-pose image synthesis but often require days of training, and are extremely slow at inference time. Recently, the community has explored fast grid structures for efficient training of clothed avatars. Albeit being extremely fast at training, these methods can barely achieve an interactive rendering frame rate with around 15 FPS. In this paper, we use 3D Gaussian Splatting and learn a non-rigid deformation network to reconstruct animatable clothed human avatars that can be trained within 30 minutes and rendered at real-time frame rates (50+ FPS). Given the explicit nature of our representation, we further introduce as-isometric-as-possible regularizations on both the Gaussian mean vectors and the covariance matrices, enhancing the generalization of our model on highly articulated unseen poses. Experimental results show that our method achieves comparable and even better performance compared to state-of-the-art approaches on animatable avatar creation from a monocular input, while being 400x and 250x faster in training and inference, respectively.
Latex Bibtex Citation:
@inproceedings{Qian2024CVPR,
author = {Zhiyin Qian and Shaofei Wang and Marko Mihajlovic and Andreas Geiger and Siyu Tang},
title = {3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Qian2024CVPR,
author = {Zhiyin Qian and Shaofei Wang and Marko Mihajlovic and Andreas Geiger and Siyu Tang},
title = {3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}

IntrinsicAvatar: Physically Based Inverse Rendering of Dynamic Humans from Monocular Videos via Explicit Ray ...
S. Wang, B. Antic, A. Geiger and S. Tang
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
S. Wang, B. Antic, A. Geiger and S. Tang
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Abstract: We present IntrinsicAvatar, a novel approach to recovering the intrinsic properties of clothed human avatars including geometry, albedo, material, and environment lighting from only monocular videos. Recent advancements in human-based neural rendering have enabled high-quality geometry and appearance reconstruction of clothed humans from just monocular videos. However, these methods bake intrinsic properties such as albedo, material, and environment lighting into a single entangled neural representation. On the other hand, only a handful of works tackle the problem of estimating geometry and disentangled appearance properties of clothed humans from monocular videos. They usually achieve limited quality and disentanglement due to approximations of secondary shading effects via learned MLPs. In this work, we propose to model secondary shading effects explicitly via Monte-Carlo ray tracing. We model the rendering process of clothed humans as a volumetric scattering process, and combine ray tracing with body articulation. Our approach can recover high-quality geometry, albedo, material, and lighting properties of clothed humans from a single monocular video, without requiring supervised pre-training using ground truth materials. Furthermore, since we explicitly model the volumetric scattering process and ray tracing, our model naturally generalizes to novel poses, enabling animation of the reconstructed avatar in novel lighting conditions.
Latex Bibtex Citation:
@inproceedings{Wang2024CVPR,
author = {Shaofei Wang and Bozidar Antic and Andreas Geiger and Siyu Tang},
title = {IntrinsicAvatar: Physically Based Inverse Rendering of Dynamic Humans from Monocular Videos via Explicit Ray Tracing},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Wang2024CVPR,
author = {Shaofei Wang and Bozidar Antic and Andreas Geiger and Siyu Tang},
title = {IntrinsicAvatar: Physically Based Inverse Rendering of Dynamic Humans from Monocular Videos via Explicit Ray Tracing},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}

Generalized Predictive Model for Autonomous Driving (highlight)
J. Yang, S. Gao, Y. Qiu, L. Chen, T. Li, B. Dai, K. Chitta, P. Wu, J. Zeng, P. Luo, et al.
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
J. Yang, S. Gao, Y. Qiu, L. Chen, T. Li, B. Dai, K. Chitta, P. Wu, J. Zeng, P. Luo, et al.
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Abstract: In this paper, we introduce the first large-scale video prediction model in the autonomous driving discipline. To eliminate the restriction of high-cost data collection and empower the generalization ability of our model, we acquire massive data from the web and pair it with diverse and high-quality text descriptions. The resultant dataset accumulates over 2000 hours of driving videos, spanning areas all over the world with diverse weather conditions and traffic scenarios. Inheriting the merits from recent latent diffusion models, our model, dubbed GenAD, handles the challenging dynamics in driving scenes with novel temporal reasoning blocks. We showcase that it can generalize to various unseen driving datasets in a zero-shot manner, surpassing general or driving-specific video prediction counterparts. Furthermore, GenAD can be adapted into an action-conditioned prediction model or a motion planner, holding great potential for real-world driving applications.
Latex Bibtex Citation:
@inproceedings{Yang2024CVPR,
author = {Jiazhi Yang and Shenyuan Gao and Yihang Qiu and Li Chen and Tianyu Li and Bo Dai and Kashyap Chitta and Penghao Wu and Jia Zeng and Ping Luo and Jun Zhang and Andreas Geiger and Yu Qiao and Hongyang Li},
title = {Generalized Predictive Model for Autonomous Driving},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Yang2024CVPR,
author = {Jiazhi Yang and Shenyuan Gao and Yihang Qiu and Li Chen and Tianyu Li and Bo Dai and Kashyap Chitta and Penghao Wu and Jia Zeng and Ping Luo and Jun Zhang and Andreas Geiger and Yu Qiao and Hongyang Li},
title = {Generalized Predictive Model for Autonomous Driving},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}

NeLF-Pro: Neural Light Field Probes for Multi-Scale Novel View Synthesis
Z. You, A. Geiger and A. Chen
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Z. You, A. Geiger and A. Chen
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Abstract: We present NeLF-Pro, a novel representation to model and reconstruct light fields in diverse natural scenes that vary in extent and spatial granularity. In contrast to previous fast reconstruction methods that represent the 3D scene globally, we model the light field of a scene as a set of local light field feature probes, parameterized with position and multi-channel 2D feature maps. Our central idea is to bake the scene's light field into spatially varying learnable representations and to query point features by weighted blending of probes close to the camera - allowing for mipmap representation and rendering. We introduce a novel vector-matrix-matrix (VMM) factorization technique that effectively represents the light field feature probes as products of core factors (i.e., VM) shared among local feature probes, and a basis factor (i.e., M) - efficiently encoding internal relationships and patterns within the scene. Experimentally, we demonstrate that NeLF-Pro significantly boosts the performance of feature grid-based representations, and achieves fast reconstruction with better rendering quality while maintaining compact modeling.
Latex Bibtex Citation:
@inproceedings{You2024CVPR,
author = {Zinuo You and Andreas Geiger and Anpei Chen},
title = {NeLF-Pro: Neural Light Field Probes for Multi-Scale Novel View Synthesis},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{You2024CVPR,
author = {Zinuo You and Andreas Geiger and Anpei Chen},
title = {NeLF-Pro: Neural Light Field Probes for Multi-Scale Novel View Synthesis},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}

GraphDreamer: Compositional 3D Scene Synthesis from Scene Graphs
G. Gao, W. Liu, A. Chen, A. Geiger and B. Schölkopf
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
G. Gao, W. Liu, A. Chen, A. Geiger and B. Schölkopf
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Abstract: As pretrained text-to-image diffusion models become increasingly powerful, recent efforts have been made to distill knowledge from these text-to-image pretrained models for optimizing a text-guided 3D model. Most of the existing methods generate a holistic 3D model from a plain text input. This can be problematic when the text describes a complex scene with multiple objects, because the vectorized text embeddings are inherently unable to capture a complex description with multiple entities and relationships. Holistic 3D modeling of the entire scene further prevents accurate grounding of text entities and concepts. To address this limitation, we propose GraphDreamer, a novel framework to generate compositional 3D scenes from scene graphs, where objects are represented as nodes and their interactions as edges. By exploiting node and edge information in scene graphs, our method makes better use of the pretrained text-to-image diffusion model and is able to fully disentangle different objects without image-level supervision. To facilitate modeling of object-wise relationships, we use signed distance fields as representation and impose a constraint to avoid inter-penetration of objects. To avoid manual scene graph creation, we design a text prompt for ChatGPT to generate scene graphs based on text inputs. We conduct both qualitative and quantitative experiments to validate the effectiveness of GraphDreamer in generating high-fidelity compositional 3D scenes with disentangled object entities.
Latex Bibtex Citation:
@inproceedings{Gao2024CVPR,
author = {Gege Gao and Weiyang Liu and Anpei Chen and Andreas Geiger and Bernhard Schölkopf},
title = {GraphDreamer: Compositional 3D Scene Synthesis from Scene Graphs},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Gao2024CVPR,
author = {Gege Gao and Weiyang Liu and Anpei Chen and Andreas Geiger and Bernhard Schölkopf},
title = {GraphDreamer: Compositional 3D Scene Synthesis from Scene Graphs},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}

HUGS: Holistic Urban 3D Scene Understanding via Gaussian Splatting
H. Zhou, J. Shao, L. Xu, D. Bai, W. Qiu, B. Liu, Y. Wang, A. Geiger and Y. Liao
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
H. Zhou, J. Shao, L. Xu, D. Bai, W. Qiu, B. Liu, Y. Wang, A. Geiger and Y. Liao
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Abstract: Holistic understanding of urban scenes based on RGB images is a challenging yet important problem. It encompasses understanding both the geometry and appearance to enable novel view synthesis, parsing semantic labels, and tracking moving objects. Despite considerable progress, existing approaches often focus on specific aspects of this task and require additional inputs such as LiDAR scans or manually annotated 3D bounding boxes. In this paper, we introduce a novel pipeline that utilizes 3D Gaussian Splatting for holistic urban scene understanding. Our main idea involves the joint optimization of geometry, appearance, semantics, and motion using a combination of static and dynamic 3D Gaussians, where moving object poses are regularized via physical constraints. Our approach offers the ability to render new viewpoints in real-time, yielding 2D and 3D semantic information with high accuracy, and reconstruct dynamic scenes, even in scenarios where 3D bounding box detection are highly noisy. Experimental results on KITTI, KITTI-360, and Virtual KITTI 2 demonstrate the effectiveness of our approach.
Latex Bibtex Citation:
@inproceedings{Zhou2024CVPR,
author = {Hongyu Zhou and Jiahao Shao and Lu Xu and Dongfeng Bai and Weichao Qiu and Bingbing Liu and Yue Wang and Andreas Geiger and Yiyi Liao},
title = {HUGS: Holistic Urban 3D Scene Understanding via Gaussian Splatting},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Zhou2024CVPR,
author = {Hongyu Zhou and Jiahao Shao and Lu Xu and Dongfeng Bai and Weichao Qiu and Bingbing Liu and Yue Wang and Andreas Geiger and Yiyi Liao},
title = {HUGS: Holistic Urban 3D Scene Understanding via Gaussian Splatting},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}

Mip-Splatting: Alias-free 3D Gaussian Splatting (oral, best student paper award)
Z. Yu, A. Chen, B. Huang, T. Sattler and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Z. Yu, A. Chen, B. Huang, T. Sattler and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Abstract: Recently, 3D Gaussian Splatting has demonstrated impressive novel view synthesis results, reaching high fidelity and efficiency. However, strong artifacts can be observed when changing the sampling rate, e.g., by changing focal length or camera distance. We find that the source for this phenomenon can be attributed to the lack of 3D frequency constraints and the usage of a 2D dilation filter. To address this problem, we introduce a 3D smoothing filter which constrains the size of the 3D Gaussian primitives based on the maximal sampling frequency induced by the input views, eliminating high-frequency artifacts when zooming in. Moreover, replacing 2D dilation with a 2D Mip filter, which simulates a 2D box filter, effectively mitigates aliasing and dilation issues. Our evaluation, including scenarios such a training on single-scale images and testing on multiple scales, validates the effectiveness of our approach.
Latex Bibtex Citation:
@inproceedings{Yu2024CVPR,
author = {Zehao Yu and Anpei Chen and Binbin Huang and Torsten Sattler and Andreas Geiger},
title = {Mip-Splatting: Alias-free 3D Gaussian Splatting},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Yu2024CVPR,
author = {Zehao Yu and Anpei Chen and Binbin Huang and Torsten Sattler and Andreas Geiger},
title = {Mip-Splatting: Alias-free 3D Gaussian Splatting},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}

WildFusion: Learning 3D-Aware Latent Diffusion Models in View Space
K. Schwarz, S. Kim, J. Gao, S. Fidler, A. Geiger and K. Kreis
International Conference on Learning Representations (ICLR), 2024
K. Schwarz, S. Kim, J. Gao, S. Fidler, A. Geiger and K. Kreis
International Conference on Learning Representations (ICLR), 2024
Abstract: Modern learning-based approaches to 3D-aware image synthesis achieve high photorealism and 3D-consistent viewpoint changes for the generated images. Existing approaches represent instances in a shared canonical space. However, for in-the-wild datasets a shared canonical system can be difficult to define or might not even exist. In this work, we instead model instances in view space, alleviating the need for posed images and learned camera distributions. We find that in this setting, existing GAN-based methods are prone to generating flat geometry and struggle with distribution coverage. We hence propose WildFusion, a new approach to 3D-aware image synthesis based on latent diffusion models (LDMs). We first train an autoencoder that infers a compressed latent representation, which additionally captures the images’ underlying 3D structure and enables not only reconstruction but also novel view synthesis. To learn a faithful 3D representation, we leverage cues from monocular depth prediction. Then, we train a diffusion model in the 3D-aware latent space, thereby enabling synthesis of high-quality 3D-consistent image samples, outperforming recent state-of-the-art GAN-based methods. Importantly, our 3D-aware LDM is trained without any direct supervision from multiview images or 3D geometry and does not require posed images or learned pose or camera distributions. It directly learns a 3D representation without relying on canonical camera coordinates. This opens up promising research avenues for scalable 3D-aware image synthesis and 3D content creation from in-the-wild image data.
Latex Bibtex Citation:
@inproceedings{Schwarz2024ICLR,
author = {Katja Schwarz and Seung Wook Kim and Jun Gao and Sanja Fidler and Andreas Geiger and Karsten Kreis},
title = {WildFusion: Learning 3D-Aware Latent Diffusion Models in View Space},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Schwarz2024ICLR,
author = {Katja Schwarz and Seung Wook Kim and Jun Gao and Sanja Fidler and Andreas Geiger and Karsten Kreis},
title = {WildFusion: Learning 3D-Aware Latent Diffusion Models in View Space},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2024}
}

Geometric Transform Attention
T. Miyato, B. Jaeger, M. Welling and A. Geiger
International Conference on Learning Representations (ICLR), 2024
T. Miyato, B. Jaeger, M. Welling and A. Geiger
International Conference on Learning Representations (ICLR), 2024
Abstract: As transformers are equivariant to the permutation of input tokens, encoding the positional information of tokens is necessary for many tasks. However, since existing positional encoding schemes have been initially designed for NLP tasks, their suitability for vision tasks, which typically exhibit different structural properties in their data, is questionable. We argue that existing positional encoding schemes are suboptimal for 3D vision tasks, as they do not respect their underlying 3D geometric structure. Based on this hypothesis, we propose a geometry-aware attention mechanism that encodes the geometric structure of tokens as relative transformation determined by the geometric relationship between queries and key-value pairs. By evaluating on multiple novel view synthesis (NVS) datasets in the sparse wide-baseline multi-view setting, we show that our attention, called Geometric Transform Attention (GTA), improves learning efficiency and performance of state-of-the-art transformer-based NVS models without any additional learned parameters and only minor computational overhead.
Latex Bibtex Citation:
@inproceedings{Miyato2024ICLR,
author = {Takeru Miyato and Bernhard Jaeger and Max Welling and Andreas Geiger},
title = {Geometric Transform Attention},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Miyato2024ICLR,
author = {Takeru Miyato and Bernhard Jaeger and Max Welling and Andreas Geiger},
title = {Geometric Transform Attention},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2024}
}

Efficient End-to-End Detection of 6-DoF Grasps for Robotic Bin Picking
Y. Liu, A. Qualmann, Z. Yu, M. Gabriel, P. Schillinger, M. Spies, N. Vien and A. Geiger
International Conference on Robotics and Automation (ICRA), 2024
Y. Liu, A. Qualmann, Z. Yu, M. Gabriel, P. Schillinger, M. Spies, N. Vien and A. Geiger
International Conference on Robotics and Automation (ICRA), 2024
Abstract: Bin picking is an important building block for many robotic systems, in logistics, production or in household use-cases. In recent years, machine learning methods for the prediction of 6-DoF grasps on diverse and unknown objects have shown promising progress. However, existing approaches only consider a single ground truth grasp orientation at a grasp location during training and therefore can only predict limited grasp orientations which leads to a reduced number of feasible grasps in bin picking with restricted reachability. In this paper, we propose a novel approach for learning dense and diverse 6-DoF grasps for parallel-jaw grippers in robotic bin picking. We introduce a parameterized grasp distribution model based on Power-Spherical distributions that enables a training based on all possible ground truth samples. Thereby, we also consider the grasp uncertainty enhancing the model’s robustness to noisy inputs. As a result, given a single top-down view depth image, our model can generate diverse grasps with multiple collision-free grasp orientations. Experimental evaluations in simulation and on a real robotic bin picking setup demonstrate the model’s ability to generalize across various object categories achieving an object clearing rate of around 90% in simulation and real-world experiments. We also outperform state of the art approaches. Moreover, the proposed approach exhibits its usability in real robot experiments without any refinement steps, even when only trained on a synthetic dataset, due to the probabilistic grasp distribution modeling.
Latex Bibtex Citation:
@inproceedings{Liu2024ICRA,
author = {Yushi Liu and Alexander Qualmann and Zehao Yu and Miroslav Gabriel and Philipp Schillinger and Markus Spies and Ngo Anh Vien and Andreas Geiger},
title = {Efficient End-to-End Detection of 6-DoF Grasps for Robotic Bin Picking},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Liu2024ICRA,
author = {Yushi Liu and Alexander Qualmann and Zehao Yu and Miroslav Gabriel and Philipp Schillinger and Markus Spies and Ngo Anh Vien and Andreas Geiger},
title = {Efficient End-to-End Detection of 6-DoF Grasps for Robotic Bin Picking},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2024}
}

NICER-SLAM: Neural Implicit Scene Encoding for RGB SLAM (oral, best paper runner up award)
Z. Zhu, S. Peng, V. Larsson, Z. Cui, M. Oswald, A. Geiger and M. Pollefeys
International Conference on 3D Vision (3DV), 2024
Z. Zhu, S. Peng, V. Larsson, Z. Cui, M. Oswald, A. Geiger and M. Pollefeys
International Conference on 3D Vision (3DV), 2024
Abstract: Neural implicit representations have recently become popular in simultaneous localization and mapping (SLAM), especially in dense visual SLAM. However, existing works either rely on RGB-D sensors or require a separate monocular SLAM approach for camera tracking, and fail to produce high-fidelity 3D dense reconstructions. To address these shortcomings, we present NICER-SLAM, a dense RGB SLAM system that simultaneously optimizes for camera poses and a hierarchical neural implicit map representation, which also allows for high-quality novel view synthesis. To facilitate the optimization process for mapping, we integrate additional supervision signals including easy-to-obtain monocular geometric cues and optical flow, and also introduce a simple warping loss to further enforce geometric consistency. Moreover, to further boost performance in complex large-scale scenes, we also propose a local adaptive transformation from signed distance functions (SDFs) to density in the volume rendering equation. On multiple challenging indoor and outdoor datasets, NICER-SLAM demonstrates strong performance in dense mapping, novel view synthesis, and tracking, even competitive with recent RGB-D SLAM systems. Project page: https://nicer-slam.github.io/.
Latex Bibtex Citation:
@inproceedings{Zhu2024THREEDV,
author = {Zihan Zhu and Songyou Peng and Viktor Larsson and Zhaopeng Cui and Martin R. Oswald and Andreas Geiger and Marc Pollefeys},
title = {NICER-SLAM: Neural Implicit Scene Encoding for RGB SLAM},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2024}
}
Latex Bibtex Citation:
@inproceedings{Zhu2024THREEDV,
author = {Zihan Zhu and Songyou Peng and Viktor Larsson and Zhaopeng Cui and Martin R. Oswald and Andreas Geiger and Marc Pollefeys},
title = {NICER-SLAM: Neural Implicit Scene Encoding for RGB SLAM},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2024}
}
2023

Parting with Misconceptions about Learning-based Vehicle Motion Planning
D. Dauner, M. Hallgarten, A. Geiger and K. Chitta
Conference on Robot Learning (CoRL), 2023
D. Dauner, M. Hallgarten, A. Geiger and K. Chitta
Conference on Robot Learning (CoRL), 2023
Abstract: The release of nuPlan marks a new era in vehicle motion planning research, offering the first large-scale real-world dataset and evaluation schemes requiring both precise short-term planning and long-horizon ego-forecasting. Existing systems struggle to simultaneously meet both requirements. Indeed, we find that these tasks are fundamentally misaligned and should be addressed independently. We further assess the current state of closed-loop planning in the field, revealing the limitations of learning-based methods in complex real-world scenarios and the value of simple rule-based priors such as centerline selection through lane graph search algorithms. More surprisingly, for the open-loop sub-task, we observe that the best results are achieved when using only this centerline as scene context (ie, ignoring all information regarding the map and other agents). Combining these insights, we propose an extremely simple and efficient planner which outperforms an extensive set of competitors, winning the nuPlan planning challenge 2023.
Latex Bibtex Citation:
@inproceedings{Dauner2023CORL,
author = {Daniel Dauner and Marcel Hallgarten and Andreas Geiger and Kashyap Chitta},
title = {Parting with Misconceptions about Learning-based Vehicle Motion Planning},
booktitle = {Conference on Robot Learning (CoRL)},
year = {2023}
}
Latex Bibtex Citation:
@inproceedings{Dauner2023CORL,
author = {Daniel Dauner and Marcel Hallgarten and Andreas Geiger and Kashyap Chitta},
title = {Parting with Misconceptions about Learning-based Vehicle Motion Planning},
booktitle = {Conference on Robot Learning (CoRL)},
year = {2023}
}

AG3D: Learning to Generate 3D Avatars from 2D Image Collections
Z. Dong, X. Chen, J. Yang, M. Black, O. Hilliges and A. Geiger
International Conference on Computer Vision (ICCV), 2023
Z. Dong, X. Chen, J. Yang, M. Black, O. Hilliges and A. Geiger
International Conference on Computer Vision (ICCV), 2023
Abstract: While progress in 2D generative models of human appearance has been rapid, many applications require 3D avatars that can be animated and rendered. Unfortunately, most existing methods for learning generative models of 3D humans with diverse shape and appearance require 3D training data, which is limited and expensive to acquire. The key to progress is hence to learn generative models of 3D avatars from abundant unstructured 2D image collections. However, learning realistic and complete 3D appearance and geometry in this under-constrained setting remains challenging, especially in the presence of loose clothing such as dresses. In this paper, we propose a new adversarial generative model of realistic 3D people from 2D images. Our method captures shape and deformation of the body and loose clothing by adopting a holistic 3D generator and integrating an efficient and flexible articulation module. To improve realism, we train our model using multiple discriminators while also integrating geometric cues in the form of predicted 2D normal maps. We experimentally find that our method outperforms previous 3D- and articulation-aware methods in terms of geometry and appearance. We validate the effectiveness of our model and the importance of each component via systematic ablation studies.
Latex Bibtex Citation:
@inproceedings{Dong2023ICCV,
author = {Zijian Dong and Xu Chen and Jinlong Yang and Michael Black and Otmar Hilliges and Andreas Geiger},
title = {AG3D: Learning to Generate 3D Avatars from 2D Image Collections},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2023}
}
Latex Bibtex Citation:
@inproceedings{Dong2023ICCV,
author = {Zijian Dong and Xu Chen and Jinlong Yang and Michael Black and Otmar Hilliges and Andreas Geiger},
title = {AG3D: Learning to Generate 3D Avatars from 2D Image Collections},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2023}
}

Hidden Biases of End-to-End Driving Models
B. Jaeger, K. Chitta and A. Geiger
International Conference on Computer Vision (ICCV), 2023
B. Jaeger, K. Chitta and A. Geiger
International Conference on Computer Vision (ICCV), 2023
Abstract: End-to-end driving systems have recently made rapid progress, in particular on CARLA. Independent of their major contribution, they introduce changes to minor system components. Consequently, the source of improvements is unclear. We identify two biases that recur in nearly all state-of-the-art methods and are critical for the observed progress on CARLA: (1) lateral recovery via a strong inductive bias towards target point following, and (2) longitudinal averaging of multimodal waypoint predictions for slowing down. We investigate the drawbacks of these biases and identify principled alternatives. By incorporating our insights, we develop TF++, a simple end-to-end method that ranks first on the Longest6 and LAV benchmarks, gaining 11 driving score over the best prior work on Longest6.
Latex Bibtex Citation:
@inproceedings{Jaeger2023ICCV,
author = {Bernhard Jaeger and Kashyap Chitta and Andreas Geiger},
title = {Hidden Biases of End-to-End Driving Models},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2023}
}
Latex Bibtex Citation:
@inproceedings{Jaeger2023ICCV,
author = {Bernhard Jaeger and Kashyap Chitta and Andreas Geiger},
title = {Hidden Biases of End-to-End Driving Models},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2023}
}

Towards Scalable Multi-View Reconstruction of Geometry and Materials
C. Schmitt, B. Antic, A. Neculai, J. Lee and A. Geiger
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
C. Schmitt, B. Antic, A. Neculai, J. Lee and A. Geiger
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
Abstract: In this paper, we propose a novel method for joint recovery of camera pose, object geometry and spatially-varying Bidirectional Reflectance Distribution Function (svBRDF) of 3D scenes that exceed object-scale and hence cannot be captured with stationary light stages. The input are high-resolution RGB-D images captured by a mobile, hand-held capture system with point lights for active illumination. Compared to previous works that jointly estimate geometry and materials from a hand-held scanner, we formulate this problem using a single objective function that can be minimized using off-the-shelf gradient-based solvers. To facilitate scalability to large numbers of observation views and optimization variables, we introduce a distributed optimization algorithm that reconstructs 2.5D keyframe-based representations of the scene. A novel multi-view consistency regularizer effectively synchronizes neighboring keyframes such that the local optimization results allow for seamless integration into a globally consistent 3D model. We provide a study on the importance of each component in our formulation and show that our method compares favorably to baselines. We further demonstrate that our method accurately reconstructs various objects and materials and allows for expansion to spatially larger scenes. We believe that this work represents a significant step towards making geometry and material estimation from hand-held scanners scalable.
Latex Bibtex Citation:
@article{Schmitt2023PAMI,
author = {Carolin Schmitt and Bozidar Antic and Andrei Neculai and Joo Ho Lee and Andreas Geiger},
title = {Towards Scalable Multi-View Reconstruction of Geometry and Materials},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2023}
}
Latex Bibtex Citation:
@article{Schmitt2023PAMI,
author = {Carolin Schmitt and Bozidar Antic and Andrei Neculai and Joo Ho Lee and Andreas Geiger},
title = {Towards Scalable Multi-View Reconstruction of Geometry and Materials},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2023}
}

Fast-SNARF: A Fast Deformer for Articulated Neural Fields
X. Chen, T. Jiang, J. Song, M. Rietmann, A. Geiger, M. Black and O. Hilliges
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
X. Chen, T. Jiang, J. Song, M. Rietmann, A. Geiger, M. Black and O. Hilliges
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
Abstract: Neural fields have revolutionized the area of 3D reconstruction and novel view synthesis of rigid scenes. A key challenge in making such methods applicable to articulated objects, such as the human body, is to model the deformation of 3D locations between the rest pose (a canonical space) and the deformed space. We propose a new articulation module for neural fields, Fast-SNARF, which finds accurate correspondences between canonical space and posed space via iterative root finding. Fast-SNARF is a drop-in replacement in functionality to our previous work, SNARF, while significantly improving its computational efficiency. We contribute several algorithmic and implementation improvements over SNARF, yielding a speed-up of 150×. These improvements include voxel-based correspondence search, pre-computing the linear blend skinning function, and an efficient software implementation with CUDA kernels. Fast-SNARF enables efficient and simultaneous optimization of shape and skinning weights given deformed observations without correspondences (e.g. 3D meshes). Because learning of deformation maps is a crucial component in many 3D human avatar methods and since Fast-SNARF provides a computationally efficient solution, we believe that this work represents a significant step towards the practical creation of 3D virtual humans.
Latex Bibtex Citation:
@article{Chen2023PAMI,
author = {Xu Chen and Tianjian Jiang and Jie Song and Max Rietmann and Andreas Geiger and Michael J. Black and Otmar Hilliges},
title = {Fast-SNARF: A Fast Deformer for Articulated Neural Fields},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2023}
}
Latex Bibtex Citation:
@article{Chen2023PAMI,
author = {Xu Chen and Tianjian Jiang and Jie Song and Max Rietmann and Andreas Geiger and Michael J. Black and Otmar Hilliges},
title = {Fast-SNARF: A Fast Deformer for Articulated Neural Fields},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2023}
}

TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz and A. Geiger
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz and A. Geiger
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
Abstract: How should we integrate representations from complementary sensors for autonomous driving? Geometry-based fusion has shown promise for perception (e.g. object detection, motion forecasting). However, in the context of end-to-end driving, we find that imitation learning based on existing sensor fusion methods underperforms in complex driving scenarios with a high density of dynamic agents. Therefore, we propose TransFuser, a mechanism to integrate image and LiDAR representations using self-attention. Our approach uses transformer modules at multiple resolutions to fuse perspective view and bird's eye view feature maps. We experimentally validate its efficacy on a challenging new benchmark with long routes and dense traffic, as well as the official leaderboard of the CARLA urban driving simulator. At the time of submission, TransFuser outperforms all prior work on the CARLA leaderboard in terms of driving score by a large margin. Compared to geometry-based fusion, TransFuser reduces the average collisions per kilometer by 48%.
Latex Bibtex Citation:
@article{Chitta2022PAMI,
author = {Kashyap Chitta and Aditya Prakash and Bernhard Jaeger and Zehao Yu and Katrin Renz and Andreas Geiger},
title = {TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2023}
}
Latex Bibtex Citation:
@article{Chitta2022PAMI,
author = {Kashyap Chitta and Aditya Prakash and Bernhard Jaeger and Zehao Yu and Katrin Renz and Andreas Geiger},
title = {TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2023}
}

MERF: Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes
C. Reiser, R. Szeliski, D. Verbin, P. Srinivasan, B. Mildenhall, A. Geiger, J. Barron and P. Hedman
International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), 2023
C. Reiser, R. Szeliski, D. Verbin, P. Srinivasan, B. Mildenhall, A. Geiger, J. Barron and P. Hedman
International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), 2023
Abstract: Neural radiance fields enable state-of-the-art photorealistic view synthesis. However, existing radiance field representations are either too compute-intensive for real-time rendering or require too much memory to scale to large scenes. We present a Memory-Efficient Radiance Field (MERF) representation that achieves real-time rendering of large-scale scenes in a browser. MERF reduces the memory consumption of prior sparse volumetric radiance fields using a combination of a sparse feature grid and high-resolution 2D feature planes. To support large-scale unbounded scenes, we introduce a novel contraction function that maps scene coordinates into a bounded volume while still allowing for efficient ray-box intersection. We design a lossless procedure for baking the parameterization used during training into a model that achieves real-time rendering while still preserving the photorealistic view synthesis quality of a volumetric radiance field.
Latex Bibtex Citation:
@inproceedings{Reiser2023SIGGRAPH,
author = {Christian Reiser and Richard Szeliski and Dor Verbin and Pratul P. Srinivasan and Ben Mildenhall and Andreas Geiger and Jonathan T. Barron and Peter Hedman},
title = {MERF: Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes},
booktitle = {International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH)},
year = {2023}
}
Latex Bibtex Citation:
@inproceedings{Reiser2023SIGGRAPH,
author = {Christian Reiser and Richard Szeliski and Dor Verbin and Pratul P. Srinivasan and Ben Mildenhall and Andreas Geiger and Jonathan T. Barron and Peter Hedman},
title = {MERF: Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes},
booktitle = {International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH)},
year = {2023}
}

Dictionary Fields: Learning a Neural Basis Decomposition
A. Chen, Z. Xu, X. Wei, S. Tang, H. Su and A. Geiger
International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), 2023
A. Chen, Z. Xu, X. Wei, S. Tang, H. Su and A. Geiger
International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), 2023
Abstract: We present Dictionary Fields, a novel neural representation which decomposes a signal into a product of factors, each represented by a classical or neural field representation, operating on transformed input coordinates. More specifically, we factorize a signal into a coefficient field and a basis field, and exploit periodic coordinate transformations to apply the same basis functions across multiple locations and scales. Our experiments show that Dictionary Fields lead to improvements in approximation quality, compactness, and training time when compared to previous fast reconstruction methods. Experimentally, our representation achieves better image approximation quality on 2D image regression tasks, higher geometric quality when reconstructing 3D signed distance fields, and higher compactness for radiance field reconstruction tasks. Furthermore, Dictionary Fields enable generalization to unseen images/3D scenes by sharing bases across signals during training which greatly benefits use cases such as image regression from partial observations and few-shot radiance field reconstruction.
Latex Bibtex Citation:
@inproceedings{Chen2023SIGGRAPH,
author = {Anpei Chen and Zexiang Xu and Xinyue Wei and Siyu Tang and Hao Su and Andreas Geiger},
title = {Dictionary Fields: Learning a Neural Basis Decomposition},
booktitle = {International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH)},
year = {2023}
}
Latex Bibtex Citation:
@inproceedings{Chen2023SIGGRAPH,
author = {Anpei Chen and Zexiang Xu and Xinyue Wei and Siyu Tang and Hao Su and Andreas Geiger},
title = {Dictionary Fields: Learning a Neural Basis Decomposition},
booktitle = {International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH)},
year = {2023}
}

Factor Fields: A Unified Framework for Neural Fields and Beyond
A. Chen, Z. Xu, X. Wei, S. Tang, H. Su and A. Geiger
Arxiv, 2023
A. Chen, Z. Xu, X. Wei, S. Tang, H. Su and A. Geiger
Arxiv, 2023
Abstract: We present Factor Fields, a novel framework for modeling and representing signals. Factor Fields decomposes a signal into a product of factors, each represented by a classical or neural field representation which operates on transformed input coordinates. This decomposition results in a unified framework that accommodates several recent signal representations including NeRF, Plenoxels, EG3D, Instant-NGP, and TensoRF. Additionally, our framework allows for the creation of powerful new signal representations, such as the "Dictionary Field" (DiF) which is a second contribution of this paper. Our experiments show that DiF leads to improvements in approximation quality, compactness, and training time when compared to previous fast reconstruction methods. Experimentally, our representation achieves better image approximation quality on 2D image regression tasks, higher geometric quality when reconstructing 3D signed distance fields, and higher compactness for radiance field reconstruction tasks. Furthermore, DiF enables generalization to unseen images/3D scenes by sharing bases across signals during training which greatly benefits use cases such as image regression from sparse observations and few-shot radiance field reconstruction.
Latex Bibtex Citation:
@article{Chen2023ARXIV,
author = {Anpei Chen and Zexiang Xu and Xinyue Wei and Siyu Tang and Hao Su and Andreas Geiger},
title = {Factor Fields: A Unified Framework for Neural Fields and Beyond},
journal = {Arxiv},
year = {2023}
}
Latex Bibtex Citation:
@article{Chen2023ARXIV,
author = {Anpei Chen and Zexiang Xu and Xinyue Wei and Siyu Tang and Hao Su and Andreas Geiger},
title = {Factor Fields: A Unified Framework for Neural Fields and Beyond},
journal = {Arxiv},
year = {2023}
}

StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis (oral)
A. Sauer, T. Karras, S. Laine, A. Geiger and T. Aila
International Conference on Machine learning (ICML), 2023
A. Sauer, T. Karras, S. Laine, A. Geiger and T. Aila
International Conference on Machine learning (ICML), 2023
Abstract: Text-to-image synthesis has recently seen significant progress thanks to large pretrained language models, large-scale training data, and the introduction of scalable model families such as diffusion and autoregressive models. However, the best-performing models require iterative evaluation to generate a single sample. In contrast, generative adversarial networks (GANs) only need a single forward pass. They are thus much faster, but they currently remain far behind the state-of-the-art in large-scale text-to-image synthesis. This paper aims to identify the necessary steps to regain competitiveness. Our proposed model, StyleGAN-T, addresses the specific requirements of large-scale text-to-image synthesis, such as large capacity, stable training on diverse datasets, strong text alignment, and controllable variation vs. text alignment tradeoff. StyleGAN-T significantly improves over previous GANs and outperforms distilled diffusion models - the previous state-of-the-art in fast text-to-image synthesis - in terms of sample quality and speed.
Latex Bibtex Citation:
@inproceedings{Sauer2023ICML,
author = {Axel Sauer and Tero Karras and Samuli Laine and Andreas Geiger and Timo Aila},
title = {StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis},
booktitle = {International Conference on Machine learning (ICML)},
year = {2023}
}
Latex Bibtex Citation:
@inproceedings{Sauer2023ICML,
author = {Axel Sauer and Tero Karras and Samuli Laine and Andreas Geiger and Timo Aila},
title = {StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis},
booktitle = {International Conference on Machine learning (ICML)},
year = {2023}
}

Unifying Flow, Stereo and Depth Estimation
H. Xu, J. Zhang, J. Cai, H. Rezatofighi, F. Yu, D. Tao and A. Geiger
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
H. Xu, J. Zhang, J. Cai, H. Rezatofighi, F. Yu, D. Tao and A. Geiger
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
Abstract: We present a unified formulation and model for three motion and 3D perception tasks: optical flow, rectified stereo matching and unrectified stereo depth estimation from posed images. Unlike previous specialized architectures for each specific task, we formulate all three tasks as a unified dense correspondence matching problem, which can be solved with a single model by directly comparing feature similarities. Such a formulation calls for discriminative feature representations, which we achieve using a Transformer, in particular the cross-attention mechanism. We demonstrate that cross-attention enables integration of knowledge from another image via cross-view interactions, which greatly improves the quality of the extracted features. Our unified model naturally enables cross-task transfer since the model architecture and parameters are shared across tasks. We outperform RAFT with our unified model on the challenging Sintel dataset, and our final model that uses a few additional task-specific refinement steps outperforms or compares favorably to recent state-of-the-art methods on 10 popular flow, stereo and depth datasets, while being simpler and more efficient in terms of model design and inference speed.
Latex Bibtex Citation:
@article{Xu2023PAMI,
author = {Haofei Xu and Jing Zhang and Jianfei Cai and Hamid Rezatofighi and Fisher Yu and Dacheng Tao and Andreas Geiger},
title = {Unifying Flow, Stereo and Depth Estimation},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2023}
}
Latex Bibtex Citation:
@article{Xu2023PAMI,
author = {Haofei Xu and Jing Zhang and Jianfei Cai and Hamid Rezatofighi and Fisher Yu and Dacheng Tao and Andreas Geiger},
title = {Unifying Flow, Stereo and Depth Estimation},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2023}
}

End-to-end Autonomous Driving: Challenges and Frontiers
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger and H. Li
Arxiv, 2023
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger and H. Li
Arxiv, 2023
Abstract: The autonomous driving community has witnessed a rapid growth in approaches that embrace an end-to-end algorithm framework, utilizing raw sensor input to generate vehicle motion plans, instead of concentrating on individual tasks such as detection and motion prediction. End-to-end systems, in comparison to modular pipelines, benefit from joint feature optimization for perception and planning. This field has flourished due to the availability of large-scale datasets, closed-loop evaluation, and the increasing need for autonomous driving algorithms to perform effectively in challenging scenarios. In this survey, we provide a comprehensive analysis of more than 250 papers, covering the motivation, roadmap, methodology, challenges, and future trends in end-to-end autonomous driving. We delve into several critical challenges, including multi-modality, interpretability, causal confusion, robustness, and world models, amongst others. Additionally, we discuss current advancements in foundation models and visual pre-training, as well as how to incorporate these techniques within the end-to-end driving framework.
Latex Bibtex Citation:
@article{Chen2023ARXIVa,
author = {Li Chen and Penghao Wu and Kashyap Chitta and Bernhard Jaeger and Andreas Geiger and Hongyang Li},
title = {End-to-end Autonomous Driving: Challenges and Frontiers},
journal = {Arxiv},
year = {2023}
}
Latex Bibtex Citation:
@article{Chen2023ARXIVa,
author = {Li Chen and Penghao Wu and Kashyap Chitta and Bernhard Jaeger and Andreas Geiger and Hongyang Li},
title = {End-to-end Autonomous Driving: Challenges and Frontiers},
journal = {Arxiv},
year = {2023}
}

GOOD: Exploring geometric cues for detecting objects in an open world
H. Huang, A. Geiger and D. Zhang
International Conference on Learning Representations (ICLR), 2023
H. Huang, A. Geiger and D. Zhang
International Conference on Learning Representations (ICLR), 2023
Abstract: We address the task of open-world class-agnostic object detection, i.e., detecting every object in an image by learning from a limited number of base object classes. State-of-the-art RGB-based models suffer from overfitting the training classes and often fail at detecting novel-looking objects. This is because RGB-based models primarily rely on appearance similarity to detect novel objects and are also prone to overfitting short-cut cues such as textures and discriminative parts. To address these shortcomings of RGB-based object detectors, we propose incorporating geometric cues such as depth and normals, predicted by general-purpose monocular estimators. Specifically, we use the geometric cues to train an object proposal network for pseudo-labeling unannotated novel objects in the training set. Our resulting Geometry-guided Open-world Object Detector (GOOD) significantly improves detection recall for novel object categories and already performs well with only a few training classes. Using a single "person" class for training on the COCO dataset, GOOD surpasses SOTA methods by 5.0% AR@100, a relative improvement of 24%.
Latex Bibtex Citation:
@inproceedings{Huang2023ICLR,
author = {Haiwen Huang and Andreas Geiger and Dan Zhang},
title = {GOOD: Exploring geometric cues for detecting objects in an open world},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2023}
}
Latex Bibtex Citation:
@inproceedings{Huang2023ICLR,
author = {Haiwen Huang and Andreas Geiger and Dan Zhang},
title = {GOOD: Exploring geometric cues for detecting objects in an open world},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2023}
}

NeRFPlayer: Streamable Dynamic Scene Representation with Decomposed Neural Radiance Fields
L. Song, A. Chen, Z. Li, Z. Chen, L. Chen, J. Yuan, Y. Xu and A. Geiger
IEEE Transactions on Visualization and Computer Graphics (TVCG), 2023
L. Song, A. Chen, Z. Li, Z. Chen, L. Chen, J. Yuan, Y. Xu and A. Geiger
IEEE Transactions on Visualization and Computer Graphics (TVCG), 2023
Abstract: Visually exploring in a real-world 4D spatiotemporal space freely in VR has been a long-term quest. The task is especially appealing when only a few or even single RGB cameras are used for capturing the dynamic scene. To this end, we present an efficient framework capable of fast reconstruction, compact modeling, and streamable rendering. First, we propose to decompose the 4D spatiotemporal space according to temporal characteristics. Points in the 4D space are associated with probabilities of belonging to three categories: static, deforming, and new areas. Each area is represented and regularized by a separate neural field. Second, we propose a hybrid representations based feature streaming scheme for efficiently modeling the neural fields. Our approach, coined NeRFPlayer, is evaluated on dynamic scenes captured by single hand-held cameras and multi-camera arrays, achieving comparable or superior rendering performance in terms of quality and speed comparable to recent state-of-the-art methods, achieving reconstruction in 10 seconds per frame and real-time rendering.
Latex Bibtex Citation:
@article{Song2023TVCG,
author = {Liangchen Song and Anpei Chen and Zhong Li and Zhang Chen and Lele Chen and Junsong Yuan and Yi Xu and Andreas Geiger},
title = {NeRFPlayer: Streamable Dynamic Scene Representation with Decomposed Neural Radiance Fields},
journal = {IEEE Transactions on Visualization and Computer Graphics (TVCG)},
year = {2023}
}
Latex Bibtex Citation:
@article{Song2023TVCG,
author = {Liangchen Song and Anpei Chen and Zhong Li and Zhang Chen and Lele Chen and Junsong Yuan and Yi Xu and Andreas Geiger},
title = {NeRFPlayer: Streamable Dynamic Scene Representation with Decomposed Neural Radiance Fields},
journal = {IEEE Transactions on Visualization and Computer Graphics (TVCG)},
year = {2023}
}
2022

PlanT: Explainable Planning Transformers via Object-Level Representations
K. Renz, K. Chitta, O. Mercea, A. Koepke, Z. Akata and A. Geiger
Conference on Robot Learning (CoRL), 2022
K. Renz, K. Chitta, O. Mercea, A. Koepke, Z. Akata and A. Geiger
Conference on Robot Learning (CoRL), 2022
Abstract: Planning an optimal route in a complex environment requires efficient reasoning about the surrounding scene. While human drivers prioritize important objects and ignore details not relevant to the decision, learning-based planners typically extract features from dense, high-dimensional grid representations of the scene containing all vehicle and road context information. In this paper, we propose PlanT, a novel approach for planning in the context of self-driving that uses a standard transformer architecture. PlanT is based on imitation learning with a compact object-level input representation. With this representation, we demonstrate that information regarding the ego vehicle's route provides sufficient context regarding the road layout for planning. On the challenging Longest6 benchmark for CARLA, PlanT outperforms all prior methods (matching the driving score of the expert) while being 5.3x faster than equivalent pixel-based planning baselines during inference. Furthermore, we propose an evaluation protocol to quantify the ability of planners to identify relevant objects, providing insights regarding their decision making. Our results indicate that PlanT can reliably focus on the most relevant object in the scene, even when this object is geometrically distant.
Latex Bibtex Citation:
@inproceedings{Renz2022CORL,
author = {Katrin Renz and Kashyap Chitta and Otniel-Bogdan Mercea and Almut Sophia Koepke and Zeynep Akata and Andreas Geiger},
title = {PlanT: Explainable Planning Transformers via Object-Level Representations},
booktitle = {Conference on Robot Learning (CoRL)},
year = {2022}
}
Latex Bibtex Citation:
@inproceedings{Renz2022CORL,
author = {Katrin Renz and Kashyap Chitta and Otniel-Bogdan Mercea and Almut Sophia Koepke and Zeynep Akata and Andreas Geiger},
title = {PlanT: Explainable Planning Transformers via Object-Level Representations},
booktitle = {Conference on Robot Learning (CoRL)},
year = {2022}
}

VoxGRAF: Fast 3D-Aware Image Synthesis with Sparse Voxel Grids
K. Schwarz, A. Sauer, M. Niemeyer, Y. Liao and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2022
K. Schwarz, A. Sauer, M. Niemeyer, Y. Liao and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2022
Abstract: State-of-the-art 3D-aware generative models rely on coordinate-based MLPs to parameterize 3D radiance fields. While demonstrating impressive results, querying an MLP for every sample along each ray leads to slow rendering. Therefore, existing approaches often render low-resolution feature maps and process them with an upsampling network to obtain the final image. Albeit efficient, neural rendering often entangles viewpoint and content such that changing the camera pose results in unwanted changes of geometry or appearance. Motivated by recent results in voxel-based novel view synthesis, we investigate the utility of sparse voxel grid representations for fast and 3D-consistent generative modeling in this paper. Our results demonstrate that monolithic MLPs can indeed be replaced by 3D convolutions when combining sparse voxel grids with progressive growing, free space pruning and appropriate regularization.
To obtain a compact representation of the scene and allow for scaling to higher voxel resolutions, our model disentangles the foreground object (modeled in 3D) from the background (modeled in 2D). In contrast to existing approaches, our method requires only a single forward pass to generate a full 3D scene. It hence allows for efficient rendering from arbitrary viewpoints while yielding 3D consistent results with high visual fidelity.
Latex Bibtex Citation:
@inproceedings{Schwarz2022NEURIPS,
author = {Katja Schwarz and Axel Sauer and Michael Niemeyer and Yiyi Liao and Andreas Geiger},
title = {VoxGRAF: Fast 3D-Aware Image Synthesis with Sparse Voxel Grids},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2022}
}
Latex Bibtex Citation:
@inproceedings{Schwarz2022NEURIPS,
author = {Katja Schwarz and Axel Sauer and Michael Niemeyer and Yiyi Liao and Andreas Geiger},
title = {VoxGRAF: Fast 3D-Aware Image Synthesis with Sparse Voxel Grids},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2022}
}

MonoSDF: Exploring Monocular Geometric Cues for Neural Implicit Surface Reconstruction
Z. Yu, S. Peng, M. Niemeyer, T. Sattler and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2022
Z. Yu, S. Peng, M. Niemeyer, T. Sattler and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2022
Abstract: In recent years, neural implicit surface reconstruction methods have become popular for multi-view 3D reconstruction. In contrast to traditional multi-view stereo methods, these approaches tend to produce smoother and more complete reconstructions due to the inductive smoothness bias of neural networks. State-of-the-art neural implicit methods allow for high-quality reconstructions of simple scenes from many input views. Yet, their performance drops significantly for larger and more complex scenes and scenes captured from sparse viewpoints. This is caused primarily by the inherent ambiguity in the RGB reconstruction loss that does not provide enough constraints, in particular in less-observed and textureless areas. Motivated by recent advances in the area of monocular geometry prediction, we systematically explore the utility these cues provide for improving neural implicit surface reconstruction. We demonstrate that depth and normal cues, predicted by general-purpose monocular estimators, significantly improve reconstruction quality and optimization time. Further, we analyse and investigate multiple design choices for representing neural implicit surfaces, ranging from monolithic MLP models over single-grid to multi-resolution grid representations. We observe that geometric monocular priors improve performance both for small-scale single-object as well as large-scale multi-object scenes, independent of the choice of representation.
Latex Bibtex Citation:
@inproceedings{Yu2022NEURIPS,
author = {Zehao Yu and Songyou Peng and Michael Niemeyer and Torsten Sattler and Andreas Geiger},
title = {MonoSDF: Exploring Monocular Geometric Cues for Neural Implicit Surface Reconstruction},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2022}
}
Latex Bibtex Citation:
@inproceedings{Yu2022NEURIPS,
author = {Zehao Yu and Songyou Peng and Michael Niemeyer and Torsten Sattler and Andreas Geiger},
title = {MonoSDF: Exploring Monocular Geometric Cues for Neural Implicit Surface Reconstruction},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2022}
}

ARAH: Animatable Volume Rendering of Articulated Human SDFs
S. Wang, K. Schwarz, A. Geiger and S. Tang
European Conference on Computer Vision (ECCV), 2022
S. Wang, K. Schwarz, A. Geiger and S. Tang
European Conference on Computer Vision (ECCV), 2022
Abstract: Combining human body models with differentiable rendering has recently enabled animatable avatars of clothed humans from sparse sets of multi-view RGB videos. While state-of-the-art approaches achieve a realistic appearance with neural radiance fields (NeRF), the inferred geometry often lacks detail due to missing geometric constraints. Further, animating avatars in out-of-distribution poses is not yet possible because the mapping from observation space to canonical space does not generalize faithfully to unseen poses. In this work, we address these shortcomings and propose a model to create animatable clothed human avatars with detailed geometry that generalize well to out-of-distribution poses. To achieve detailed geometry, we combine an articulated implicit surface representation with volume rendering. For generalization, we propose a novel joint root-finding algorithm for simultaneous ray-surface intersection search and correspondence search. Our algorithm enables efficient point sampling and accurate point canonicalization while generalizing well to unseen poses. We demonstrate that our proposed pipeline can generate clothed avatars with high-quality pose-dependent geometry and appearance from a sparse set of multi-view RGB videos. Our method achieves state-of-the-art performance on geometry and appearance reconstruction while creating animatable avatars that generalize well to out-of-distribution poses beyond the small number of training poses.
Latex Bibtex Citation:
@inproceedings{Wang2022ECCV,
author = {Shaofei Wang and Katja Schwarz and Andreas Geiger and Siyu Tang},
title = {ARAH: Animatable Volume Rendering of Articulated Human SDFs},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2022}
}
Latex Bibtex Citation:
@inproceedings{Wang2022ECCV,
author = {Shaofei Wang and Katja Schwarz and Andreas Geiger and Siyu Tang},
title = {ARAH: Animatable Volume Rendering of Articulated Human SDFs},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2022}
}

TensoRF: Tensorial Radiance Fields
A. Chen, Z. Xu, A. Geiger, J. Yu and H. Su
European Conference on Computer Vision (ECCV), 2022
A. Chen, Z. Xu, A. Geiger, J. Yu and H. Su
European Conference on Computer Vision (ECCV), 2022
Abstract: We present TensoRF, a novel approach to model and reconstruct radiance fields. Unlike NeRF that purely uses MLPs, we model the radiance field of a scene as a 4D tensor, which represents a 3D voxel grid with per-voxel multi-channel features. Our central idea is to factorize the 4D scene tensor into multiple compact low-rank tensor components. We demonstrate that applying traditional CP decomposition - that factorizes tensors into rank-one components with compact vectors -- in our framework leads to improvements over vanilla NeRF. To further boost performance, we introduce a novel vector-matrix (VM) decomposition that relaxes the low-rank constraints for two modes of a tensor and factorizes tensors into compact vector and matrix factors. Beyond superior rendering quality,
our models with CP and VM decompositions lead to a significantly lower memory footprint in comparison to previous and concurrent works that directly optimize per-voxel features. Experimentally, we demonstrate that TensoRF with CP decomposition achieves fast reconstruction (<30 min) with better rendering quality and even a smaller model size (<4 MB) compared to NeRF. Moreover, TensoRF with VM decomposition further boosts rendering quality and outperforms previous state-of-the-art methods, while reducing the reconstruction time (<10 min) and retaining a compact model size (<75 MB).
Latex Bibtex Citation:
@inproceedings{Chen2022ECCV,
author = {Anpei Chen and Zexiang Xu and Andreas Geiger and Jingyi Yu and Hao Su},
title = {TensoRF: Tensorial Radiance Fields},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2022}
}
Latex Bibtex Citation:
@inproceedings{Chen2022ECCV,
author = {Anpei Chen and Zexiang Xu and Andreas Geiger and Jingyi Yu and Hao Su},
title = {TensoRF: Tensorial Radiance Fields},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2022}
}

KING: Generating Safety-Critical Driving Scenarios for Robust Imitation via Kinematics Gradients (oral)
N. Hanselmann, K. Renz, K. Chitta, A. Bhattacharyya and A. Geiger
European Conference on Computer Vision (ECCV), 2022
N. Hanselmann, K. Renz, K. Chitta, A. Bhattacharyya and A. Geiger
European Conference on Computer Vision (ECCV), 2022
Abstract: Simulators offer the possibility of safe, low-cost development of self-driving systems. However, current driving simulators exhibit naïve behavior models for background traffic. Hand-tuned scenarios are typically added during simulation to induce safety-critical situations. An alternative approach is to adversarially perturb the background traffic trajectories. In this paper, we study this approach to safety-critical driving scenario generation using the CARLA simulator. We use a kinematic bicycle model as a proxy to the simulator's true dynamics and observe that gradients through this proxy model are sufficient for optimizing the background traffic trajectories. Based on this finding, we propose KING, which generates safety-critical driving scenarios with a 20% higher success rate than black-box optimization. By solving the scenarios generated by KING using a privileged rule-based expert algorithm, we obtain training data for an imitation learning policy. After fine-tuning on this new data, we show that the policy becomes better at avoiding collisions. Importantly, our generated data leads to reduced collisions on both held-out scenarios generated via KING as well as traditional hand-crafted scenarios, demonstrating improved robustness.
Latex Bibtex Citation:
@inproceedings{Hanselmann2022ECCV,
author = {Niklas Hanselmann and Katrin Renz and Kashyap Chitta and Apratim Bhattacharyya and Andreas Geiger},
title = {KING: Generating Safety-Critical Driving Scenarios for Robust Imitation via Kinematics Gradients},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2022}
}
Latex Bibtex Citation:
@inproceedings{Hanselmann2022ECCV,
author = {Niklas Hanselmann and Katrin Renz and Kashyap Chitta and Apratim Bhattacharyya and Andreas Geiger},
title = {KING: Generating Safety-Critical Driving Scenarios for Robust Imitation via Kinematics Gradients},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2022}
}

Panoptic NeRF: 3D-to-2D Label Transfer for Panoptic Urban Scene Segmentation
X. Fu, S. Zhang, T. Chen, Y. Lu, L. Zhu, X. Zhou, A. Geiger and Y. Liao
International Conference on 3D Vision (3DV), 2022
X. Fu, S. Zhang, T. Chen, Y. Lu, L. Zhu, X. Zhou, A. Geiger and Y. Liao
International Conference on 3D Vision (3DV), 2022
Abstract: Large-scale training data with high-quality annotations is critical for training semantic and instance segmentation models. Unfortunately, pixel-wise annotation is labor-intensive and costly, raising the demand for more efficient labeling strategies. In this work, we present a novel 3D-to-2D label transfer method, Panoptic NeRF, which aims for obtaining per-pixel 2D semantic and instance labels from easy-to-obtain coarse 3D bounding primitives. Our method utilizes NeRF as a differentiable tool to unify coarse 3D annotations and 2D semantic cues transferred from existing datasets. We demonstrate that this combination allows for improved geometry guided by semantic information, enabling rendering of accurate semantic maps across multiple views. Furthermore, this fusion process resolves label ambiguity of the coarse 3D annotations and filters noise in the 2D predictions. By inferring in 3D space and rendering to 2D labels, our 2D semantic and instance labels are multi-view consistent by design. Experimental results show that Panoptic NeRF outperforms existing semantic and instance label transfer methods in terms of accuracy and multi-view consistency on challenging urban scenes of the KITTI-360 dataset.
Latex Bibtex Citation:
@inproceedings{Fu2022THREEDV,
author = {Xiao Fu and Shangzhan Zhang and Tianrun Chen and Yichong Lu and Lanyun Zhu and Xiaowei Zhou and Andreas Geiger and Yiyi Liao},
title = {Panoptic NeRF: 3D-to-2D Label Transfer for Panoptic Urban Scene Segmentation},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2022}
}
Latex Bibtex Citation:
@inproceedings{Fu2022THREEDV,
author = {Xiao Fu and Shangzhan Zhang and Tianrun Chen and Yichong Lu and Lanyun Zhu and Xiaowei Zhou and Andreas Geiger and Yiyi Liao},
title = {Panoptic NeRF: 3D-to-2D Label Transfer for Panoptic Urban Scene Segmentation},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2022}
}

StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets
A. Sauer, K. Schwarz and A. Geiger
International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), 2022
A. Sauer, K. Schwarz and A. Geiger
International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), 2022
Abstract: Computer graphics has experienced a recent surge of data-centric approaches for photorealistic and controllable content creation. StyleGAN in particular sets new standards for generative modeling regarding image quality and controllability. However, StyleGAN's performance severely degrades on large unstructured datasets such as ImageNet. StyleGAN was designed for controllability; hence, prior works suspect its restrictive design to be unsuitable for diverse datasets. In contrast, we find the main limiting factor to be the current training strategy. Following the recently introduced Projected GAN paradigm, we leverage powerful neural network priors and a progressive growing strategy to successfully train the latest StyleGAN3 generator on ImageNet. Our final model, StyleGAN-XL, sets a new state-of-the-art on large-scale image synthesis and is the first to generate images at a resolution of 1024x1024 at such a dataset scale. We demonstrate that this model can invert and edit images beyond the narrow domain of portraits or specific object~classes. Code, models, and supplementary videos can be found at https://sites.google.com/view/stylegan-xl/.
Latex Bibtex Citation:
@inproceedings{Sauer2022SIGGRAPH,
author = {Axel Sauer and Katja Schwarz and Andreas Geiger},
title = {StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets},
booktitle = {International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH)},
year = {2022}
}
Latex Bibtex Citation:
@inproceedings{Sauer2022SIGGRAPH,
author = {Axel Sauer and Katja Schwarz and Andreas Geiger},
title = {StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets},
booktitle = {International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH)},
year = {2022}
}

gDNA: Towards Generative Detailed Neural Avatars
X. Chen, T. Jiang, J. Song, J. Yang, M. Black, A. Geiger and O. Hilliges
Conference on Computer Vision and Pattern Recognition (CVPR), 2022
X. Chen, T. Jiang, J. Song, J. Yang, M. Black, A. Geiger and O. Hilliges
Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Abstract: To make 3D human avatars widely available, we must be able to generate a variety of 3D virtual humans with varied identities and shapes in arbitrary poses. This task is challenging due to the diversity of clothed body shapes, their complex articulations, and the resulting rich, yet stochastic geometric detail in clothing. Hence, current methods that represent 3D people do not provide a full generative model of people in clothing. In this paper, we propose a novel method that learns to generate detailed 3D shapes of people in a variety of garments with corresponding skinning weights. Specifically, we devise a multi-subject forward skinning module that is learned from only a few posed, un-rigged scans per subject. To capture the stochastic nature of high-frequency details in garments, we leverage an adversarial loss formulation that encourages the model to capture the underlying statistics. We provide empirical evidence that this leads to realistic generation of local details such as wrinkles. We show that our model is able to generate natural human avatars wearing diverse and detailed clothing. Furthermore, we show that our method can be used on the task of fitting human models to raw scans, outperforming the previous state-of-the-art.
Latex Bibtex Citation:
@inproceedings{Chen2022CVPR,
author = {Xu Chen and Tianjian Jiang and Jie Song and Jinlong Yang and Michael Black and Andreas Geiger and Otmar Hilliges},
title = {gDNA: Towards Generative Detailed Neural Avatars},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022}
}
Latex Bibtex Citation:
@inproceedings{Chen2022CVPR,
author = {Xu Chen and Tianjian Jiang and Jie Song and Jinlong Yang and Michael Black and Andreas Geiger and Otmar Hilliges},
title = {gDNA: Towards Generative Detailed Neural Avatars},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022}
}

PINA: Learning a Personalized Implicit Neural Avatar from a Single RGB-D Video Sequence
Z. Dong, C. Guo, J. Song, X. Chen, A. Geiger and O. Hilliges
Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Z. Dong, C. Guo, J. Song, X. Chen, A. Geiger and O. Hilliges
Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Abstract: We present a novel method to learn Personalized Implicit Neural Avatars (PINA) from a short RGB-D sequence. This allows non-expert users to create a detailed and personalized virtual copy of themselves, which can be animated with realistic clothing deformations. PINA does not require complete scans, nor does it require a prior learned from large datasets of clothed humans. Learning a complete avatar in this setting is challenging, since only few depth observations are available, which are noisy and incomplete (i.e.only partial visibility of the body per frame). We propose a method to learn the shape and non-rigid deformations via a pose-conditioned implicit surface and a deformation field, defined in canonical space. This allows us to fuse all partial observations into a single consistent canonical representation. Fusion is formulated as a global optimization problem over the pose, shape and skinning parameters. The method can learn neural avatars from real noisy RGB-D sequences for a diverse set of people and clothing styles and these avatars can be animated given unseen motion sequences.
Latex Bibtex Citation:
@inproceedings{Dong2022CVPR,
author = {Zijian Dong and Chen Guo and Jie Song and Xu Chen and Andreas Geiger and Otmar Hilliges},
title = {PINA: Learning a Personalized Implicit Neural Avatar from a Single RGB-D Video Sequence},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022}
}
Latex Bibtex Citation:
@inproceedings{Dong2022CVPR,
author = {Zijian Dong and Chen Guo and Jie Song and Xu Chen and Andreas Geiger and Otmar Hilliges},
title = {PINA: Learning a Personalized Implicit Neural Avatar from a Single RGB-D Video Sequence},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022}
}

RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs (oral)
M. Niemeyer, J. Barron, B. Mildenhall, M. Sajjadi, A. Geiger and N. Radwan
Conference on Computer Vision and Pattern Recognition (CVPR), 2022
M. Niemeyer, J. Barron, B. Mildenhall, M. Sajjadi, A. Geiger and N. Radwan
Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Abstract: Neural Radiance Fields (NeRF) have emerged as a powerful representation for the task of novel view synthesis due to their simplicity and state-of-the-art performance. Though NeRF can produce photorealistic renderings of unseen viewpoints when many input views are available, its performance drops significantly when this number is reduced. We observe that the majority of artifacts in sparse input scenarios are caused by errors in the estimated scene geometry, and by divergent behavior at the start of training. We address this by regularizing the geometry and appearance of patches rendered from unobserved viewpoints, and annealing the ray sampling space during training. We additionally use a normalizing flow model to regularize the color of unobserved viewpoints. Our model outperforms not only other methods that optimize over a single scene, but in many cases also conditional models that are extensively pre-trained on large multi-view datasets.
Latex Bibtex Citation:
@inproceedings{Niemeyer2022CVPR,
author = {Michael Niemeyer and Jonathan Barron and Ben Mildenhall and Mehdi S. M. Sajjadi and Andreas Geiger and Noha Radwan},
title = {RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022}
}
Latex Bibtex Citation:
@inproceedings{Niemeyer2022CVPR,
author = {Michael Niemeyer and Jonathan Barron and Ben Mildenhall and Mehdi S. M. Sajjadi and Andreas Geiger and Noha Radwan},
title = {RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022}
}

KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D
Y. Liao, J. Xie and A. Geiger
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022
Y. Liao, J. Xie and A. Geiger
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022
Abstract: For the last few decades, several major subfields of artificial intelligence including computer vision, graphics, and robotics have progressed largely independently from each other. Recently, however, the community has realized that progress towards robust intelligent systems such as self-driving cars requires a concerted effort across the different fields. This motivated us to develop KITTI-360, successor of the popular KITTI dataset. KITTI-360 is a suburban driving dataset which comprises richer input modalities, comprehensive semantic instance annotations and accurate localization to facilitate research at the intersection of vision, graphics and robotics. For efficient annotation, we created a tool to label 3D scenes with bounding primitives and developed a model that transfers this information into the 2D image domain, resulting in over 150k semantic and instance annotated images and 1B annotated 3D points. Moreover, we established benchmarks and baselines for several tasks relevant to mobile perception, encompassing problems from computer vision, graphics, and robotics on the same dataset. KITTI-360 will enable progress at the intersection of these research areas and thus contributing towards solving one of our grand challenges: the development of fully autonomous self-driving systems.
Latex Bibtex Citation:
@article{Liao2022PAMI,
author = {Yiyi Liao and Jun Xie and Andreas Geiger},
title = {KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2022}
}
Latex Bibtex Citation:
@article{Liao2022PAMI,
author = {Yiyi Liao and Jun Xie and Andreas Geiger},
title = {KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2022}
}
2021

Projected GANs Converge Faster
A. Sauer, K. Chitta, J. Müller and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2021
A. Sauer, K. Chitta, J. Müller and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2021
Abstract: Generative Adversarial Networks (GANs) produce high-quality images but are challenging to train. They need careful regularization, vast amounts of compute, and expensive hyper-parameter sweeps. We make significant headway on these issues by projecting generated and real samples into a fixed, pretrained feature space. Motivated by the finding that the discriminator cannot fully exploit features from deeper layers of the pretrained model, we propose a more effective strategy that mixes features across channels and resolutions. Our Projected GAN improves image quality, sample efficiency, and convergence speed. It is further compatible with resolutions of up to one Megapixel and advances the state-of-the-art Fréchet Inception Distance (FID) on twenty-two benchmark datasets. Importantly, Projected GANs match the previously lowest FIDs up to 40 times faster, cutting the wall-clock time from 5 days to less than 3 hours given the same computational resources.
Latex Bibtex Citation:
@inproceedings{Sauer2021NEURIPS,
author = {Axel Sauer and Kashyap Chitta and Jens Müller and Andreas Geiger},
title = {Projected GANs Converge Faster},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Sauer2021NEURIPS,
author = {Axel Sauer and Kashyap Chitta and Jens Müller and Andreas Geiger},
title = {Projected GANs Converge Faster},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2021}
}

MetaAvatar: Learning Animatable Clothed Human Models from Few Depth Images
S. Wang, M. Mihajlovic, Q. Ma, A. Geiger and S. Tang
Advances in Neural Information Processing Systems (NeurIPS), 2021
S. Wang, M. Mihajlovic, Q. Ma, A. Geiger and S. Tang
Advances in Neural Information Processing Systems (NeurIPS), 2021
Abstract: In this paper, we aim to create generalizable and controllable neural signed distance fields (SDFs) that represent clothed humans from monocular depth observations. Recent advances in deep learning, especially neural implicit representations, have enabled human shape reconstruction and controllable avatar generation from different sensor inputs. However, to generate realistic cloth deformations from novel input poses, watertight meshes or dense full-body scans are usually needed as inputs. Furthermore, due to the difficulty of effectively modeling pose-dependent cloth deformations for diverse body shapes and cloth types, existing approaches resort to per-subject/cloth-type optimization from scratch, which is computationally expensive. In contrast, we propose an approach that can quickly generate realistic clothed human avatars, represented as controllable neural SDFs, given only monocular depth images. We achieve this by using meta-learning to learn an initialization of a hypernetwork that predicts the parameters of neural SDFs. The hypernetwork is conditioned on human poses and represents a clothed neural avatar that deforms non-rigidly according to the input poses. Meanwhile, it is meta-learned to effectively incorporate priors of diverse body shapes and cloth types and thus can be much faster to fine-tune compared to models trained from scratch. We qualitatively and quantitatively show that our approach outperforms state-of-the-art approaches that require complete meshes as inputs while our approach requires only depth frames as inputs and runs orders of magnitudes faster. Furthermore, we demonstrate that our meta-learned hypernetwork is very robust, being the first to generate avatars with realistic dynamic cloth deformations given as few as 8 monocular depth frames.
Latex Bibtex Citation:
@inproceedings{Wang2021NEURIPS,
author = {Shaofei Wang and Marko Mihajlovic and Qianli Ma and Andreas Geiger and Siyu Tang},
title = {MetaAvatar: Learning Animatable Clothed Human Models from Few Depth Images},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Wang2021NEURIPS,
author = {Shaofei Wang and Marko Mihajlovic and Qianli Ma and Andreas Geiger and Siyu Tang},
title = {MetaAvatar: Learning Animatable Clothed Human Models from Few Depth Images},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2021}
}

ATISS: Autoregressive Transformers for Indoor Scene Synthesis
D. Paschalidou, A. Kar, M. Shugrina, K. Kreis, A. Geiger and S. Fidler
Advances in Neural Information Processing Systems (NeurIPS), 2021
D. Paschalidou, A. Kar, M. Shugrina, K. Kreis, A. Geiger and S. Fidler
Advances in Neural Information Processing Systems (NeurIPS), 2021
Abstract: The ability to synthesize realistic and diverse indoor furniture layouts automatically or based on partial input, unlocks many applications, from better interactive 3D tools to data synthesis for training and simulation. In this paper, we present ATISS, a novel autoregressive transformer architecture for creating diverse and plausible synthetic indoor environments, given only the
room type and its floor plan. In contrast to prior work, which poses scene synthesis as sequence generation, our model generates rooms as unordered sets of objects. We argue that this formulation is more natural, as it makes ATISS generally useful beyond fully automatic room layout synthesis. For example, the same trained model can be used in interactive applications for general scene completion, partial room re-arrangement with any objects specified by the user, as well as object suggestions for any partial room. To enable this, our model leverages the permutation equivariance of the transformer when conditioning on the partial scene, and is trained to be permutation-invariant across object orderings. Our model is trained end-to-end as an autoregressive generative model using only labeled 3D bounding boxes as supervision. Evaluations on four room types in the 3D-FRONT dataset demonstrate that our model consistently generates plausible room layouts that are more realistic than existing methods. In addition, it has fewer parameters, is simpler to implement and train and runs up to 8x faster than existing methods.
Latex Bibtex Citation:
@inproceedings{Paschalidou2021NEURIPS,
author = {Despoina Paschalidou and Amlan Kar and Maria Shugrina and Karsten Kreis and Andreas Geiger and Sanja Fidler},
title = {ATISS: Autoregressive Transformers for Indoor Scene Synthesis},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Paschalidou2021NEURIPS,
author = {Despoina Paschalidou and Amlan Kar and Maria Shugrina and Karsten Kreis and Andreas Geiger and Sanja Fidler},
title = {ATISS: Autoregressive Transformers for Indoor Scene Synthesis},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2021}
}

On the Frequency Bias of Generative Models
K. Schwarz, Y. Liao and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2021
K. Schwarz, Y. Liao and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2021
Abstract: The key objective of Generative Adversarial Networks (GANs) is to generate new data with the same statistics as the provided training data. However, multiple recent works show that state-of-the-art architectures yet struggle to achieve this goal. In particular, they report an elevated amount of high frequencies in the spectral statistics which makes it straightforward to distinguish real and generated images. Explanations for this phenomenon are controversial: While most works attribute the artifacts to the generator, other works point to the discriminator. We take a sober look at those explanations and provide insights on what makes proposed measures against high-frequency artifacts effective. To achieve this, we first independently assess the architectures of both the generator and discriminator and investigate if they exhibit a frequency bias that makes learning the distribution of high-frequency content particularly problematic. Based on these experiments, we make the following four observations: 1) Different upsampling operations bias the generator towards different spectral properties. 2) Checkerboard artifacts introduced by upsampling cannot explain the spectral discrepancies alone as the generator is able to compensate for these artifacts. 3) The discriminator does not struggle with detecting high frequencies per se but rather struggles with frequencies of low magnitude. 4) The downsampling operations in the discriminator can impair the quality of the training signal it provides. In light of these findings, we analyze proposed measures against high-frequency artifacts in state-of-the-art GAN training but find that none of the existing approaches can fully resolve spectral artifacts yet. Our results suggest that there is great potential in improving the discriminator and that this could be key to match the distribution of the training data more closely.
Latex Bibtex Citation:
@inproceedings{Schwarz2021NEURIPS,
author = {Katja Schwarz and Yiyi Liao and Andreas Geiger},
title = {On the Frequency Bias of Generative Models},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Schwarz2021NEURIPS,
author = {Katja Schwarz and Yiyi Liao and Andreas Geiger},
title = {On the Frequency Bias of Generative Models},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2021}
}

Shape As Points: A Differentiable Poisson Solver (oral)
S. Peng, C. Jiang, Y. Liao, M. Niemeyer, M. Pollefeys and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2021
S. Peng, C. Jiang, Y. Liao, M. Niemeyer, M. Pollefeys and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2021
Abstract: In recent years, neural implicit representations gained popularity in 3D reconstruction due to their expressiveness and flexibility. However, the implicit nature of neural implicit representations results in slow inference times and requires careful initialization. In this paper, we revisit the classic yet ubiquitous point cloud representation and introduce a differentiable point-to-mesh layer using a differentiable formulation of Poisson Surface Reconstruction (PSR) which allows for a GPU-accelerated fast solution of the indicator function given an oriented point cloud. The differentiable PSR layer allows us to efficiently and differentiably bridge the explicit 3D point representation with the 3D mesh via the implicit indicator field, enabling end-to-end optimization of surface reconstruction metrics such as Chamfer distance. This duality between points and meshes hence allows us to represent shapes as oriented point clouds, which are explicit, lightweight and expressive. Compared to neural implicit representations, our Shape-As-Points (SAP) model is more interpretable, lightweight, and accelerates inference time by one order of magnitude. Compared to other explicit representations such as points, patches, and meshes, SAP produces topology-agnostic, watertight manifold surfaces. We demonstrate the effectiveness of SAP on the task of surface reconstruction from unoriented point clouds and learning-based reconstruction.
Latex Bibtex Citation:
@inproceedings{Peng2021NEURIPS,
author = {Songyou Peng and Chiyu Max Jiang and Yiyi Liao and Michael Niemeyer and Marc Pollefeys and Andreas Geiger},
title = {Shape As Points: A Differentiable Poisson Solver},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Peng2021NEURIPS,
author = {Songyou Peng and Chiyu Max Jiang and Yiyi Liao and Michael Niemeyer and Marc Pollefeys and Andreas Geiger},
title = {Shape As Points: A Differentiable Poisson Solver},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2021}
}

CAMPARI: Camera-Aware Decomposed Generative Neural Radiance Fields
M. Niemeyer and A. Geiger
International Conference on 3D Vision (3DV), 2021
M. Niemeyer and A. Geiger
International Conference on 3D Vision (3DV), 2021
Abstract: Tremendous progress in deep generative models has led to photorealistic image synthesis. While achieving compelling results, most approaches operate in the two-dimensional image domain, ignoring the three-dimensional nature of our world. Several recent works therefore propose generative models which are 3D-aware, ie, scenes are modeled in 3D and then rendered differentiably to the image plane. While this leads to impressive 3D~consistency, the camera needs to be modelled as well and we show in this work that these methods are sensitive to the choice of prior camera distributions. Current approaches assume fixed intrinsics and predefined priors over camera pose ranges, and parameter tuning is typically required for real-world data. If the data distribution is not matched, results degrade significantly. Our key hypothesis is that learning a camera generator jointly with the image generator leads to a more principled approach to 3D-aware image synthesis. Further, we propose to decompose the scene into a background and foreground model, leading to more efficient and disentangled scene representations. While training from raw, unposed image collections, we learn a 3D- and camera-aware generative model which faithfully recovers not only the image but also the camera data distribution. At test time, our model generates images with explicit control over the camera as well as the shape and appearance of the scene.
Latex Bibtex Citation:
@inproceedings{Niemeyer2021THREEDV,
author = {Michael Niemeyer and Andreas Geiger},
title = {CAMPARI: Camera-Aware Decomposed Generative Neural Radiance Fields},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Niemeyer2021THREEDV,
author = {Michael Niemeyer and Andreas Geiger},
title = {CAMPARI: Camera-Aware Decomposed Generative Neural Radiance Fields},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2021}
}

STEP: Segmenting and Tracking Every Pixel
M. Weber, J. Xie, M. Collins, Y. Zhu, P. Voigtlaender, H. Adam, B. Green, A. Geiger, B. Leibe, D. Cremers, et al.
Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks, 2021
M. Weber, J. Xie, M. Collins, Y. Zhu, P. Voigtlaender, H. Adam, B. Green, A. Geiger, B. Leibe, D. Cremers, et al.
Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks, 2021
Abstract: The task of assigning semantic classes and track identities to every pixel in a video is called video panoptic segmentation. Our work is the first that targets this task in a real-world setting requiring dense interpretation in both spatial and temporal domains. As the ground-truth for this task is difficult and expensive to obtain, existing datasets are either constructed synthetically or only sparsely annotated within short video clips. To overcome this, we introduce a new benchmark encompassing two datasets, KITTI-STEP, and MOTChallenge-STEP. The datasets contain long video sequences, providing challenging examples and a test-bed for studying long-term pixel-precise segmentation and tracking under real-world conditions. We further propose a novel evaluation metric Segmentation and Tracking Quality (STQ) that fairly balances semantic and tracking aspects of this task and is more appropriate for evaluating sequences of arbitrary length. Finally, we provide several baselines to evaluate the status of existing methods on this new challenging dataset. We have made our datasets, metric, benchmark servers, and baselines publicly available, and hope this will inspire future research.
Latex Bibtex Citation:
@inproceedings{Weber2021NEURIPSDATA,
author = {Mark Weber and Jun Xie and Maxwell Collins and Yukun Zhu and Paul Voigtlaender and Hartwig Adam and Bradley Green and Andreas Geiger and Bastian Leibe and Daniel Cremers and Aljosa Osep and Laura Leal-Taixe and Liang-Chieh Chen},
title = {STEP: Segmenting and Tracking Every Pixel},
booktitle = {Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Weber2021NEURIPSDATA,
author = {Mark Weber and Jun Xie and Maxwell Collins and Yukun Zhu and Paul Voigtlaender and Hartwig Adam and Bradley Green and Andreas Geiger and Bastian Leibe and Daniel Cremers and Aljosa Osep and Laura Leal-Taixe and Liang-Chieh Chen},
title = {STEP: Segmenting and Tracking Every Pixel},
booktitle = {Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks},
year = {2021}
}

NEAT: Neural Attention Fields for End-to-End Autonomous Driving
K. Chitta, A. Prakash and A. Geiger
International Conference on Computer Vision (ICCV), 2021
K. Chitta, A. Prakash and A. Geiger
International Conference on Computer Vision (ICCV), 2021
Abstract: Efficient reasoning about the semantic, spatial, and temporal structure of a scene is a crucial pre-requisite for autonomous driving. We present NEural ATtention fields (NEAT), a novel representation that enables such reasoning for end-to-end Imitation Learning (IL) models. Our representation is a continuous function which maps locations in Bird's Eye View (BEV) scene coordinates to waypoints and semantics, using intermediate attention maps to iteratively compress high-dimensional 2D image features into a compact representation. This allows our model to selectively attend to relevant regions in the input while ignoring information irrelevant to the driving task, effectively associating the images with the BEV representation. NEAT nearly matches the state-of-the-art on the CARLA Leaderboard while being far less resource-intensive. Furthermore, visualizing the attention maps for models with NEAT intermediate representations provides improved interpretability. On a new evaluation setting involving adverse environmental conditions and challenging scenarios, NEAT outperforms several strong baselines and achieves driving scores on par with the privileged CARLA expert used to generate its training data.
Latex Bibtex Citation:
@inproceedings{Chitta2021ICCV,
author = {Kashyap Chitta and Aditya Prakash and Andreas Geiger},
title = {NEAT: Neural Attention Fields for End-to-End Autonomous Driving},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Chitta2021ICCV,
author = {Kashyap Chitta and Aditya Prakash and Andreas Geiger},
title = {NEAT: Neural Attention Fields for End-to-End Autonomous Driving},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}

KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs
C. Reiser, S. Peng, Y. Liao and A. Geiger
International Conference on Computer Vision (ICCV), 2021
C. Reiser, S. Peng, Y. Liao and A. Geiger
International Conference on Computer Vision (ICCV), 2021
Abstract: NeRF synthesizes novel views of a scene with unprecedented quality by fitting a neural radiance field to RGB images. However, NeRF requires querying a deep Multi-Layer Perceptron (MLP) millions of times, leading to slow rendering times, even on modern GPUs. In this paper, we demonstrate that significant speed-ups are possible by utilizing thousands of tiny MLPs instead of one single large MLP. In our setting, each individual MLP only needs to represent parts of the scene, thus smaller and faster-to-evaluate MLPs can be used. By combining this divide-and-conquer strategy with further optimizations, rendering is accelerated by two orders of magnitude compared to the original NeRF model without incurring high storage costs. Further, using teacher-student distillation for training, we show that this speed-up can be achieved without sacrificing visual quality..
Latex Bibtex Citation:
@inproceedings{Reiser2021ICCV,
author = {Christian Reiser and Songyou Peng and Yiyi Liao and Andreas Geiger},
title = {KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Reiser2021ICCV,
author = {Christian Reiser and Songyou Peng and Yiyi Liao and Andreas Geiger},
title = {KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}

UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction (oral)
M. Oechsle, S. Peng and A. Geiger
International Conference on Computer Vision (ICCV), 2021
M. Oechsle, S. Peng and A. Geiger
International Conference on Computer Vision (ICCV), 2021
Abstract: Neural implicit 3D representations have emerged as a powerful paradigm for reconstructing surfaces from multi-view images and synthesizing novel views. Unfortunately, existing methods such as DVR or IDR require accurate per-pixel object masks as supervision. At the same time, neural radiance fields have revolutionized novel view synthesis. However, NeRF's estimated volume density does not admit accurate surface reconstruction. Our key insight is that implicit surface models and radiance fields can be formulated in a unified way, enabling both surface and volume rendering using the same model. This unified perspective enables novel, more efficient sampling procedures and the ability to reconstruct accurate surfaces without input masks. We compare our method on the DTU, BlendedMVS, and a synthetic indoor dataset. Our experiments demonstrate that we outperform NeRF in terms of reconstruction quality while performing on par with IDR without requiring masks.
Latex Bibtex Citation:
@inproceedings{Oechsle2021ICCV,
author = {Michael Oechsle and Songyou Peng and Andreas Geiger},
title = {UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Oechsle2021ICCV,
author = {Michael Oechsle and Songyou Peng and Andreas Geiger},
title = {UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}

SNARF: Differentiable Forward Skinning for Animating Non-Rigid Neural Implicit Shapes
X. Chen, Y. Zheng, M. Black, O. Hilliges and A. Geiger
International Conference on Computer Vision (ICCV), 2021
X. Chen, Y. Zheng, M. Black, O. Hilliges and A. Geiger
International Conference on Computer Vision (ICCV), 2021
Abstract: Neural implicit surface representations have emerged as a promising paradigm to capture 3D shapes in a continuous and resolution-independent manner. However, adapting them to articulated shapes is non-trivial. Existing approaches learn a backward warp field that maps deformed to canonical points. However, this is problematic since the backward warp field is pose dependent and thus requires large amounts of data to learn. To address this, we introduce SNARF, which combines the advantages of linear blend skinning (LBS) for polygonal meshes with those of neural implicit surfaces by learning a forward deformation field without direct supervision. This deformation field is defined in canonical, pose-independent space, allowing for generalization to unseen poses. Learning the deformation field from posed meshes alone is challenging since the correspondences of deformed points are defined implicitly and may not be unique under changes of topology. We propose a forward skinning model that finds all canonical correspondences of any deformed point using iterative root finding. We derive analytical gradients via implicit differentiation, enabling end-to-end training from 3D meshes with bone transformations. Compared to state-of-the-art neural implicit representations, our approach generalizes better to unseen poses while preserving accuracy. We demonstrate our method in challenging scenarios on (clothed) 3D humans in diverse and unseen poses.
Latex Bibtex Citation:
@inproceedings{Chen2021ICCV,
author = {Xu Chen and Yufeng Zheng and Michael Black and Otmar Hilliges and Andreas Geiger},
title = {SNARF: Differentiable Forward Skinning for Animating Non-Rigid Neural Implicit Shapes},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Chen2021ICCV,
author = {Xu Chen and Yufeng Zheng and Michael Black and Otmar Hilliges and Andreas Geiger},
title = {SNARF: Differentiable Forward Skinning for Animating Non-Rigid Neural Implicit Shapes},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}

SLIM: Self-Supervised LiDAR Scene Flow and Motion Segmentation (oral)
S. Baur, D. Emmerichs, F. Moosmann, P. Pinggera, B. Ommer and A. Geiger
International Conference on Computer Vision (ICCV), 2021
S. Baur, D. Emmerichs, F. Moosmann, P. Pinggera, B. Ommer and A. Geiger
International Conference on Computer Vision (ICCV), 2021
Abstract: Recently, several frameworks for self-supervised learning of 3D scene flow on point clouds have emerged. Scene flow inherently separates every scene into multiple moving agents and a large class of points following a single rigid sensor motion. However, existing methods do not leverage this property of the data in their self-supervised training routines which could improve and stabilize flow predictions. Based on the discrepancy between a robust rigid ego-motion estimate and a raw flow prediction, we generate a self-supervised motion segmentation signal. The predicted motion segmentation, in turn, is used by our algorithm to attend to stationary points for aggregation of motion information in static parts of the scene. We learn our model end-to-end by backpropagating gradients through Kabsch's algorithm and demonstrate that this leads to accurate ego-motion which in turn improves the scene flow estimate. Using our method, we show state-of-the-art results across multiple scene flow metrics for different real-world datasets, showcasing the robustness and generalizability of this approach. We further analyze the performance gain when performing joint motion segmentation and scene flow in an ablation study. We also present a novel network architecture for 3D LiDAR scene flow which is capable of handling an order of magnitude more points during training than previously possible.
Latex Bibtex Citation:
@inproceedings{Baur2021ICCV,
author = {Stefan Baur and David Emmerichs and Frank Moosmann and Peter Pinggera and Bjorn Ommer and Andreas Geiger},
title = {SLIM: Self-Supervised LiDAR Scene Flow and Motion Segmentation},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Baur2021ICCV,
author = {Stefan Baur and David Emmerichs and Frank Moosmann and Peter Pinggera and Bjorn Ommer and Andreas Geiger},
title = {SLIM: Self-Supervised LiDAR Scene Flow and Motion Segmentation},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}

Benchmarking Unsupervised Object Representations for Video Sequences
M. Weis, K. Chitta, Y. Sharma, W. Brendel, M. Bethge, A. Geiger and A. Ecker
Journal of Machine Learning Research (JMLR), 2021
M. Weis, K. Chitta, Y. Sharma, W. Brendel, M. Bethge, A. Geiger and A. Ecker
Journal of Machine Learning Research (JMLR), 2021
Abstract: Perceiving the world in terms of objects and tracking them through time is a crucial prerequisite for reasoning and scene understanding. Recently, several methods have been proposed for unsupervised learning of object-centric representations. However, since these models were evaluated on different downstream tasks, it remains unclear how they compare in terms of basic perceptual abilities such as detection, figure-ground segmentation and tracking of objects. To close this gap, we design a benchmark with four data sets of varying complexity and seven additional test sets featuring challenging tracking scenarios relevant for natural videos. Using this benchmark, we compare the perceptual abilities of four object-centric approaches: ViMON, a video-extension of MONet, based on recurrent spatial attention, OP3, which exploits clustering via spatial mixture models, as well as TBA and SCALOR, which use explicit factorization via spatial transformers. Our results suggest that the architectures with unconstrained latent representations learn more powerful representations in terms of object detection, segmentation and tracking than the spatial transformer based architectures. We also observe that none of the methods are able to gracefully handle the most challenging tracking scenarios despite their synthetic nature, suggesting that our benchmark may provide fruitful guidance towards learning more robust object-centric video representations.
Latex Bibtex Citation:
@article{Weis2021JMLR,
author = {Marissa Weis and Kashyap Chitta and Yash Sharma and Wieland Brendel and Matthias Bethge and Andreas Geiger and Alexander Ecker},
title = {Benchmarking Unsupervised Object Representations for Video Sequences},
journal = {Journal of Machine Learning Research (JMLR)},
year = {2021}
}
Latex Bibtex Citation:
@article{Weis2021JMLR,
author = {Marissa Weis and Kashyap Chitta and Yash Sharma and Wieland Brendel and Matthias Bethge and Andreas Geiger and Alexander Ecker},
title = {Benchmarking Unsupervised Object Representations for Video Sequences},
journal = {Journal of Machine Learning Research (JMLR)},
year = {2021}
}

Learning Cascaded Detection Tasks with Weakly-Supervised Domain Adaptation
N. Hanselmann, N. Schneider, B. Ortelt and A. Geiger
Intelligent Vehicles Symposium (IV), 2021
N. Hanselmann, N. Schneider, B. Ortelt and A. Geiger
Intelligent Vehicles Symposium (IV), 2021
Abstract: In order to handle the challenges of autonomous driving, deep learning has proven to be crucial in tackling increasingly complex tasks, such as 3D detection or instance segmentation. State-of-the-art approaches for image-based detection tasks tackle this complexity by operating in a cascaded fashion: they first extract a 2D bounding box based on which additional attributes, e.g. instance masks, are inferred. While these methods perform well, a key challenge remains the lack of accurate and cheap annotations for the growing variety of tasks. Synthetic data presents a promising solution but, despite the effort in domain adaptation research, the gap between synthetic and real data remains an open problem. In this work, we propose a weakly supervised domain adaptation setting which exploits the structure of cascaded detection tasks. In particular, we learn to infer the attributes solely from the source domain while leveraging 2D bounding boxes as weak labels in both domains to explain the domain shift. We further encourage domain-invariant features through class-wise feature alignment using ground-truth class information, which is not available in the unsupervised setting. As our experiments demonstrate, the approach is competitive with fully supervised settings while outperforming unsupervised adaptation approaches by a large margin.
Latex Bibtex Citation:
@inproceedings{Hanselmann2021IV,
author = {Niklas Hanselmann and Nick Schneider and Benedikt Ortelt and Andreas Geiger},
title = {Learning Cascaded Detection Tasks with Weakly-Supervised Domain Adaptation},
booktitle = {Intelligent Vehicles Symposium (IV)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Hanselmann2021IV,
author = {Niklas Hanselmann and Nick Schneider and Benedikt Ortelt and Andreas Geiger},
title = {Learning Cascaded Detection Tasks with Weakly-Supervised Domain Adaptation},
booktitle = {Intelligent Vehicles Symposium (IV)},
year = {2021}
}

Neural Parts: Learning Expressive 3D Shape Abstractions with Invertible Neural Networks
D. Paschalidou, A. Katharopoulos, A. Geiger and S. Fidler
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
D. Paschalidou, A. Katharopoulos, A. Geiger and S. Fidler
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
Abstract: Impressive progress in 3D shape extraction led to representations that can capture object geometries with high fidelity. In parallel, primitive-based methods seek to represent objects as semantically consistent part arrangements. However, due to the simplicity of existing primitive representations, these methods fail to accurately reconstruct 3D shapes using a small number of primitives/parts. We address the trade-off between reconstruction quality and number of parts with Neural Parts, a novel 3D primitive representation that defines primitives using an Invertible Neural Network (INN) which implements homeomorphic mappings between a sphere and the target object. The INN allows us to compute the inverse mapping of the homeomorphism, which in turn, enables the efficient computation of both the implicit surface function of a primitive and its mesh, without any additional post-processing. Our model learns to parse 3D objects into semantically consistent part arrangements without any part-level supervision. Evaluations on ShapeNet, D-FAUST and FreiHAND demonstrate that our primitives can capture complex geometries and thus simultaneously achieve geometrically accurate as well as interpretable reconstructions using an order of magnitude fewer primitives than state-of-the-art shape abstraction methods.
Latex Bibtex Citation:
@inproceedings{Paschalidou2021CVPR,
author = {Despoina Paschalidou and Angelos Katharopoulos and Andreas Geiger and Sanja Fidler},
title = {Neural Parts: Learning Expressive 3D Shape Abstractions with Invertible Neural Networks},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Paschalidou2021CVPR,
author = {Despoina Paschalidou and Angelos Katharopoulos and Andreas Geiger and Sanja Fidler},
title = {Neural Parts: Learning Expressive 3D Shape Abstractions with Invertible Neural Networks},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}

Locally Aware Piecewise Transformation Fields for 3D Human Mesh Registration
S. Wang, A. Geiger and S. Tang
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
S. Wang, A. Geiger and S. Tang
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
Abstract: Registering point clouds of dressed humans to parametric human models is a challenging task in computer vision. Traditional approaches often rely on heavily engineered pipelines that require accurate manual initialization of human poses and tedious post-processing. More recently, learning-based methods are proposed in hope to automate this process. We observe that pose initialization is key to accurate registration but existing methods often fail to provide accurate pose initialization. One major obstacle is that, despite recent effort on rotation representation learning in neural networks, regressing joint rotations from point clouds or images of humans is still very challenging. To this end, we propose novel piecewise transformation fields (PTF), a set of functions that learn 3D translation vectors to map any query point in posed space to its correspond position in rest-pose space. We combine PTF with multi-class occupancy networks, obtaining a novel learning-based framework that learns to simultaneously predict shape and per-point correspondences between the posed space and the canonical space for clothed human. Our key insight is that the translation vector for each query point can be effectively estimated using the point-aligned local features; consequently, rigid per bone transformations and joint rotations can be obtained efficiently via a least-square fitting given the estimated point correspondences, circumventing the challenging task of directly regressing joint rotations from neural networks. Furthermore, the proposed PTF facilitate canonicalized occupancy estimation, which greatly improves generalization capability and results in more accurate surface reconstruction with only half of the parameters compared with the state-of-the-art. Both qualitative and quantitative studies show that fitting parametric models with poses initialized by our network results in much better registration quality, especially for extreme poses.
Latex Bibtex Citation:
@inproceedings{Wang2021CVPR,
author = {Shaofei Wang and Andreas Geiger and Siyu Tang},
title = {Locally Aware Piecewise Transformation Fields for 3D Human Mesh Registration},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Wang2021CVPR,
author = {Shaofei Wang and Andreas Geiger and Siyu Tang},
title = {Locally Aware Piecewise Transformation Fields for 3D Human Mesh Registration},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}

Multi-Modal Fusion Transformer for End-to-End Autonomous Driving
A. Prakash, K. Chitta and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
A. Prakash, K. Chitta and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
Abstract: How should representations from complementary sensors be integrated for autonomous driving? Geometry-based sensor fusion has shown great promise for perception tasks such as object detection and motion forecasting. However, for the actual driving task, the global context of the 3D scene is key, e.g. a change in traffic light state can affect the behavior of a vehicle geometrically distant from that traffic light. Geometry alone may therefore be insufficient for effectively fusing representations in end-to-end driving models. In this work, we demonstrate that existing sensor fusion methods under-perform in the presence of a high density of dynamic agents and complex scenarios, which require global contextual reasoning, such as handling traffic oncoming from multiple directions at uncontrolled intersections. Therefore, we propose TransFuser, a novel Multi-Modal Fusion Transformer, to integrate image and LiDAR representations using attention. We experimentally validate the efficacy of our approach in urban settings involving complex scenarios using the CARLA urban driving simulator. Our approach achieves state-of-the-art driving performance while reducing collisions by 80% compared to geometry-based fusion.
Latex Bibtex Citation:
@inproceedings{Prakash2021CVPR,
author = {Aditya Prakash and Kashyap Chitta and Andreas Geiger},
title = {Multi-Modal Fusion Transformer for End-to-End Autonomous Driving},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Prakash2021CVPR,
author = {Aditya Prakash and Kashyap Chitta and Andreas Geiger},
title = {Multi-Modal Fusion Transformer for End-to-End Autonomous Driving},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}

GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields (oral, best paper award)
M. Niemeyer and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
M. Niemeyer and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
Abstract: Deep generative models allow for photorealistic image synthesis at high resolutions. But for many applications, this is not enough: content creation also needs to be controllable. While several recent works investigate how to disentangle underlying factors of variation in the data, most of them operate in 2D and hence ignore that our world is three-dimensional. Further, only few works consider the compositional nature of scenes. Our key hypothesis is that incorporating a compositional 3D scene representation into the generative model leads to more controllable image synthesis. Representing scenes as compositional generative neural feature fields allows us to disentangle one or multiple objects from the background as well as individual objects' shapes and appearances while learning from unstructured and unposed image collections without any additional supervision. Combining this scene representation with a neural rendering pipeline yields a fast and realistic image synthesis model. As evidenced by our experiments, our model is able to disentangle individual objects and allows for translating and rotating them in the scene as well as changing the camera pose.
Latex Bibtex Citation:
@inproceedings{Niemeyer2021CVPR,
author = {Michael Niemeyer and Andreas Geiger},
title = {GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Niemeyer2021CVPR,
author = {Michael Niemeyer and Andreas Geiger},
title = {GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}

SMD-Nets: Stereo Mixture Density Networks
F. Tosi, Y. Liao, C. Schmitt and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
F. Tosi, Y. Liao, C. Schmitt and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
Abstract: Despite stereo matching accuracy has greatly improved by deep learning in the last few years, recovering sharp boundaries and high-resolution outputs efficiently remains challenging. In this paper, we propose Stereo Mixture Density Networks (SMD-Nets), a simple yet effective learning framework compatible with a wide class of 2D and 3D architectures which ameliorates both issues. Specifically, we exploit bimodal mixture densities as output representation and show that this allows for sharp and precise disparity estimates near discontinuities while explicitly modeling the aleatoric uncertainty inherent in the observations. Moreover, we formulate disparity estimation as a continuous problem in the image domain, allowing our model to query disparities at arbitrary spatial precision. We carry out comprehensive experiments on a new high-resolution and highly realistic synthetic stereo dataset, consisting of stereo pairs at 8Mpx resolution, as well as on real-world stereo datasets. Our experiments demonstrate increased depth accuracy near object boundaries and prediction of ultra high-resolution disparity maps on standard GPUs. We demonstrate the flexibility of our technique by improving the performance of a variety of stereo backbones.
Latex Bibtex Citation:
@inproceedings{Tosi2021CVPR,
author = {Fabio Tosi and Yiyi Liao and Carolin Schmitt and Andreas Geiger},
title = {SMD-Nets: Stereo Mixture Density Networks},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Tosi2021CVPR,
author = {Fabio Tosi and Yiyi Liao and Carolin Schmitt and Andreas Geiger},
title = {SMD-Nets: Stereo Mixture Density Networks},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}

Counterfactual Generative Networks
A. Sauer and A. Geiger
International Conference on Learning Representations (ICLR), 2021
A. Sauer and A. Geiger
International Conference on Learning Representations (ICLR), 2021
Abstract: Neural networks are prone to learning shortcuts -they often model simple correlations, ignoring more complex ones that potentially generalize better. Prior works on image classification show that instead of learning a connection to object shape, deep classifiers tend to exploit spurious correlations with low-level texture or the background for solving the classification task. In this work, we take a step towards more robust and interpretable classifiers that explicitly expose the task's causal structure. Building on current advances in deep generative modeling, we propose to decompose the image generation process into independent causal mechanisms that we train without direct supervision. By exploiting appropriate inductive biases, these mechanisms disentangle object shape, object texture, and background; hence, they allow for generating counterfactual images. We demonstrate the ability of our model to generate such images on MNIST and ImageNet. Further, we show that the counterfactual images can improve out-of-distribution robustness with a marginal drop in performance on the original classification task, despite being synthetic. Lastly, our generative model can be trained efficiently on a single GPU, exploiting common pre-trained models as inductive biases.
Latex Bibtex Citation:
@inproceedings{Sauer2021ICLR,
author = {Axel Sauer and Andreas Geiger},
title = {Counterfactual Generative Networks},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Sauer2021ICLR,
author = {Axel Sauer and Andreas Geiger},
title = {Counterfactual Generative Networks},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2021}
}

Learning Steering Kernels for Guided Depth Completion
L. Liu, Y. Liao, Y. Wang, A. Geiger and Y. Liu
Transactions on Image Processing (TIP), 2021
L. Liu, Y. Liao, Y. Wang, A. Geiger and Y. Liu
Transactions on Image Processing (TIP), 2021
Abstract: This paper addresses the guided depth completion task in which the goal is to predict a dense depth map given a guidance RGB image and sparse depth measurements. Recent advances on this problem nurture hopes that one day we can acquire accurate and dense depth at a very low cost. A major challenge of guided depth completion is to effectively make use of extremely sparse measurements, eg, measurements covering less than 1% of the image pixels. In this paper, we propose a fully differentiable model that avoids convolving on sparse tensors by jointly learning depth interpolation and refinement. More specifically, we propose a differentiable kernel regression layer that interpolates the sparse depth measurements via learned kernels. We further refine the interpolated depth map using a residual depth refinement layer which leads to improved performance compared to learning absolute depth prediction using a vanilla network. We provide experimental evidence that our differentiable kernel regression layer not only enables end-to-end training from very sparse measurements using standard convolutional network architectures, but also leads to better depth interpolation results compared to existing heuristically motivated methods. We demonstrate that our method outperforms many state-of-the-art guided depth completion techniques on both NYUv2 and KITTI. We further show the generalization ability of our method with respect to the density and spatial statistics of the sparse depth measurements.
Latex Bibtex Citation:
@article{Liu2021TIP,
author = {Lina Liu and Yiyi Liao and Yue Wang and Andreas Geiger and Yong Liu},
title = {Learning Steering Kernels for Guided Depth Completion},
journal = {Transactions on Image Processing (TIP)},
year = {2021}
}
Latex Bibtex Citation:
@article{Liu2021TIP,
author = {Lina Liu and Yiyi Liao and Yue Wang and Andreas Geiger and Yong Liu},
title = {Learning Steering Kernels for Guided Depth Completion},
journal = {Transactions on Image Processing (TIP)},
year = {2021}
}
2020

GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis
K. Schwarz, Y. Liao, M. Niemeyer and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2020
K. Schwarz, Y. Liao, M. Niemeyer and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2020
Abstract: While 2D generative adversarial networks have enabled high-resolution image synthesis, they largely lack an understanding of the 3D world and the image formation process. Thus, they do not provide precise control over camera viewpoint or object pose. To address this problem, several recent approaches leverage intermediate voxel-based representations in combination with differentiable rendering. However, existing methods either produce low image resolution or fall short in disentangling camera and scene properties, eg, the object identity may vary with the viewpoint. In this paper, we propose a generative model for radiance fields which have recently proven successful for novel view synthesis of a single scene. In contrast to voxel-based representations, radiance fields are not confined to a coarse discretization of the 3D space, yet allow for disentangling camera and scene properties while degrading gracefully in the presence of reconstruction ambiguity. By introducing a multi-scale patch-based discriminator, we demonstrate synthesis of high-resolution images while training our model from unposed 2D images alone. We systematically analyze our approach on several challenging synthetic and real-world datasets. Our experiments reveal that radiance fields are a powerful representation for generative image synthesis, leading to 3D consistent models that render with high fidelity.
Latex Bibtex Citation:
@inproceedings{Schwarz2020NEURIPS,
author = {Katja Schwarz and Yiyi Liao and Michael Niemeyer and Andreas Geiger},
title = {GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Schwarz2020NEURIPS,
author = {Katja Schwarz and Yiyi Liao and Michael Niemeyer and Andreas Geiger},
title = {GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2020}
}

Learning Implicit Surface Light Fields
M. Oechsle, M. Niemeyer, C. Reiser, L. Mescheder, T. Strauss and A. Geiger
International Conference on 3D Vision (3DV), 2020
M. Oechsle, M. Niemeyer, C. Reiser, L. Mescheder, T. Strauss and A. Geiger
International Conference on 3D Vision (3DV), 2020
Abstract: Implicit representations of 3D objects have recently achieved impressive results on learning-based 3D reconstruction tasks. While existing works use simple texture models to represent object appearance, photo-realistic image synthesis requires reasoning about the complex interplay of light, geometry and surface properties. In this work, we propose a novel implicit representation for capturing the visual appearance of an object in terms of its surface light field. In contrast to existing representations, our implicit model represents surface light fields in a continuous fashion and independent of the geometry. Moreover, we condition the surface light field with respect to the location and color of a small light source. Compared to traditional surface light field models, this allows us to manipulate the light source and relight the object using environment maps. We further demonstrate the capabilities of our model to predict the visual appearance of an unseen object from a single real RGB image and corresponding 3D shape information. As evidenced by our experiments, our model is able to infer rich visual appearance including shadows and specular reflections. Finally, we show that the proposed representation can be embedded into a variational auto-encoder for generating novel appearances that conform to the specified illumination conditions.
Latex Bibtex Citation:
@inproceedings{Oechsle2020THREEDV,
author = {Michael Oechsle and Michael Niemeyer and Christian Reiser and Lars Mescheder and Thilo Strauss and Andreas Geiger},
title = {Learning Implicit Surface Light Fields},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Oechsle2020THREEDV,
author = {Michael Oechsle and Michael Niemeyer and Christian Reiser and Lars Mescheder and Thilo Strauss and Andreas Geiger},
title = {Learning Implicit Surface Light Fields},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2020}
}

Intrinsic Autoencoders for Joint Neural Rendering and Intrinsic Image Decomposition
H. Alhaija, S. Mustikovela, V. Jampani, J. Thies, M. Niessner, A. Geiger and C. Rother
International Conference on 3D Vision (3DV), 2020
H. Alhaija, S. Mustikovela, V. Jampani, J. Thies, M. Niessner, A. Geiger and C. Rother
International Conference on 3D Vision (3DV), 2020
Abstract: Neural rendering techniques promise efficient photo-realistic image synthesis while providing rich control over scene parameters by learning the physical image formation process. While several supervised methods have been pro-posed for this task, acquiring a dataset of images with accurately aligned 3D models is very difficult. The main contribution of this work is to lift this restriction by training a neural rendering algorithm from unpaired data. We pro-pose an auto encoder for joint generation of realistic images from synthetic 3D models while simultaneously decomposing real images into their intrinsic shape and appearance properties. In contrast to a traditional graphics pipeline, our approach does not require to specify all scene properties, such as material parameters and lighting by hand.Instead, we learn photo-realistic deferred rendering from a small set of 3D models and a larger set of unaligned real images, both of which are easy to acquire in practice. Simultaneously, we obtain accurate intrinsic decompositions of real images while not requiring paired ground truth. Our experiments confirm that a joint treatment of rendering and de-composition is indeed beneficial and that our approach out-performs state-of-the-art image-to-image translation base-lines both qualitatively and quantitatively.
Latex Bibtex Citation:
@inproceedings{Alhaija2020THREEDV,
author = {Hassan Alhaija and Siva Mustikovela and Varun Jampani and Justus Thies and Matthias Niessner and Andreas Geiger and Carsten Rother},
title = {Intrinsic Autoencoders for Joint Neural Rendering and Intrinsic Image Decomposition},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Alhaija2020THREEDV,
author = {Hassan Alhaija and Siva Mustikovela and Varun Jampani and Justus Thies and Matthias Niessner and Andreas Geiger and Carsten Rother},
title = {Intrinsic Autoencoders for Joint Neural Rendering and Intrinsic Image Decomposition},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2020}
}

HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking
J. Luiten, A. Osep, P. Dendorfer, P. Torr, A. Geiger, L. Leal-Taixe and B. Leibe
International Journal of Computer Vision (IJCV), 2020
J. Luiten, A. Osep, P. Dendorfer, P. Torr, A. Geiger, L. Leal-Taixe and B. Leibe
International Journal of Computer Vision (IJCV), 2020
Abstract: Multi-Object Tracking (MOT) has been notoriously difficult to evaluate. Previous metrics overemphasize the importance of either detection or association. To address this, we present a novel MOT evaluation metric, HOTA (Higher Order Tracking Accuracy), which explicitly balances the effect of performing accurate detection, association and localization into a single unified metric for comparing trackers. HOTA decomposes into a family of sub-metrics which are able to evaluate each of five basic error types separately, which enables clear analysis of tracking performance. We evaluate the effectiveness of HOTA on the MOTChallenge benchmark, and show that it is able to capture important aspects of MOT performance not previously taken into account by established metrics. Furthermore, we show HOTA scores better align with human visual evaluation of tracking performance.
Latex Bibtex Citation:
@article{Luiten2020IJCV,
author = {Jonathon Luiten and Aljosa Osep and Patrick Dendorfer and Philip Torr and Andreas Geiger and Laura Leal-Taixe and Bastian Leibe},
title = {HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking},
journal = {International Journal of Computer Vision (IJCV)},
year = {2020}
}
Latex Bibtex Citation:
@article{Luiten2020IJCV,
author = {Jonathon Luiten and Aljosa Osep and Patrick Dendorfer and Philip Torr and Andreas Geiger and Laura Leal-Taixe and Bastian Leibe},
title = {HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking},
journal = {International Journal of Computer Vision (IJCV)},
year = {2020}
}

Label Efficient Visual Abstractions for Autonomous Driving
A. Behl, K. Chitta, A. Prakash, E. Ohn-Bar and A. Geiger
International Conference on Intelligent Robots and Systems (IROS), 2020
A. Behl, K. Chitta, A. Prakash, E. Ohn-Bar and A. Geiger
International Conference on Intelligent Robots and Systems (IROS), 2020
Abstract: It is well known that semantic segmentation can be used as an effective intermediate representation for learning driving policies. However, the task of street scene semantic segmentation requires expensive annotations. Furthermore, segmentation algorithms are often trained irrespective of the actual driving task, using auxiliary image-space loss functions which are not guaranteed to maximize driving metrics such as safety or distance traveled per intervention. In this work, we seek to quantify the impact of reducing segmentation annotation costs on learned behavior cloning agents. We analyze several segmentation-based intermediate representations. We use these visual abstractions to systematically study the trade-off between annotation efficiency and driving performance, ie, the types of classes labeled, the number of image samples used to learn the visual abstraction model, and their granularity (eg, object masks vs. 2D bounding boxes). Our analysis uncovers several practical insights into how segmentation-based visual abstractions can be exploited in a more label efficient manner. Surprisingly, we find that state-of-the-art driving performance can be achieved with orders of magnitude reduction in annotation cost. Beyond label efficiency, we find several additional training benefits when leveraging visual abstractions, such as a significant reduction in the variance of the learned policy when compared to state-of-the-art end-to-end driving models.
Latex Bibtex Citation:
@inproceedings{Behl2020IROS,
author = {Aseem Behl and Kashyap Chitta and Aditya Prakash and Eshed Ohn-Bar and Andreas Geiger},
title = {Label Efficient Visual Abstractions for Autonomous Driving},
booktitle = {International Conference on Intelligent Robots and Systems (IROS)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Behl2020IROS,
author = {Aseem Behl and Kashyap Chitta and Aditya Prakash and Eshed Ohn-Bar and Andreas Geiger},
title = {Label Efficient Visual Abstractions for Autonomous Driving},
booktitle = {International Conference on Intelligent Robots and Systems (IROS)},
year = {2020}
}

Category Level Object Pose Estimation via Neural Analysis-by-Synthesis
X. Chen, Z. Dong, J. Song, A. Geiger and O. Hilliges
European Conference on Computer Vision (ECCV), 2020
X. Chen, Z. Dong, J. Song, A. Geiger and O. Hilliges
European Conference on Computer Vision (ECCV), 2020
Abstract: Many object pose estimation algorithms rely on the analysis-by-synthesis framework which requires explicit representations of individual object instances. In this paper we combine a gradient-based fitting procedure with a parametric neural image synthesis module that is capable of implicitly representing the appearance, shape and pose of entire object categories, thus rendering the need for explicit CAD models per object instance unnecessary. The image synthesis network is designed to efficiently span the pose configuration space so that model capacity can be used to capture the shape and local appearance (i.e., texture) variations jointly. At inference time the synthesized images are compared to the target via an appearance based loss and the error signal is backpropagated through the network to the input parameters. Keeping the network parameters fixed, this allows for iterative optimization of the object pose, shape and appearance in a joint manner and we experimentally show that the method can recover orientation of objects with high accuracy from 2D images alone. When provided with depth measurements, to overcome scale ambiguities, the method can accurately recover the full 6DOF pose successfully.
Latex Bibtex Citation:
@inproceedings{Chen2020ECCV,
author = {Xu Chen and Zijian Dong and Jie Song and Andreas Geiger and Otmar Hilliges},
title = {Category Level Object Pose Estimation via Neural Analysis-by-Synthesis},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Chen2020ECCV,
author = {Xu Chen and Zijian Dong and Jie Song and Andreas Geiger and Otmar Hilliges},
title = {Category Level Object Pose Estimation via Neural Analysis-by-Synthesis},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2020}
}

Convolutional Occupancy Networks (spotlight)
S. Peng, M. Niemeyer, L. Mescheder, M. Pollefeys and A. Geiger
European Conference on Computer Vision (ECCV), 2020
S. Peng, M. Niemeyer, L. Mescheder, M. Pollefeys and A. Geiger
European Conference on Computer Vision (ECCV), 2020
Abstract: Recently, implicit neural representations have gained popularity for learning-based 3D reconstruction. While demonstrating promising results, most implicit approaches are limited to comparably simple geometry of single objects and do not scale to more complicated or large-scale scenes. The key limiting factor of implicit methods is their simple fully-connected network architecture which does not allow for integrating local information in the observations or incorporating inductive biases such as translational equivariance. In this paper, we propose Convolutional Occupancy Networks, a more flexible implicit representation for detailed reconstruction of objects and 3D scenes. By combining convolutional encoders with implicit occupancy decoders, our model incorporates inductive biases, enabling structured reasoning in 3D space. We investigate the effectiveness of the proposed representation by reconstructing complex geometry from noisy point clouds and low-resolution voxel representations. We empirically find that our method enables the fine-grained implicit 3D reconstruction of single objects, scales to large indoor scenes, and generalizes well from synthetic to real data.
Latex Bibtex Citation:
@inproceedings{Peng2020ECCV,
author = {Songyou Peng and Michael Niemeyer and Lars Mescheder and Marc Pollefeys and Andreas Geiger},
title = {Convolutional Occupancy Networks},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Peng2020ECCV,
author = {Songyou Peng and Michael Niemeyer and Lars Mescheder and Marc Pollefeys and Andreas Geiger},
title = {Convolutional Occupancy Networks},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2020}
}

Learning Neural Light Transport
P. Sanzenbacher, L. Mescheder and A. Geiger
Arxiv, 2020
P. Sanzenbacher, L. Mescheder and A. Geiger
Arxiv, 2020
Abstract: In recent years, deep generative models have gained significance due to their ability to synthesize natural-looking images with applications ranging from virtual reality to data augmentation for training computer vision models. While existing models are able to faithfully learn the image distribution of the training set, they often lack controllability as they operate in 2D pixel space and do not model the physical image formation process. In this work, we investigate the importance of 3D reasoning for photorealistic rendering. We present an approach for learning light transport in static and dynamic 3D scenes using a neural network with the goal of predicting photorealistic images. In contrast to existing approaches that operate in the 2D image domain, our approach reasons in both 3D and 2D space, thus enabling global illumination effects and manipulation of 3D scene geometry. Experimentally, we find that our model is able to produce photorealistic renderings of static and dynamic scenes. Moreover, it compares favorably to baselines which combine path tracing and image denoising at the same computational budget.
Latex Bibtex Citation:
@article{Sanzenbacher2020ARXIV,
author = {Paul Sanzenbacher and Lars Mescheder and Andreas Geiger},
title = {Learning Neural Light Transport},
journal = {Arxiv},
year = {2020}
}
Latex Bibtex Citation:
@article{Sanzenbacher2020ARXIV,
author = {Paul Sanzenbacher and Lars Mescheder and Andreas Geiger},
title = {Learning Neural Light Transport},
journal = {Arxiv},
year = {2020}
}

Computer Vision for Autonomous Vehicles: Problems, Datasets and State of the Art
J. Janai, F. Güney, A. Behl and A. Geiger
Foundations and Trends in Computer Graphics and Vision, 2020
J. Janai, F. Güney, A. Behl and A. Geiger
Foundations and Trends in Computer Graphics and Vision, 2020
Abstract: Recent years have witnessed enormous progress in AI-related fields such as computer vision, machine learning, and autonomous vehicles. As with any rapidly growing field, it becomes increasingly difficult to stay up-to-date or enter the field as a beginner. While several survey papers on particular sub-problems have appeared, no comprehensive survey on problems, datasets, and methods in computer vision for autonomous vehicles has been published. This monograph attempts to narrow this gap by providing a survey on the state-of-the-art datasets and techniques. Our survey includes both the historically most relevant literature as well as the current state of the art on several specific topics, including recognition, reconstruction, motion estimation, tracking, scene understanding, and end-to-end learning for autonomous driving. Towards this goal, we analyze the performance of the state of the art on several challenging benchmarking datasets, including KITTI, MOT, and Cityscapes. Besides, we discuss open problems and current research challenges. To ease accessibility and accommodate missing references, we also provide a website that allows navigating topics as well as methods and provides additional information.
Latex Bibtex Citation:
@book{Janai2020,
author = {Joel Janai and Fatma Güney and Aseem Behl and Andreas Geiger},
title = {Computer Vision for Autonomous Vehicles: Problems, Datasets and State of the Art},
publisher = {Foundations and Trends in Computer Graphics and Vision},
year = {2020}
}
Latex Bibtex Citation:
@book{Janai2020,
author = {Joel Janai and Fatma Güney and Aseem Behl and Andreas Geiger},
title = {Computer Vision for Autonomous Vehicles: Problems, Datasets and State of the Art},
publisher = {Foundations and Trends in Computer Graphics and Vision},
year = {2020}
}

Learning Situational Driving
E. Ohn-Bar, A. Prakash, A. Behl, K. Chitta and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
E. Ohn-Bar, A. Prakash, A. Behl, K. Chitta and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
Abstract: Human drivers have a remarkable ability to drive in diverse visual conditions and situations, e.g., from maneuvering in rainy, limited visibility conditions with no lane markings to turning in a busy intersection while yielding to pedestrians. In contrast, we find that state-of-the-art sensorimotor driving models struggle when encountering diverse settings with varying relationships between observation and action. To generalize when making decisions across diverse conditions, humans leverage multiple types of situation-specific reasoning and learning strategies. Motivated by this observation, we develop a framework for learning a situational driving policy that effectively captures reasoning under varying types of scenarios. Our key idea is to learn a mixture model with a set of policies that can capture multiple driving modes. We first optimize the mixture model through behavior cloning, and show it to result in significant gains in terms of driving performance in diverse conditions. We then refine the model by directly optimizing for the driving task itself, i.e., supervised with the navigation task reward. Our method is more scalable than methods assuming access to privileged information, e.g., perception labels, as it only assumes demonstration and reward-based supervision. We achieve over 98% success rate on the CARLA driving benchmark as well as state-of-the-art performance on a newly introduced generalization benchmark.
Latex Bibtex Citation:
@inproceedings{Ohn-Bar2020CVPR,
author = {Eshed Ohn-Bar and Aditya Prakash and Aseem Behl and Kashyap Chitta and Andreas Geiger},
title = {Learning Situational Driving},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Ohn-Bar2020CVPR,
author = {Eshed Ohn-Bar and Aditya Prakash and Aseem Behl and Kashyap Chitta and Andreas Geiger},
title = {Learning Situational Driving},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}

On Joint Estimation of Pose, Geometry and svBRDF from a Handheld Scanner
C. Schmitt, S. Donne, G. Riegler, V. Koltun and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
C. Schmitt, S. Donne, G. Riegler, V. Koltun and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
Abstract: We propose a novel formulation for joint recovery of camera pose, object geometry and spatially-varying BRDF. The input to our approach is a sequence of RGB-D images captured by a mobile, hand-held scanner that actively illuminates the scene with point light sources. Compared to previous works that jointly estimate geometry and materials from a hand-held scanner, we formulate this problem using a single objective function that can be minimized using off-the-shelf gradient-based solvers. By integrating material clustering as a differentiable operation into the optimization process, we avoid pre-processing heuristics and demonstrate that our model is able to determine the correct number of specular materials independently. We provide a study on the importance of each component in our formulation and on the requirements of the initial geometry. We show that optimizing over the poses is crucial for accurately recovering fine details and that our approach naturally results in a semantically meaningful material segmentation.
Latex Bibtex Citation:
@inproceedings{Schmitt2020CVPR,
author = {Carolin Schmitt and Simon Donne and Gernot Riegler and Vladlen Koltun and Andreas Geiger},
title = {On Joint Estimation of Pose, Geometry and svBRDF from a Handheld Scanner},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Schmitt2020CVPR,
author = {Carolin Schmitt and Simon Donne and Gernot Riegler and Vladlen Koltun and Andreas Geiger},
title = {On Joint Estimation of Pose, Geometry and svBRDF from a Handheld Scanner},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}

Exploring Data Aggregation in Policy Learning for Vision-based Urban Autonomous Driving
A. Prakash, A. Behl, E. Ohn-Bar, K. Chitta and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
A. Prakash, A. Behl, E. Ohn-Bar, K. Chitta and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
Abstract: Data aggregation techniques can significantly improve vision-based policy learning within a training environment, e.g., learning to drive in a specific simulation condition. However, as on-policy data is sequentially sampled and added in an iterative manner, the policy can specialize and overfit to the training conditions. For real-world applications, it is useful for the learned policy to generalize to novel scenarios that differ from the training conditions. To improve policy learning while maintaining robustness when training end-to-end driving policies, we perform an extensive analysis of data aggregation techniques in the CARLA environment. We demonstrate how the majority of them have poor generalization performance, and develop a novel approach with empirically better generalization performance compared to existing techniques. Our two key ideas are (1) to sample critical states from the collected on-policy data based on the utility they provide to the learned policy in terms of driving behavior, and (2) to incorporate a replay buffer which progressively focuses on the high uncertainty regions of the policy's state distribution. We evaluate the proposed approach on the CARLA NoCrash benchmark, focusing on the most challenging driving scenarios with dense pedestrian and vehicle traffic. Our approach improves driving success rate by 16% over state-of-the-art, achieving 87% of the expert performance while also reducing the collision rate by an order of magnitude without the use of any additional modality, auxiliary tasks, architectural modifications or reward from the environment.
Latex Bibtex Citation:
@inproceedings{Prakash2020CVPR,
author = {Aditya Prakash and Aseem Behl and Eshed Ohn-Bar and Kashyap Chitta and Andreas Geiger},
title = {Exploring Data Aggregation in Policy Learning for Vision-based Urban Autonomous Driving},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Prakash2020CVPR,
author = {Aditya Prakash and Aseem Behl and Eshed Ohn-Bar and Kashyap Chitta and Andreas Geiger},
title = {Exploring Data Aggregation in Policy Learning for Vision-based Urban Autonomous Driving},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}

Learning Unsupervised Hierarchical Part Decomposition of 3D Objects from a Single RGB Image
D. Paschalidou, L. Gool and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
D. Paschalidou, L. Gool and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
Abstract: Humans perceive the 3D world as a set of distinct objects that are characterized by various low-level (geometry, reflectance) and high-level (connectivity, adjacency, symmetry) properties. Recent methods based on convolutional neural networks (CNNs) demonstrated impressive progress in 3D reconstruction, even when using a single 2D image as input. However, the majority of these methods focuses on recovering the local 3D geometry of an object without considering its part-based decomposition or relations between parts. We address this challenging problem by proposing a novel formulation that allows to jointly recover the geometry of a 3D object as a set of primitives as well as their latent hierarchical structure without part-level supervision. Our model recovers the higher level structural decomposition of various objects in the form of a binary tree of primitives, where simple parts are represented with fewer primitives and more complex parts are modeled with more components. Our experiments on the ShapeNet and D-FAUST datasets demonstrate that considering the organization of parts indeed facilitates reasoning about 3D geometry.
Latex Bibtex Citation:
@inproceedings{Paschalidou2020CVPR,
author = {Despoina Paschalidou and Luc Gool and Andreas Geiger},
title = {Learning Unsupervised Hierarchical Part Decomposition of 3D Objects from a Single RGB Image},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Paschalidou2020CVPR,
author = {Despoina Paschalidou and Luc Gool and Andreas Geiger},
title = {Learning Unsupervised Hierarchical Part Decomposition of 3D Objects from a Single RGB Image},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}

Differentiable Volumetric Rendering: Learning Implicit 3D Representations without 3D Supervision
M. Niemeyer, L. Mescheder, M. Oechsle and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
M. Niemeyer, L. Mescheder, M. Oechsle and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
Abstract: Learning-based 3D reconstruction methods have shown impressive results. However, most methods require 3D supervision which is often hard to obtain for real-world datasets. Recently, several works have proposed differentiable rendering techniques to train reconstruction models from RGB images. Unfortunately, these approaches are currently restricted to voxel- and mesh-based representations, suffering from discretization or low resolution. In this work, we propose a differentiable rendering formulation for implicit shape and texture representations. Implicit representations have recently gained popularity as they represent shape and texture continuously. Our key insight is that depth gradients can be derived analytically using the concept of implicit differentiation. This allows us to learn implicit shape and texture representations directly from RGB images. We experimentally show that our single-view reconstructions rival those learned with full 3D supervision. Moreover, we find that our method can be used for multi-view 3D reconstruction, directly resulting in watertight meshes.
Latex Bibtex Citation:
@inproceedings{Niemeyer2020CVPR,
author = {Michael Niemeyer and Lars Mescheder and Michael Oechsle and Andreas Geiger},
title = {Differentiable Volumetric Rendering: Learning Implicit 3D Representations without 3D Supervision},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Niemeyer2020CVPR,
author = {Michael Niemeyer and Lars Mescheder and Michael Oechsle and Andreas Geiger},
title = {Differentiable Volumetric Rendering: Learning Implicit 3D Representations without 3D Supervision},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}

Towards Unsupervised Learning of Generative Models for 3D Controllable Image Synthesis
Y. Liao, K. Schwarz, L. Mescheder and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
Y. Liao, K. Schwarz, L. Mescheder and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
Abstract: In recent years, Generative Adversarial Networks have achieved impressive results in photorealistic image synthesis. This progress nurtures hopes that one day the classical rendering pipeline can be replaced by efficient models that are learned directly from images. However, current image synthesis models operate in the 2D domain where disentangling 3D properties such as camera viewpoint or object pose is challenging. Furthermore, they lack an interpretable and controllable representation. Our key hypothesis is that the image generation process should be modeled in 3D space as the physical world surrounding us is intrinsically three-dimensional. We define the new task of 3D controllable image synthesis and propose an approach for solving it by reasoning both in 3D space and in the 2D image domain. We demonstrate that our model is able to disentangle latent 3D factors of simple multi-object scenes in an unsupervised fashion from raw images. Compared to pure 2D baselines, it allows for synthesizing scenes that are consistent wrt. changes in viewpoint or object pose. We further evaluate various 3D representations in terms of their usefulness for this challenging task.
Latex Bibtex Citation:
@inproceedings{Liao2020CVPR,
author = {Yiyi Liao and Katja Schwarz and Lars Mescheder and Andreas Geiger},
title = {Towards Unsupervised Learning of Generative Models for 3D Controllable Image Synthesis},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Liao2020CVPR,
author = {Yiyi Liao and Katja Schwarz and Lars Mescheder and Andreas Geiger},
title = {Towards Unsupervised Learning of Generative Models for 3D Controllable Image Synthesis},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}

Self-Supervised Linear Motion Deblurring
P. Liu, J. Janai, M. Pollefeys, T. Sattler and A. Geiger
Robotics and Automation Letters (RA-L), 2020
P. Liu, J. Janai, M. Pollefeys, T. Sattler and A. Geiger
Robotics and Automation Letters (RA-L), 2020
Abstract: Motion blurry images challenge many computer vision algorithms, e.g., feature detection, motion estimation, or object recognition. Deep convolutional neural networks are state-of-the-art for image deblurring. However, obtaining training data with corresponding sharp and blurry image pairs can be difficult. In this paper, we present a differentiable reblur model for self-supervised motion deblurring, which enables the network to learn from real-world blurry image sequences without relying on sharp images for supervision. Our key insight is that motion cues obtained from consecutive images yield sufficient information to inform the deblurring task. We therefore formulate deblurring as an inverse rendering problem, taking into account the physical image formation process: we first predict two deblurred images from which we estimate the corresponding optical flow. Using these predictions, we re-render the blurred images and minimize the difference with respect to the original blurry inputs. We use both synthetic and real dataset for experimental evaluations. Our experiments demonstrate that self-supervised
single image deblurring is really feasible and leads to visually compelling results.
Latex Bibtex Citation:
@article{Liu2020RAL,
author = {Peidong Liu and Joel Janai and Marc Pollefeys and Torsten Sattler and Andreas Geiger},
title = {Self-Supervised Linear Motion Deblurring},
journal = {Robotics and Automation Letters (RA-L)},
year = {2020}
}
Latex Bibtex Citation:
@article{Liu2020RAL,
author = {Peidong Liu and Joel Janai and Marc Pollefeys and Torsten Sattler and Andreas Geiger},
title = {Self-Supervised Linear Motion Deblurring},
journal = {Robotics and Automation Letters (RA-L)},
year = {2020}
}
2019

Attacking Optical Flow
A. Ranjan, J. Janai, A. Geiger and M. Black
International Conference on Computer Vision (ICCV), 2019
A. Ranjan, J. Janai, A. Geiger and M. Black
International Conference on Computer Vision (ICCV), 2019
Abstract: Deep neural nets achieve state-of-the-art performance on the problem of optical flow estimation. Since optical flow is used in several safety-critical applications like self-driving cars, it is important to gain insights into the robustness of those techniques. Recently, it has been shown that adversarial attacks easily fool deep neural networks to misclassify objects. The robustness of optical flow networks to adversarial attacks, however, has not been studied so far. In this paper, we extend adversarial patch attacks to optical flow networks and show that such attacks can compromise their performance. We show that corrupting a small patch of less than 1% of the image size can significantly affect optical flow estimates. Our attacks lead to noisy flow estimates that extend significantly beyond the region of the attack, in many cases even completely erasing the motion of objects in the scene. While networks using an encoder-decoder architecture are very sensitive to these attacks, we found that networks using a spatial pyramid architecture are less affected. We analyse the success and failure of attacking both architectures by visualizing their feature maps and comparing them to classical optical flow techniques which are robust to these attacks. We also demonstrate that such attacks are practical by placing a printed pattern into real scenes.
Latex Bibtex Citation:
@inproceedings{Ranjan2019ICCV,
author = {Anurag Ranjan and Joel Janai and Andreas Geiger and Michael Black},
title = {Attacking Optical Flow},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2019}
}
Latex Bibtex Citation:
@inproceedings{Ranjan2019ICCV,
author = {Anurag Ranjan and Joel Janai and Andreas Geiger and Michael Black},
title = {Attacking Optical Flow},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2019}
}

Occupancy Flow: 4D Reconstruction by Learning Particle Dynamics
M. Niemeyer, L. Mescheder, M. Oechsle and A. Geiger
International Conference on Computer Vision (ICCV), 2019
M. Niemeyer, L. Mescheder, M. Oechsle and A. Geiger
International Conference on Computer Vision (ICCV), 2019
Abstract: Deep learning based 3D reconstruction techniques have recently achieved impressive results. However, while state-of-the-art methods are able to output complex 3D geometry, it is not clear how to extend these results to time-varying topologies. Approaches treating each time step individually lack continuity and exhibit slow inference, while traditional 4D reconstruction methods often utilize a template model or discretize the 4D space at fixed resolution. In this work, we present Occupancy Flow, a novel spatio-temporal representation of time-varying 3D geometry with implicit correspondences. Towards this goal, we learn a temporally and spatially continuous vector field which assigns a motion vector to every point in space and time. In order to perform dense 4D reconstruction from images or sparse point clouds, we combine our method with a continuous 3D representation. Implicitly, our model yields correspondences over time, thus enabling fast inference while providing a sound physical description of the temporal dynamics. We show that our method can be used for interpolation and reconstruction tasks, and demonstrate the accuracy of the learned correspondences. We believe that Occupancy Flow is a promising new 4D representation which will be useful for a variety of spatio-temporal reconstruction tasks.
Latex Bibtex Citation:
@inproceedings{Niemeyer2019ICCV,
author = {Michael Niemeyer and Lars Mescheder and Michael Oechsle and Andreas Geiger},
title = {Occupancy Flow: 4D Reconstruction by Learning Particle Dynamics},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2019}
}
Latex Bibtex Citation:
@inproceedings{Niemeyer2019ICCV,
author = {Michael Niemeyer and Lars Mescheder and Michael Oechsle and Andreas Geiger},
title = {Occupancy Flow: 4D Reconstruction by Learning Particle Dynamics},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2019}
}

Texture Fields: Learning Texture Representations in Function Space (oral)
M. Oechsle, L. Mescheder, M. Niemeyer, T. Strauss and A. Geiger
International Conference on Computer Vision (ICCV), 2019
M. Oechsle, L. Mescheder, M. Niemeyer, T. Strauss and A. Geiger
International Conference on Computer Vision (ICCV), 2019
Abstract: In recent years, substantial progress has been achieved in learning-based reconstruction of 3D objects. At the same time, generative models were proposed that can generate highly realistic images. However, despite this success in these closely related tasks, texture reconstruction of 3D objects has received little attention from the research community and state-of-the-art methods are either limited to comparably low resolution or constrained experimental setups. A major reason for these limitations is that common representations of texture are inefficient or hard to interface for modern deep learning techniques. In this paper, we propose Texture Fields, a novel texture representation which is based on regressing a continuous 3D function parameterized with a neural network. Our approach circumvents limiting factors like shape discretization and parameterization, as the proposed texture representation is independent of the shape representation of the 3D object. We show that Texture Fields are able to represent high frequency texture and naturally blend with modern deep learning techniques. Experimentally, we find that Texture Fields compare favorably to state-of-the-art methods for conditional texture reconstruction of 3D objects and enable learning of probabilistic generative models for texturing unseen 3D models. We believe that Texture Fields will become an important building block for the next generation of generative 3D models.
Latex Bibtex Citation:
@inproceedings{Oechsle2019ICCV,
author = {Michael Oechsle and Lars Mescheder and Michael Niemeyer and Thilo Strauss and Andreas Geiger},
title = {Texture Fields: Learning Texture Representations in Function Space},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2019}
}
Latex Bibtex Citation:
@inproceedings{Oechsle2019ICCV,
author = {Michael Oechsle and Lars Mescheder and Michael Niemeyer and Thilo Strauss and Andreas Geiger},
title = {Texture Fields: Learning Texture Representations in Function Space},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2019}
}

NoVA: Learning to See in Novel Viewpoints and Domains
B. Coors, A. Condurache and A. Geiger
International Conference on 3D Vision (3DV), 2019
B. Coors, A. Condurache and A. Geiger
International Conference on 3D Vision (3DV), 2019
Abstract: Domain adaptation techniques enable the re-use and transfer of existing labeled datasets from a source to a target domain in which little or no labeled data exists. Recently, image-level domain adaptation approaches have demonstrated impressive results in adapting from synthetic to real-world environments by translating source images to the style of a target domain. However, the domain gap between source and target may not only be caused by a different style but also by a change in viewpoint. This case necessitates a semantically consistent translation of source images and labels to the style and viewpoint of the target domain. In this work, we propose the Novel Viewpoint Adaptation (NoVA) model, which enables unsupervised adaptation to a novel viewpoint in a target domain for which no labeled data is available. NoVA utilizes an explicit representation of the 3D scene geometry to translate source view images and labels to the target view. Experiments on adaptation to synthetic and real-world datasets show the benefit of NoVA compared to state-of-the-art domain adaptation approaches on the task of semantic segmentation.
Latex Bibtex Citation:
@inproceedings{Coors2019THREEDV,
author = {Benjamin Coors and Alexandru Paul Condurache and Andreas Geiger},
title = {NoVA: Learning to See in Novel Viewpoints and Domains},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2019}
}
Latex Bibtex Citation:
@inproceedings{Coors2019THREEDV,
author = {Benjamin Coors and Alexandru Paul Condurache and Andreas Geiger},
title = {NoVA: Learning to See in Novel Viewpoints and Domains},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2019}
}

Taking a Deeper Look at the Inverse Compositional Algorithm (oral, best paper finalist)
Z. Lv, F. Dellaert, J. Rehg and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
Z. Lv, F. Dellaert, J. Rehg and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
Abstract: In this paper, we provide a modern synthesis of the classic inverse compositional algorithm for dense image alignment. We first discuss the assumptions made by this well-established technique, and subsequently propose to relax these assumptions by incorporating data-driven priors into this model. More specifically, we unroll a robust version of the inverse compositional algorithm and replace multiple components of this algorithm using more expressive models whose parameters we train in an end-to-end fashion from data. Our experiments on several challenging 3D rigid motion estimation tasks demonstrate the advantages of combining optimization with learning-based techniques, outperforming the classic inverse compositional algorithm as well as data-driven image-to-pose regression approaches.
Latex Bibtex Citation:
@inproceedings{Lv2019CVPR,
author = {Zhaoyang Lv and Frank Dellaert and James M. Rehg and Andreas Geiger},
title = {Taking a Deeper Look at the Inverse Compositional Algorithm},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}
Latex Bibtex Citation:
@inproceedings{Lv2019CVPR,
author = {Zhaoyang Lv and Frank Dellaert and James M. Rehg and Andreas Geiger},
title = {Taking a Deeper Look at the Inverse Compositional Algorithm},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}

Occupancy Networks: Learning 3D Reconstruction in Function Space (oral, best paper finalist)
L. Mescheder, M. Oechsle, M. Niemeyer, S. Nowozin and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
L. Mescheder, M. Oechsle, M. Niemeyer, S. Nowozin and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
Abstract: With the advent of deep neural networks, learning-based approaches for 3D~reconstruction have gained popularity. However, unlike for images, in 3D there is no canonical representation which is both computationally and memory efficient yet allows for representing high-resolution geometry of arbitrary topology. Many of the state-of-the-art learning-based 3D~reconstruction approaches can hence only represent very coarse 3D geometry or are limited to a restricted domain. In this paper, we propose Occupancy Networks, a new representation for learning-based 3D~reconstruction methods. Occupancy networks implicitly represent the 3D surface as the continuous decision boundary of a deep neural network classifier. In contrast to existing approaches, our representation encodes a description of the 3D output at infinite resolution without excessive memory footprint. We validate that our representation can efficiently encode 3D structure and can be inferred from various kinds of input. Our experiments demonstrate competitive results, both qualitatively and quantitatively, for the challenging tasks of 3D reconstruction from single images, noisy point clouds and coarse discrete voxel grids. We believe that occupancy networks will become a useful tool in a wide variety of learning-based 3D tasks.
Latex Bibtex Citation:
@inproceedings{Mescheder2019CVPR,
author = {Lars Mescheder and Michael Oechsle and Michael Niemeyer and Sebastian Nowozin and Andreas Geiger},
title = {Occupancy Networks: Learning 3D Reconstruction in Function Space},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}
Latex Bibtex Citation:
@inproceedings{Mescheder2019CVPR,
author = {Lars Mescheder and Michael Oechsle and Michael Niemeyer and Sebastian Nowozin and Andreas Geiger},
title = {Occupancy Networks: Learning 3D Reconstruction in Function Space},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}

Connecting the Dots: Learning Representations for Active Monocular Depth Estimation
G. Riegler, Y. Liao, S. Donne, V. Koltun and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
G. Riegler, Y. Liao, S. Donne, V. Koltun and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
Abstract: We propose a technique for depth estimation with a monocular structured-light camera, \ie, a calibrated stereo set-up with one camera and one laser projector. Instead of formulating the depth estimation via a correspondence search problem, we show that a simple convolutional architecture is sufficient for high-quality disparity estimates in this setting. As accurate ground-truth is hard to obtain, we train our model in a self-supervised fashion with a combination of photometric and geometric losses. Further, we demonstrate that the projected pattern of the structured light sensor can be reliably separated from the ambient information. This can then be used to improve depth boundaries in a weakly supervised fashion by modeling the joint statistics of image and depth edges. The model trained in this fashion compares favorably to the state-of-the-art on challenging synthetic and real-world datasets. In addition, we contribute a novel simulator, which allows to benchmark active depth prediction algorithms in controlled conditions.
Latex Bibtex Citation:
@inproceedings{Riegler2019CVPR,
author = {Gernot Riegler and Yiyi Liao and Simon Donne and Vladlen Koltun and Andreas Geiger},
title = {Connecting the Dots: Learning Representations for Active Monocular Depth Estimation},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}
Latex Bibtex Citation:
@inproceedings{Riegler2019CVPR,
author = {Gernot Riegler and Yiyi Liao and Simon Donne and Vladlen Koltun and Andreas Geiger},
title = {Connecting the Dots: Learning Representations for Active Monocular Depth Estimation},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}

MOTS: Multi-Object Tracking and Segmentation
P. Voigtlaender, M. Krause, A. Osep, J. Luiten, B. Sekar, A. Geiger and B. Leibe
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
P. Voigtlaender, M. Krause, A. Osep, J. Luiten, B. Sekar, A. Geiger and B. Leibe
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
Abstract: This paper extends the popular task of multi-object tracking to multi-object tracking and segmentation (MOTS). Towards this goal, we create dense pixel-level annotations for two existing tracking datasets using a semi-automatic annotation procedure. Our new annotations comprise 65,213 pixel masks for 977 distinct objects (cars and pedestrians) in 10,870 video frames. For evaluation, we extend existing multi-object tracking metrics to this new task. Moreover, we propose a new baseline method which jointly addresses detection, tracking, and segmentation with a single convolutional network. We demonstrate the value of our datasets by achieving improvements in performance when training on MOTS annotations. We believe that our datasets, metrics and baseline will become a valuable resource towards developing multi-object tracking approaches that go beyond 2D bounding boxes.
Latex Bibtex Citation:
@inproceedings{Voigtlaender2019CVPR,
author = {Paul Voigtlaender and Michael Krause and Aljosa Osep and Jonathon Luiten and Berin Balachandar Gnana Sekar and Andreas Geiger and Bastian Leibe},
title = {MOTS: Multi-Object Tracking and Segmentation},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}
Latex Bibtex Citation:
@inproceedings{Voigtlaender2019CVPR,
author = {Paul Voigtlaender and Michael Krause and Aljosa Osep and Jonathon Luiten and Berin Balachandar Gnana Sekar and Andreas Geiger and Bastian Leibe},
title = {MOTS: Multi-Object Tracking and Segmentation},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}

PointFlowNet: Learning Representations for Rigid Motion Estimation from Point Clouds
A. Behl, D. Paschalidou, S. Donne and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
A. Behl, D. Paschalidou, S. Donne and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
Abstract: Despite significant progress in image-based 3D scene flow estimation, the performance of such approaches has not yet reached the fidelity required by many applications. Simultaneously, these applications are often not restricted to image-based estimation: laser scanners provide a popular alternative to traditional cameras, for example in the context of self-driving cars, as they directly yield a 3D point cloud. In this paper, we propose to estimate 3D motion from such unstructured point clouds using a deep neural network. In a single forward pass, our model jointly predicts 3D scene flow as well as the 3D bounding box and rigid body motion of objects in the scene. While the prospect of estimating 3D scene flow from unstructured point clouds is promising, it is also a challenging task. We show that the traditional global representation of rigid body motion prohibits inference by CNNs, and propose a translation equivariant representation to circumvent this problem. For training our deep network, a large dataset is required. Because of this, we augment real scans from KITTI with virtual objects, realistically modeling occlusions and simulating sensor noise. A thorough comparison with classic and learning-based techniques highlights the robustness of the proposed approach.
Latex Bibtex Citation:
@inproceedings{Behl2019CVPR,
author = {Aseem Behl and Despoina Paschalidou and Simon Donne and Andreas Geiger},
title = {PointFlowNet: Learning Representations for Rigid Motion Estimation from Point Clouds},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}
Latex Bibtex Citation:
@inproceedings{Behl2019CVPR,
author = {Aseem Behl and Despoina Paschalidou and Simon Donne and Andreas Geiger},
title = {PointFlowNet: Learning Representations for Rigid Motion Estimation from Point Clouds},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}

Learning Non-volumetric Depth Fusion using Successive Reprojections
S. Donne and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
S. Donne and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
Abstract: Given a set of input views, multi-view stereopsis techniques estimate depth maps to represent the 3D reconstruction of the scene; these are fused into a single, consistent, reconstruction -- most often a point cloud. In this work we propose to learn an auto-regressive depth refinement directly from data. While deep learning has improved the accuracy and speed of depth estimation significantly, learned MVS techniques remain limited to the planesweeping paradigm. We refine a set of input depth maps by successively reprojecting information from neighbouring views to leverage multi-view constraints. Compared to learning-based volumetric fusion techniques, an image-based representation allows significantly more detailed reconstructions; compared to traditional point-based techniques, our method learns noise suppression and surface completion in a data-driven fashion. Due to the limited availability of high-quality reconstruction datasets with ground truth, we introduce two novel synthetic datasets to (pre-)train our network. Our approach is able to improve both the output depth maps and the reconstructed point cloud, for both learned and traditional depth estimation front-ends, on both synthetic and real data.
Latex Bibtex Citation:
@inproceedings{Donne2019CVPR,
author = {Simon Donne and Andreas Geiger},
title = {Learning Non-volumetric Depth Fusion using Successive Reprojections},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}
Latex Bibtex Citation:
@inproceedings{Donne2019CVPR,
author = {Simon Donne and Andreas Geiger},
title = {Learning Non-volumetric Depth Fusion using Successive Reprojections},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}

Superquadrics Revisited: Learning 3D Shape Parsing beyond Cuboids
D. Paschalidou, A. Ulusoy and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
D. Paschalidou, A. Ulusoy and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
Abstract: Abstracting complex 3D shapes with parsimonious part-based representations has been a long standing goal in computer vision. This paper presents a learning-based solution to this problem which goes beyond the traditional 3D cuboid representation by exploiting superquadrics as atomic elements. We demonstrate that superquadrics lead to more expressive 3D scene parses while being easier to learn than 3D cuboid representations. Moreover, we provide an analytical solution to the Chamfer loss which avoids the need for computational expensive reinforcement learning or iterative prediction. Our model learns to parse 3D objects into consistent superquadric representations without supervision. Results on various ShapeNet categories as well as the SURREAL human body dataset demonstrate the flexibility of our model in capturing fine details and complex poses that could not have been modelled using cuboids.
Latex Bibtex Citation:
@inproceedings{Paschalidou2019CVPR,
author = {Despoina Paschalidou and Ali Osman Ulusoy and Andreas Geiger},
title = {Superquadrics Revisited: Learning 3D Shape Parsing beyond Cuboids},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}
Latex Bibtex Citation:
@inproceedings{Paschalidou2019CVPR,
author = {Despoina Paschalidou and Ali Osman Ulusoy and Andreas Geiger},
title = {Superquadrics Revisited: Learning 3D Shape Parsing beyond Cuboids},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}

Project AutoVision: Localization and 3D Scene Perception for an Autonomous Vehicle with a Multi-Camera System
L. Heng, B. Choi, Z. Cui, M. Geppert, S. Hu, B. Kuan, P. Liu, R. Nguyen, Y. Yeo, A. Geiger, et al.
International Conference on Robotics and Automation (ICRA), 2019
L. Heng, B. Choi, Z. Cui, M. Geppert, S. Hu, B. Kuan, P. Liu, R. Nguyen, Y. Yeo, A. Geiger, et al.
International Conference on Robotics and Automation (ICRA), 2019
Abstract: Project AutoVision aims to develop localization and 3D scene perception capabilities for a self-driving vehicle. Such capabilities will enable autonomous navigation in urban and rural environments, in day and night, and with cameras as the only exteroceptive sensors. The sensor suite employs many cameras for both 360-degree coverage and accurate multi-view stereo; the use of low-cost cameras keeps the cost of this sensor suite to a minimum. In addition, the project seeks to extend the operating envelope to include GNSS-less conditions which are typical for environments with tall buildings, foliage, and tunnels. Emphasis is placed on leveraging multi-view geometry and deep learning to enable the vehicle to localize and perceive in 3D space. This paper presents an overview of the project, and describes the sensor suite and current progress in the areas of calibration, localization, and perception.
Latex Bibtex Citation:
@inproceedings{Heng2019ICRA,
author = {Lionel Heng and Benjamin Choi and Zhaopeng Cui and Marcel Geppert and Sixing Hu and Benson Kuan and Peidong Liu and Rang M. H. Nguyen and Ye Chuan Yeo and Andreas Geiger and Gim Hee Lee and Marc Pollefeys and Torsten Sattler},
title = {Project AutoVision: Localization and 3D Scene Perception for an Autonomous Vehicle with a Multi-Camera System},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2019}
}
Latex Bibtex Citation:
@inproceedings{Heng2019ICRA,
author = {Lionel Heng and Benjamin Choi and Zhaopeng Cui and Marcel Geppert and Sixing Hu and Benson Kuan and Peidong Liu and Rang M. H. Nguyen and Ye Chuan Yeo and Andreas Geiger and Gim Hee Lee and Marc Pollefeys and Torsten Sattler},
title = {Project AutoVision: Localization and 3D Scene Perception for an Autonomous Vehicle with a Multi-Camera System},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2019}
}

Real-Time Dense Mapping for Self-Driving Vehicles using Fisheye Cameras
Z. Cui, L. Heng, Y. Yeo, A. Geiger, M. Pollefeys and T. Sattler
International Conference on Robotics and Automation (ICRA), 2019
Z. Cui, L. Heng, Y. Yeo, A. Geiger, M. Pollefeys and T. Sattler
International Conference on Robotics and Automation (ICRA), 2019
Abstract: We present a real-time dense geometric mapping algorithm for large-scale environments. Unlike existing methods which use pinhole cameras, our implementation is based on fisheye cameras which have larger field of view and benefit some other tasks including Visual-Inertial Odometry, localization and object detection around vehicles. Our algorithm runs on in-vehicle PCs at 15 Hz approximately, enabling vision-only 3D scene perception for self-driving vehicles. For each synchronized set of images captured by multiple cameras, we first compute a depth map for a reference camera using plane-sweeping stereo. To maintain both accuracy and efficiency, while accounting for the fact that fisheye images have a rather low resolution, we recover the depths using multiple image resolutions. We adopt the fast object detection framework YOLOv3 to remove potentially dynamic objects. At the end of the pipeline, we fuse the fisheye depth images into the truncated signed distance function (TSDF) volume to obtain a 3D map. We evaluate our method on large-scale urban datasets, and results show that our method works well even in complex environments.
Latex Bibtex Citation:
@inproceedings{Cui2019ICRA,
author = {Zhaopeng Cui and Lionel Heng and Ye Chuan Yeo and Andreas Geiger and Marc Pollefeys and Torsten Sattler},
title = {Real-Time Dense Mapping for Self-Driving Vehicles using Fisheye Cameras},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2019}
}
Latex Bibtex Citation:
@inproceedings{Cui2019ICRA,
author = {Zhaopeng Cui and Lionel Heng and Ye Chuan Yeo and Andreas Geiger and Marc Pollefeys and Torsten Sattler},
title = {Real-Time Dense Mapping for Self-Driving Vehicles using Fisheye Cameras},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2019}
}
2018

Conditional Affordance Learning for Driving in Urban Environments (oral)
A. Sauer, N. Savinov and A. Geiger
Conference on Robot Learning (CoRL), 2018
A. Sauer, N. Savinov and A. Geiger
Conference on Robot Learning (CoRL), 2018
Abstract: Most existing approaches to autonomous driving fall into one of two categories: modular pipelines, that build an extensive model of the environment, and imitation learning approaches, that map images directly to control outputs. A recently proposed third paradigm, direct perception, aims to combine the advantages of both by using a neural network to learn appropriate low-dimensional intermediate representations. However, existing direct perception approaches are restricted to simple highway situations, lacking the ability to navigate intersections, stop at traffic lights or respect speed limits. In this work, we propose a direct perception approach which maps video input to intermediate representations suitable for autonomous navigation in complex urban environments given high-level directional inputs. Compared to state-of-the-art reinforcement and conditional imitation learning approaches, we achieve an improvement of up to 68 \% in goal-directed navigation on the challenging CARLA simulation benchmark. In addition, our approach is the first to handle traffic lights, speed signs and smooth car-following, resulting in a significant reduction of traffic accidents.
Latex Bibtex Citation:
@inproceedings{Sauer2018CORL,
author = {Axel Sauer and Nikolay Savinov and Andreas Geiger},
title = {Conditional Affordance Learning for Driving in Urban Environments},
booktitle = {Conference on Robot Learning (CoRL)},
year = {2018}
}
Latex Bibtex Citation:
@inproceedings{Sauer2018CORL,
author = {Axel Sauer and Nikolay Savinov and Andreas Geiger},
title = {Conditional Affordance Learning for Driving in Urban Environments},
booktitle = {Conference on Robot Learning (CoRL)},
year = {2018}
}

On the Integration of Optical Flow and Action Recognition (oral)
L. Sevilla-Lara, Y. Liao, F. Güney, V. Jampani, A. Geiger and M. Black
German Conference on Pattern Recognition (GCPR), 2018
L. Sevilla-Lara, Y. Liao, F. Güney, V. Jampani, A. Geiger and M. Black
German Conference on Pattern Recognition (GCPR), 2018
Abstract: Most of the top performing action recognition methods use optical flow as a black box input. Here we take a deeper look at the combination of flow and action recognition, and investigate why optical flow is helpful, what makes a flow method good for action recognition, and how we can make it better. In particular, we investigate the impact of different flow algorithms and input transformations to better understand how these affect a state-of-the-art action recognition method. Furthermore, we fine tune two neural-network flow methods end-to-end on the most widely used action recognition dataset (UCF101). Based on these experiments, we make the following five observations: 1) optical flow is useful for action recognition because it is invariant to appearance, 2) optical flow methods are optimized to minimize end-point-error (EPE), but the EPE of current methods is not well correlated with action recognition performance, 3) for the flow methods tested, accuracy at boundaries and at small displacements is most correlated with action recognition performance, 4) training optical flow to minimize classification error instead of minimizing EPE improves recognition performance, and 5) optical flow learned for the task of action recognition differs from traditional optical flow especially inside the human body and at the boundary of the body. These observations may encourage optical flow researchers to look beyond EPE as a goal and guide action recognition researchers to seek better motion cues, leading to a tighter integration of the optical flow and action recognition communities.
Latex Bibtex Citation:
@inproceedings{Sevilla-Lara2018GCPR,
author = {Laura Sevilla-Lara and Yiyi Liao and Fatma Güney and Varun Jampani and Andreas Geiger and Michael Black},
title = {On the Integration of Optical Flow and Action Recognition},
booktitle = {German Conference on Pattern Recognition (GCPR)},
year = {2018}
}
Latex Bibtex Citation:
@inproceedings{Sevilla-Lara2018GCPR,
author = {Laura Sevilla-Lara and Yiyi Liao and Fatma Güney and Varun Jampani and Andreas Geiger and Michael Black},
title = {On the Integration of Optical Flow and Action Recognition},
booktitle = {German Conference on Pattern Recognition (GCPR)},
year = {2018}
}

Learning 3D Shape Completion under Weak Supervision
D. Stutz and A. Geiger
International Journal of Computer Vision (IJCV), 2018
D. Stutz and A. Geiger
International Journal of Computer Vision (IJCV), 2018
Abstract: We address the problem of 3D shape completion from sparse and noisy point clouds, a fundamental problem in computer vision and robotics. Recent approaches are either data-driven or learning-based: Data-driven approaches rely on a shape model whose parameters are optimized to fit the observations; Learning-based approaches, in contrast, avoid the expensive optimization step by learning to directly predict complete shapes from incomplete observations in a fully-supervised setting. However, full supervision is often not available in practice. In this work, we propose a weakly-supervised learning-based approach to 3D shape completion which neither requires slow optimization nor direct supervision. While we also learn a shape prior on synthetic data, we amortize, i.e., learn, maximum likelihood fitting using deep neural networks resulting in efficient shape completion without sacrificing accuracy. On synthetic benchmarks based on ShapeNet and ModelNet as well as on real robotics data from KITTI and Kinect, we demonstrate that the proposed amortized maximum likelihood approach is able to compete with a fully supervised baseline and outperforms the data-driven approach of Engelmann et al., while requiring less supervision and being significantly faster.
Latex Bibtex Citation:
@inproceedings{Stutz2018IJCV,
author = {David Stutz and Andreas Geiger},
title = {Learning 3D Shape Completion under Weak Supervision},
booktitle = {International Journal of Computer Vision (IJCV)},
year = {2018}
}
Latex Bibtex Citation:
@inproceedings{Stutz2018IJCV,
author = {David Stutz and Andreas Geiger},
title = {Learning 3D Shape Completion under Weak Supervision},
booktitle = {International Journal of Computer Vision (IJCV)},
year = {2018}
}

Towards Robust Visual Odometry with a Multi-Camera System
P. Liu, M. Geppert, L. Heng, T. Sattler, A. Geiger and M. Pollefeys
International Conference on Intelligent Robots and Systems (IROS), 2018
P. Liu, M. Geppert, L. Heng, T. Sattler, A. Geiger and M. Pollefeys
International Conference on Intelligent Robots and Systems (IROS), 2018
Abstract: We present a visual odometry (VO) algorithm for a multi-camera system and robust operation in challenging environments. Our algorithm consists of a pose tracker and a local mapper. The tracker estimates the current pose by minimizing photometric errors between the most recent keyframe and the current frame. The mapper initializes the depths of all sampled feature points using plane-sweeping stereo. To reduce pose drift, a sliding window optimizer is used to refine poses and structure jointly. Our formulation is flexible enough to support an arbitrary number of stereo cameras. We evaluate our algorithm thoroughly on five datasets. The datasets were captured in different conditions: daytime, night-time with near-infrared (NIR) illumination and night-time without NIR illumination. Experimental results show that a multi-camera setup makes the VO more robust to challenging environments, especially night-time conditions, in which a single stereo configuration fails easily due to the lack of features.
Latex Bibtex Citation:
@inproceedings{Liu2018IROS,
author = {Peidong Liu and Marcel Geppert and Lionel Heng and Torsten Sattler and Andreas Geiger and Marc Pollefeys},
title = {Towards Robust Visual Odometry with a Multi-Camera System},
booktitle = {International Conference on Intelligent Robots and Systems (IROS)},
year = {2018}
}
Latex Bibtex Citation:
@inproceedings{Liu2018IROS,
author = {Peidong Liu and Marcel Geppert and Lionel Heng and Torsten Sattler and Andreas Geiger and Marc Pollefeys},
title = {Towards Robust Visual Odometry with a Multi-Camera System},
booktitle = {International Conference on Intelligent Robots and Systems (IROS)},
year = {2018}
}

Geometric Image Synthesis
H. Alhaija, S. Mustikovela, A. Geiger and C. Rother
Asian Conference on Computer Vision (ACCV), 2018
H. Alhaija, S. Mustikovela, A. Geiger and C. Rother
Asian Conference on Computer Vision (ACCV), 2018
Abstract: The task of generating natural images from 3D scenes has been a long standing goal in computer graphics. On the other hand, recent developments in deep neural networks allow for trainable models that can produce natural-looking images with little or no knowledge about the scene structure. While the generated images often consist of realistic looking local patterns, the overall structure of the generated images is often inconsistent. In this work we propose a trainable, geometry-aware image generation method that leverages various types of scene information, including geometry and segmentation, to create realistic looking natural images that match the desired scene structure. Our geometrically-consistent image synthesis method is a deep neural network, called Geometry to Image Synthesis (GIS) framework, which retains the advantages of a trainable method, e.g., differentiability and adaptiveness, but, at the same time, makes a step towards the generalizability, control and quality output of modern graphics rendering engines. We utilize the GIS framework to insert vehicles in outdoor driving scenes, as well as to generate novel views of objects from the Linemod dataset. We qualitatively show that our network is able to generalize beyond the training set to novel scene geometries, object shapes and segmentations. Furthermore, we quantitatively show that the GIS framework can be used to synthesize large amounts of training data which proves beneficial for training instance segmentation models.
Latex Bibtex Citation:
@inproceedings{Alhaija2018ACCV,
author = {Hassan Alhaija and Siva Mustikovela and Andreas Geiger and Carsten Rother},
title = {Geometric Image Synthesis},
booktitle = {Asian Conference on Computer Vision (ACCV)},
year = {2018}
}
Latex Bibtex Citation:
@inproceedings{Alhaija2018ACCV,
author = {Hassan Alhaija and Siva Mustikovela and Andreas Geiger and Carsten Rother},
title = {Geometric Image Synthesis},
booktitle = {Asian Conference on Computer Vision (ACCV)},
year = {2018}
}

SphereNet: Learning Spherical Representations for Detection and Classification in Omnidirectional Images
B. Coors, A. Condurache and A. Geiger
European Conference on Computer Vision (ECCV), 2018
B. Coors, A. Condurache and A. Geiger
European Conference on Computer Vision (ECCV), 2018
Abstract: Omnidirectional cameras offer great benefits over classical cameras wherever a wide field of view is essential, such as in virtual reality applications or in autonomous robots. Unfortunately, standard convolutional neural networks are not well suited for this scenario as the natural projection surface is a sphere which cannot be unwrapped to a plane without introducing significant distortions, particularly in the polar regions. In this work, we present SphereNet, a novel deep learning framework which encodes invariance against such distortions explicitly into convolutional neural networks. Towards this goal, SphereNet adapts the sampling locations of the convolutional filters, effectively reversing distortions, and wraps the filters around the sphere. By building on regular convolutions, SphereNet enables the transfer of existing perspective convolutional neural network models to the omnidirectional case. We demonstrate the effectiveness of our method on the tasks of image classification and object detection, exploiting two newly created semi-synthetic and real-world omnidirectional datasets.
Latex Bibtex Citation:
@inproceedings{Coors2018ECCV,
author = {Benjamin Coors and Alexandru Paul Condurache and Andreas Geiger},
title = {SphereNet: Learning Spherical Representations for Detection and Classification in Omnidirectional Images},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2018}
}
Latex Bibtex Citation:
@inproceedings{Coors2018ECCV,
author = {Benjamin Coors and Alexandru Paul Condurache and Andreas Geiger},
title = {SphereNet: Learning Spherical Representations for Detection and Classification in Omnidirectional Images},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2018}
}

Learning Priors for Semantic 3D Reconstruction
I. Cherabier, J. Schönberger, M. Oswald, M. Pollefeys and A. Geiger
European Conference on Computer Vision (ECCV), 2018
I. Cherabier, J. Schönberger, M. Oswald, M. Pollefeys and A. Geiger
European Conference on Computer Vision (ECCV), 2018
Abstract: We present a novel semantic 3D reconstruction framework which embeds variational regularization into a neural network. Our network performs a fixed number of unrolled multi-scale optimization iterations with shared interaction weights. In contrast to existing variational methods for semantic 3D reconstruction, our model is end-to-end trainable and captures more complex dependencies between the semantic labels and the 3D geometry. Compared to previous learning-based approaches to 3D reconstruction, we integrate powerful long-range dependencies using variational coarse-to-fine optimization. As a result, our network architecture requires only a moderate number of parameters while keeping a high level of expressiveness which enables learning from very little data. Experiments on real and synthetic datasets demonstrate that our network achieves higher accuracy compared to a purely variational approach while at the same time requiring two orders of magnitude less iterations to converge. Moreover, our approach handles ten times more semantic class labels using the same computational resources.
Latex Bibtex Citation:
@inproceedings{Cherabier2018ECCV,
author = {Ian Cherabier and Johannes Schönberger and Martin Oswald and Marc Pollefeys and Andreas Geiger},
title = {Learning Priors for Semantic 3D Reconstruction},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2018}
}
Latex Bibtex Citation:
@inproceedings{Cherabier2018ECCV,
author = {Ian Cherabier and Johannes Schönberger and Martin Oswald and Marc Pollefeys and Andreas Geiger},
title = {Learning Priors for Semantic 3D Reconstruction},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2018}
}

Unsupervised Learning of Multi-Frame Optical Flow with Occlusions
J. Janai, F. Güney, A. Ranjan, M. Black and A. Geiger
European Conference on Computer Vision (ECCV), 2018
J. Janai, F. Güney, A. Ranjan, M. Black and A. Geiger
European Conference on Computer Vision (ECCV), 2018
Abstract: Learning optical flow with neural networks is hampered by the need for obtaining training data with associated ground truth. Unsupervised learning is a promising direction, yet the performance of current unsupervised methods is still limited. In particular, the lack of proper occlusion handling in commonly used data terms constitutes a major source of error. While most optical flow methods process pairs of consecutive frames, more advanced occlusion reasoning can be realized when considering multiple frames. In this paper, we propose a framework for unsupervised learning of optical flow and occlusions over multiple frames. More specifically, we exploit the minimal configuration of three frames to strengthen the photometric loss and explicitly reason about occlusions. We demonstrate that our multi-frame, occlusion-sensitive formulation outperforms existing unsupervised two-frame methods and even produces results on par with some fully supervised methods.
Latex Bibtex Citation:
@inproceedings{Janai2018ECCV,
author = {Joel Janai and Fatma Güney and Anurag Ranjan and Michael Black and Andreas Geiger},
title = {Unsupervised Learning of Multi-Frame Optical Flow with Occlusions},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2018}
}
Latex Bibtex Citation:
@inproceedings{Janai2018ECCV,
author = {Joel Janai and Fatma Güney and Anurag Ranjan and Michael Black and Andreas Geiger},
title = {Unsupervised Learning of Multi-Frame Optical Flow with Occlusions},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2018}
}

Which Training Methods for GANs do actually Converge? (oral)
L. Mescheder, A. Geiger and S. Nowozin
International Conference on Machine learning (ICML), 2018
L. Mescheder, A. Geiger and S. Nowozin
International Conference on Machine learning (ICML), 2018
Abstract: Recent work has shown local convergence of GAN training for absolutely continuous
data and generator distributions. In this paper, we show that the requirement of absolute continuity is necessary: we describe a simple yet prototypical counterexample showing that in the more realistic case of distributions that are not absolutely continuous, unregularized GAN training is not always convergent. Furthermore, we discuss regularization strategies that were recently proposed to stabilize GAN training. Our analysis shows that GAN training with instance noise or zero-centered gradient penalties converges. On the other hand, we show that Wasserstein-GANs and WGAN-GP with a finite number of discriminator updates per generator update do not always converge to the equilibrium point. We discuss these results, leading us to a new explanation for the stability problems of GAN training. Based on our analysis, we extend our convergence results to more general GANs and prove local convergence for simplified gradient penalties even if the generator and data distributions lie on lower dimensional manifolds. We find these penalties to work well in practice and use them to learn high-resolution generative image models for a variety of datasets with little hyperparameter tuning.
Latex Bibtex Citation:
@inproceedings{Mescheder2018ICML,
author = {Lars Mescheder and Andreas Geiger and Sebastian Nowozin},
title = {Which Training Methods for GANs do actually Converge?},
booktitle = {International Conference on Machine learning (ICML)},
year = {2018}
}
Latex Bibtex Citation:
@inproceedings{Mescheder2018ICML,
author = {Lars Mescheder and Andreas Geiger and Sebastian Nowozin},
title = {Which Training Methods for GANs do actually Converge?},
booktitle = {International Conference on Machine learning (ICML)},
year = {2018}
}

Semantic Visual Localization
J. Schönberger, M. Pollefeys, A. Geiger and T. Sattler
Conference on Computer Vision and Pattern Recognition (CVPR), 2018
J. Schönberger, M. Pollefeys, A. Geiger and T. Sattler
Conference on Computer Vision and Pattern Recognition (CVPR), 2018
Abstract: Robust visual localization under a wide range of viewing conditions is a fundamental problem in computer vision. Handling the difficult cases of this problem is not only very challenging but also of high practical relevance, eg, in the context of life-long localization for augmented reality or autonomous robots. In this paper, we propose a novel approach based on a joint 3D geometric and semantic understanding of the world, enabling it to succeed under conditions where previous approaches failed. Our method leverages a novel generative model for descriptor learning, trained on semantic scene completion as an auxiliary task. The resulting 3D descriptors are robust to missing observations by encoding high-level 3D geometric and semantic information. Experiments on several challenging large-scale localization datasets demonstrate reliable localization under extreme viewpoint, illumination, and geometry changes.
Latex Bibtex Citation:
@inproceedings{Schoenberger2018CVPR,
author = {Johannes Schönberger and Marc Pollefeys and Andreas Geiger and Torsten Sattler},
title = {Semantic Visual Localization},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2018}
}
Latex Bibtex Citation:
@inproceedings{Schoenberger2018CVPR,
author = {Johannes Schönberger and Marc Pollefeys and Andreas Geiger and Torsten Sattler},
title = {Semantic Visual Localization},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2018}
}

Learning 3D Shape Completion from Laser Scan Data with Weak Supervision
D. Stutz and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2018
D. Stutz and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2018
Abstract: 3D shape completion from partial point clouds is a fundamental problem in computer vision and computer graphics. Recent approaches can be characterized as either data-driven or learning-based. Data-driven approaches rely on a shape model whose parameters are optimized to fit the observations. Learning-based approaches, in contrast, avoid the expensive optimization step and instead directly predict the complete shape from the incomplete observations using deep neural networks. However, full supervision is required which is often not available in practice. In this work, we propose a weakly-supervised learning-based approach to 3D shape completion which neither requires slow optimization nor direct supervision. While we also learn a shape prior on synthetic data, we amortize, ie, learn, maximum likelihood fitting using deep neural networks resulting in efficient shape completion without sacrificing accuracy. Tackling 3D shape completion of cars on ShapeNet and KITTI, we demonstrate that the proposed amortized maximum likelihood approach is able to compete with a fully supervised baseline and a state-of-the-art data-driven approach while being significantly faster. On ModelNet, we additionally show that the approach is able to generalize to other object categories as well.
Latex Bibtex Citation:
@inproceedings{Stutz2018CVPR,
author = {David Stutz and Andreas Geiger},
title = {Learning 3D Shape Completion from Laser Scan Data with Weak Supervision},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2018}
}
Latex Bibtex Citation:
@inproceedings{Stutz2018CVPR,
author = {David Stutz and Andreas Geiger},
title = {Learning 3D Shape Completion from Laser Scan Data with Weak Supervision},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2018}
}

Deep Marching Cubes: Learning Explicit Surface Representations
Y. Liao, S. Donne and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2018
Y. Liao, S. Donne and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2018
Abstract: Existing learning based solutions to 3D surface prediction cannot be trained end-to-end as they operate on intermediate representations (eg, TSDF) from which 3D surface meshes must be extracted in a post-processing step (eg, via the marching cubes algorithm). In this paper, we investigate the problem of end-to-end 3D surface prediction. We first demonstrate that the marching cubes algorithm is not differentiable and propose an alternative differentiable formulation which we insert as a final layer into a 3D convolutional neural network. We further propose a set of loss functions which allow for training our model with sparse point supervision. Our experiments demonstrate that the model allows for predicting sub-voxel accurate 3D shapes of arbitrary topology. Additionally, it learns to complete shapes and to separate an object's inside from its outside even in the presence of sparse and incomplete ground truth. We investigate the benefits of our approach on the task of inferring shapes from 3D point clouds. Our model is flexible and can be combined with a variety of shape encoder and shape inference techniques.
Latex Bibtex Citation:
@inproceedings{Liao2018CVPR,
author = {Yiyi Liao and Simon Donne and Andreas Geiger},
title = {Deep Marching Cubes: Learning Explicit Surface Representations},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2018}
}
Latex Bibtex Citation:
@inproceedings{Liao2018CVPR,
author = {Yiyi Liao and Simon Donne and Andreas Geiger},
title = {Deep Marching Cubes: Learning Explicit Surface Representations},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2018}
}

RayNet: Learning Volumetric 3D Reconstruction with Ray Potentials (spotlight)
D. Paschalidou, A. Ulusoy, C. Schmitt, L. Gool and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2018
D. Paschalidou, A. Ulusoy, C. Schmitt, L. Gool and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2018
Abstract: In this paper, we consider the problem of reconstructing a dense 3D model using images captured from different views. Recent methods based on convolutional neural networks (CNN) allow learning the entire task from data. However, they do not incorporate the physics of image formation such as perspective geometry and occlusion. Instead, classical approaches based on Markov Random Fields (MRF) with ray-potentials explicitly model these physical processes, but they cannot cope with large surface appearance variations across different viewpoints. In this paper, we propose RayNet, which combines the strengths of both frameworks. RayNet integrates a CNN that learns view-invariant feature representations with an MRF that explicitly encodes the physics of perspective projection and occlusion. We train RayNet end-to-end using empirical risk minimization. We thoroughly evaluate our approach on challenging real-world datasets and demonstrate its benefits over a piece-wise trained baseline, hand-crafted models as well as other learning-based approaches.
Latex Bibtex Citation:
@inproceedings{Paschalidou2018CVPR,
author = {Despoina Paschalidou and Ali Osman Ulusoy and Carolin Schmitt and Luc Gool and Andreas Geiger},
title = {RayNet: Learning Volumetric 3D Reconstruction with Ray Potentials},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2018}
}
Latex Bibtex Citation:
@inproceedings{Paschalidou2018CVPR,
author = {Despoina Paschalidou and Ali Osman Ulusoy and Carolin Schmitt and Luc Gool and Andreas Geiger},
title = {RayNet: Learning Volumetric 3D Reconstruction with Ray Potentials},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2018}
}

Robust Dense Mapping for Large-Scale Dynamic Environments
I. Barsan, P. Liu, M. Pollefeys and A. Geiger
International Conference on Robotics and Automation (ICRA), 2018
I. Barsan, P. Liu, M. Pollefeys and A. Geiger
International Conference on Robotics and Automation (ICRA), 2018
Abstract: We present a stereo-based dense mapping algorithm for large-scale dynamic urban environments. In contrast to other existing methods, we simultaneously reconstruct the static background, the moving objects, and the potentially moving but currently stationary objects separately, which is desirable for high-level mobile robotic tasks such as path planning in crowded environments. We use both instance-aware semantic segmentation and sparse scene flow to classify objects as either background, moving, or potentially moving, thereby ensuring that the system is able to model objects with the potential to transition from static to dynamic, such as parked cars. Given camera poses estimated from visual odometry, both the background and the (potentially) moving objects are reconstructed separately by fusing the depth maps computed from the stereo input. In addition to visual odometry, sparse scene flow is also used to estimate the 3D motions of the detected moving objects, in order to reconstruct them accurately. A map pruning technique is further developed to improve reconstruction accuracy and reduce memory consumption, leading to increased scalability. We evaluate our system thoroughly on the well-known KITTI dataset. Our system is capable of running on a PC at approximately 2.5Hz, with the primary bottleneck being the instance-aware semantic segmentation, which is a limitation we hope to address in future work.
Latex Bibtex Citation:
@inproceedings{Barsan2018ICRA,
author = {Ioan Andrei Barsan and Peidong Liu and Marc Pollefeys and Andreas Geiger},
title = {Robust Dense Mapping for Large-Scale Dynamic Environments},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2018}
}
Latex Bibtex Citation:
@inproceedings{Barsan2018ICRA,
author = {Ioan Andrei Barsan and Peidong Liu and Marc Pollefeys and Andreas Geiger},
title = {Robust Dense Mapping for Large-Scale Dynamic Environments},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2018}
}

Object Scene Flow
M. Menze, C. Heipke and A. Geiger
ISPRS Journal of Photogrammetry and Remote Sensing (JPRS), 2018
M. Menze, C. Heipke and A. Geiger
ISPRS Journal of Photogrammetry and Remote Sensing (JPRS), 2018
Abstract: This work investigates the estimation of dense three-dimensional motion fields, commonly referred to as scene flow. While great progress has been made in recent years, large displacements and adverse imaging conditions as observed in natural outdoor environments are still very challenging for current approaches to reconstruction and motion estimation. In this paper, we propose a unified random field model which reasons jointly about 3D scene flow as well as the location, shape and motion of vehicles in the observed scene. We formulate the problem as the task of decomposing the scene into a small number of rigidly moving objects sharing the same motion parameters. Thus, our formulation effectively introduces long-range spatial dependencies which commonly employed local rigidity priors are lacking. Our inference algorithm then estimates the association of image segments and object hypotheses together with their three-dimensional shape and motion. We demonstrate the potential of the proposed approach by introducing a novel challenging scene flow benchmark which allows for a thorough comparison of the proposed scene flow approach with respect to various baseline models. In contrast to previous benchmarks, our evaluation is the first to provide stereo and optical flow ground truth for dynamic real-world urban scenes at large scale. Our experiments reveal that rigid motion segmentation can be utilized as an effective regularizer for the scene flow problem, improving upon existing two-frame scene flow methods. At the same time, our method yields plausible object segmentations without requiring an explicitly trained recognition model for a specific object class.
Latex Bibtex Citation:
@article{Menze2018JPRS,
author = {Moritz Menze and Christian Heipke and Andreas Geiger},
title = {Object Scene Flow},
journal = {ISPRS Journal of Photogrammetry and Remote Sensing (JPRS)},
year = {2018}
}
Latex Bibtex Citation:
@article{Menze2018JPRS,
author = {Moritz Menze and Christian Heipke and Andreas Geiger},
title = {Object Scene Flow},
journal = {ISPRS Journal of Photogrammetry and Remote Sensing (JPRS)},
year = {2018}
}

Learning Transformation Invariant Representations with Weak Supervision
B. Coors, A. Condurache, A. Mertins and A. Geiger
International Conference on Computer Vision Theory and Applications (VISAPP), 2018
B. Coors, A. Condurache, A. Mertins and A. Geiger
International Conference on Computer Vision Theory and Applications (VISAPP), 2018
Abstract: Deep convolutional neural networks are the current state-of-the-art solution to many computer vision tasks. However, their ability to handle large global and local image transformations is limited. Consequently, extensive data augmentation is often utilized to incorporate prior knowledge about desired invariances to geometric transformations such as rotations or scale changes. In this work, we combine data augmentation with an unsupervised loss which enforces similarity between the predictions of augmented copies of an input sample. Our loss acts as an effective regularizer which facilitates the learning of transformation invariant representations. We investigate the effectiveness of the proposed similarity loss on rotated MNIST and the German Traffic Sign Recognition Benchmark (GTSRB) in the context of different classification models including ladder networks. Our experiments demonstrate improvements with respect to the standard data augmentation approach for supervised and semi-supervised learning tasks, in particular in the presence of little annotated data. In addition, we analyze the performance of the proposed approach with respect to its hyperparameters, including the strength of the regularization as well as the layer where representation similarity is enforced.
Latex Bibtex Citation:
@inproceedings{Coors2018VISAPP,
author = {Benjamin Coors and Alexandru Condurache and Alfred Mertins and Andreas Geiger},
title = {Learning Transformation Invariant Representations with Weak Supervision},
booktitle = {International Conference on Computer Vision Theory and Applications (VISAPP)},
year = {2018}
}
Latex Bibtex Citation:
@inproceedings{Coors2018VISAPP,
author = {Benjamin Coors and Alexandru Condurache and Alfred Mertins and Andreas Geiger},
title = {Learning Transformation Invariant Representations with Weak Supervision},
booktitle = {International Conference on Computer Vision Theory and Applications (VISAPP)},
year = {2018}
}

Augmented Reality Meets Computer Vision: Efficient Data Generation for Urban Driving Scenes
. AlhaijaandHassan, . MustikovelaandSiva, . MeschederandLars, . GeigerandAndreas and . RotherandCarsten
International Journal of Computer Vision (IJCV), 2018
. AlhaijaandHassan, . MustikovelaandSiva, . MeschederandLars, . GeigerandAndreas and . RotherandCarsten
International Journal of Computer Vision (IJCV), 2018
Abstract: The success of deep learning in computer vision is based on the availability of large annotated datasets. To lower the need for hand labeled images, virtually rendered 3D worlds have recently gained popularity. Unfortunately, creating realistic 3D content is challenging on its own and requires significant human effort. In this work, we propose an alternative paradigm which combines real and synthetic data for learning semantic instance segmentation and object detection models. Exploiting the fact that not all aspects of the scene are equally important for this task, we propose to augment real-world imagery with virtual objects of the target category. Capturing real-world images at large scale is easy and cheap, and directly provides real background appearances without the need for creating complex 3D models of the environment. We present an efficient procedure to augment these images with virtual objects. In contrast to modeling complete 3D environments, our data augmentation approach requires only a few user interactions in combination with 3D models of the target object category. Leveraging our approach, we introduce a novel dataset of augmented urban driving scenes with 360 degree images that are used as environment maps to create realistic lighting and reflections on rendered objects. We analyze the significance of realistic object placement by comparing manual placement by humans to automatic methods based on semantic scene analysis. This allows us to create composite images which exhibit both realistic background appearance as well as a large number of complex object arrangements. Through an extensive set of experiments, we conclude the right set of parameters to produce augmented data which can maximally enhance the performance of instance segmentation models. Further, we demonstrate the utility of the proposed approach on training standard deep models for semantic instance segmentation and object detection of cars in outdoor driving scenarios. We test the models trained on our augmented data on the KITTI 2015 dataset, which we have annotated with pixel-accurate ground truth, and on the Cityscapes dataset. Our experiments demonstrate that the models trained on augmented imagery generalize better than those trained on fully synthetic data or models trained on limited amounts of annotated real data.
Latex Bibtex Citation:
@article{Alhaija2018IJCV,
author = { AlhaijaandHassan and MustikovelaandSiva and MeschederandLars and GeigerandAndreas and RotherandCarsten},
title = {Augmented Reality Meets Computer Vision: Efficient Data Generation for Urban Driving Scenes},
journal = {International Journal of Computer Vision (IJCV)},
year = {2018}
}
Latex Bibtex Citation:
@article{Alhaija2018IJCV,
author = { AlhaijaandHassan and MustikovelaandSiva and MeschederandLars and GeigerandAndreas and RotherandCarsten},
title = {Augmented Reality Meets Computer Vision: Efficient Data Generation for Urban Driving Scenes},
journal = {International Journal of Computer Vision (IJCV)},
year = {2018}
}
2017

The Numerics of GANs (spotlight)
L. Mescheder, S. Nowozin and A. Geiger
Advances in Neural Information Processing Systems (NIPS), 2017
L. Mescheder, S. Nowozin and A. Geiger
Advances in Neural Information Processing Systems (NIPS), 2017
Abstract: In this paper, we analyze the numerics of common algorithms for training Generative Adversarial Networks (GANs). Using the formalism of smooth two-player games we analyze the associated gradient vector field of GAN training objectives. Our findings suggest that the convergence of current algorithms suffers due to two factors: i) presence of eigenvalues of the Jacobian of the gradient vector field with zero real-part, and ii) eigenvalues with big imaginary part. Using these findings, we design a new algorithm that overcomes some of these limitations and has better convergence properties. Experimentally, we demonstrate its superiority on training common GAN architectures and show convergence on GAN architectures that are known to be notoriously hard to train.
Latex Bibtex Citation:
@inproceedings{Mescheder2017NIPS,
author = {Lars Mescheder and Sebastian Nowozin and Andreas Geiger},
title = {The Numerics of GANs},
booktitle = {Advances in Neural Information Processing Systems (NIPS)},
year = {2017}
}
Latex Bibtex Citation:
@inproceedings{Mescheder2017NIPS,
author = {Lars Mescheder and Sebastian Nowozin and Andreas Geiger},
title = {The Numerics of GANs},
booktitle = {Advances in Neural Information Processing Systems (NIPS)},
year = {2017}
}

Bounding Boxes, Segmentations and Object Coordinates: How Important is Recognition for 3D Scene Flow Estimation ...
A. Behl, O. Jafari, S. Mustikovela, H. Alhaija, C. Rother and A. Geiger
International Conference on Computer Vision (ICCV), 2017
A. Behl, O. Jafari, S. Mustikovela, H. Alhaija, C. Rother and A. Geiger
International Conference on Computer Vision (ICCV), 2017
Abstract: Existing methods for 3D scene flow estimation often fail in the presence of large displacement or local ambiguities, e.g., at texture-less or reflective surfaces. However, these challenges are omnipresent in dynamic road scenes, which is the focus of this work. Our main contribution is to overcome these 3D motion estimation problems by exploiting recognition. In particular, we investigate the importance of recognition granularity, from coarse 2D bounding box estimates over 2D instance segmentations to fine-grained 3D object part predictions. We compute these cues using CNNs trained on a newly annotated dataset of stereo images and integrate them into a CRF-based model for robust 3D scene flow estimation - an approach we term Instance Scene Flow. We analyze the importance of each recognition cue in an ablation study and observe that the instance segmentation cue is by far strongest, in our setting. We demonstrate the effectiveness of our method on the challenging KITTI 2015 scene flow benchmark where we achieve state-of-the-art performance at the time of submission.
Latex Bibtex Citation:
@inproceedings{Behl2017ICCV,
author = {Aseem Behl and Omid Hosseini Jafari and Siva Karthik Mustikovela and Hassan Abu Alhaija and Carsten Rother and Andreas Geiger},
title = {Bounding Boxes, Segmentations and Object Coordinates: How Important is Recognition for 3D Scene Flow Estimation in Autonomous Driving Scenarios?},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2017}
}
Latex Bibtex Citation:
@inproceedings{Behl2017ICCV,
author = {Aseem Behl and Omid Hosseini Jafari and Siva Karthik Mustikovela and Hassan Abu Alhaija and Carsten Rother and Andreas Geiger},
title = {Bounding Boxes, Segmentations and Object Coordinates: How Important is Recognition for 3D Scene Flow Estimation in Autonomous Driving Scenarios?},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2017}
}

Sparsity Invariant CNNs (oral, best student paper award)
J. Uhrig, N. Schneider, L. Schneider, U. Franke, T. Brox and A. Geiger
International Conference on 3D Vision (3DV), 2017
J. Uhrig, N. Schneider, L. Schneider, U. Franke, T. Brox and A. Geiger
International Conference on 3D Vision (3DV), 2017
Abstract: In this paper, we consider convolutional neural networks operating on sparse inputs with an application to depth upsampling from sparse laser scan data. First, we show that traditional convolutional networks perform poorly when applied to sparse data even when the location of missing data is provided to the network. To overcome this problem, we propose a simple yet effective sparse convolution layer which explicitly considers the location of missing data during the convolution operation. We demonstrate the benefits of the proposed network architecture in synthetic and real experiments \wrt various baseline approaches. Compared to dense baselines, the proposed sparse convolution network generalizes well to novel datasets and is invariant to the level of sparsity in the data. For our evaluation, we derive a novel dataset from the KITTI benchmark, comprising 93k depth annotated RGB images. Our dataset allows for training and evaluating depth upsampling and depth prediction techniques in challenging real-world settings.
Latex Bibtex Citation:
@inproceedings{Uhrig2017THREEDV,
author = {Jonas Uhrig and Nick Schneider and Lukas Schneider and Uwe Franke and Thomas Brox and Andreas Geiger},
title = {Sparsity Invariant CNNs},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2017}
}
Latex Bibtex Citation:
@inproceedings{Uhrig2017THREEDV,
author = {Jonas Uhrig and Nick Schneider and Lukas Schneider and Uwe Franke and Thomas Brox and Andreas Geiger},
title = {Sparsity Invariant CNNs},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2017}
}

OctNetFusion: Learning Depth Fusion from Data (oral)
G. Riegler, A. Ulusoy, H. Bischof and A. Geiger
International Conference on 3D Vision (3DV), 2017
G. Riegler, A. Ulusoy, H. Bischof and A. Geiger
International Conference on 3D Vision (3DV), 2017
Abstract: In this paper, we present a learning based approach to depth fusion, i.e., dense 3D reconstruction from multiple depth images. The most common approach to depth fusion is based on averaging truncated signed distance functions, which was originally proposed by Curless and Levoy in 1996. While this method is simple and provides great results, it is not able to reconstruct (partially) occluded surfaces and requires a large number frames to filter out sensor noise and outliers. Motivated by the availability of large 3D model repositories and recent advances in deep learning, we present a novel 3D CNN architecture that learns to predict an implicit surface representation from the input depth maps. Our learning based method significantly outperforms the traditional volumetric fusion approach in terms of noise reduction and outlier suppression. By learning the structure of real world 3D objects and scenes, our approach is further able to reconstruct occluded regions and to fill in gaps in the reconstruction. We demonstrate that our learning based approach outperforms both vanilla TSDF fusion as well as TV-L1 fusion on the task of volumetric fusion. Further, we demonstrate state-of-the-art 3D shape completion results.
Latex Bibtex Citation:
@inproceedings{Riegler2017THREEDV,
author = {Gernot Riegler and Ali Osman Ulusoy and Horst Bischof and Andreas Geiger},
title = {OctNetFusion: Learning Depth Fusion from Data},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2017}
}
Latex Bibtex Citation:
@inproceedings{Riegler2017THREEDV,
author = {Gernot Riegler and Ali Osman Ulusoy and Horst Bischof and Andreas Geiger},
title = {OctNetFusion: Learning Depth Fusion from Data},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2017}
}

Augmented Reality Meets Deep Learning for Car Instance Segmentation in Urban Scenes
H. Alhaija, S. Mustikovela, L. Mescheder, A. Geiger and C. Rother
British Machine Vision Conference (BMVC), 2017
H. Alhaija, S. Mustikovela, L. Mescheder, A. Geiger and C. Rother
British Machine Vision Conference (BMVC), 2017
Abstract: The success of deep learning in computer vision is based on the availability of large annotated datasets. To lower the need for hand labeled images, virtually rendered 3D worlds have recently gained popularity. Unfortunately, creating realistic 3D content is challenging on its own and requires significant human effort. In this work, we propose an alternative paradigm which combines real and synthetic data for learning semantic instance segmentation models. Exploiting the fact that not all aspects of the scene are equally important for this task, we propose to augment real-world imagery with virtual objects of the target category. Capturing real-world images at large scale is easy and cheap, and directly provides real background appearances without the need for creating complex 3D models of the environment. We present an efficient procedure to augment these images with virtual objects. This allows us to create realistic composite images which exhibit both realistic background appearance as well as a large number of complex object arrangements. In contrast to modeling complete 3D environments, our data augmentation approach requires only a few user interactions in combination with 3D shapes of the target object category. We demonstrate the utility of the proposed approach for training a state-of-the-art high-capacity deep model for semantic instance segmentation. In particular, we consider the task of segmenting car instances on the KITTI dataset which we have annotated with pixel-accurate ground truth. Our experiments demonstrate that models trained on augmented imagery generalize better than those trained on synthetic data or models trained on limited amounts of annotated real data.
Latex Bibtex Citation:
@inproceedings{Alhaija2017BMVC,
author = {Hassan Abu Alhaija and Siva Karthik Mustikovela and Lars Mescheder and Andreas Geiger and Carsten Rother},
title = {Augmented Reality Meets Deep Learning for Car Instance Segmentation in Urban Scenes},
booktitle = {British Machine Vision Conference (BMVC)},
year = {2017}
}
Latex Bibtex Citation:
@inproceedings{Alhaija2017BMVC,
author = {Hassan Abu Alhaija and Siva Karthik Mustikovela and Lars Mescheder and Andreas Geiger and Carsten Rother},
title = {Augmented Reality Meets Deep Learning for Car Instance Segmentation in Urban Scenes},
booktitle = {British Machine Vision Conference (BMVC)},
year = {2017}
}

Direct Visual Odometry for a Fisheye-Stereo Camera
P. Liu, L. Heng, T. Sattler, A. Geiger and M. Pollefeys
International Conference on Intelligent Robots and Systems (IROS), 2017
P. Liu, L. Heng, T. Sattler, A. Geiger and M. Pollefeys
International Conference on Intelligent Robots and Systems (IROS), 2017
Abstract: We present a direct visual odometry algorithm for a fisheye-stereo camera. Our algorithm performs simultaneous camera motion estimation and semi-dense reconstruction. The pipeline consists of two threads: a tracking thread and a mapping thread. In the tracking thread, we estimate the camera pose via semi-dense direct image alignment. To have a wider field of view (FoV) which is important for robotic perception, we use fisheye images directly without converting them to conventional pinhole images which come with a limited FoV. To address the epipolar curve problem, plane-sweeping stereo is used for stereo matching and depth initialization. Multiple depth hypotheses are tracked for selected pixels to better capture the uncertainty characteristics of stereo matching. Temporal motion stereo is then used to refine the depth and remove false positive depth hypotheses. Our implementation runs at an average of 20 Hz on a low-end PC. We run experiments in outdoor environments to validate our algorithm, and discuss the experimental results. We experimentally show that we are able to estimate 6D poses with low drift, and at the same time, do semi-dense 3D reconstruction with high accuracy.
Latex Bibtex Citation:
@inproceedings{Liu2017IROS,
author = {Peidong Liu and Lionel Heng and Torsten Sattler and Andreas Geiger and Marc Pollefeys},
title = {Direct Visual Odometry for a Fisheye-Stereo Camera},
booktitle = {International Conference on Intelligent Robots and Systems (IROS)},
year = {2017}
}
Latex Bibtex Citation:
@inproceedings{Liu2017IROS,
author = {Peidong Liu and Lionel Heng and Torsten Sattler and Andreas Geiger and Marc Pollefeys},
title = {Direct Visual Odometry for a Fisheye-Stereo Camera},
booktitle = {International Conference on Intelligent Robots and Systems (IROS)},
year = {2017}
}

Adversarial Variational Bayes: Unifying Variational Autoencoders and Generative Adversarial Networks
L. Mescheder, S. Nowozin and A. Geiger
International Conference on Machine learning (ICML), 2017
L. Mescheder, S. Nowozin and A. Geiger
International Conference on Machine learning (ICML), 2017
Abstract: Variational Autoencoders (VAEs) are expressive latent variable models that can be used to learn complex probability distributions from training data. However, the quality of the resulting model crucially relies on the expressiveness of the inference model. We introduce Adversarial Variational Bayes (AVB), a technique for training Variational Autoencoders with arbitrarily expressive inference models. We achieve this by introducing an auxiliary discriminative network that allows to rephrase the maximum-likelihood-problem as a two-player game, hence establishing a principled connection between VAEs and Generative Adversarial Networks (GANs). We show that in the nonparametric limit our method yields an exact maximum-likelihood assignment for the parameters of the generative model, as well as the exact posterior distribution over the latent variables given an observation. Contrary to competing approaches which combine VAEs with GANs, our approach has a clear theoretical justification, retains most advantages of standard Variational Autoencoders and is easy to implement.
Latex Bibtex Citation:
@inproceedings{Mescheder2017ICML,
author = {Lars Mescheder and Sebastian Nowozin and Andreas Geiger},
title = {Adversarial Variational Bayes: Unifying Variational Autoencoders and Generative Adversarial Networks},
booktitle = {International Conference on Machine learning (ICML)},
year = {2017}
}
Latex Bibtex Citation:
@inproceedings{Mescheder2017ICML,
author = {Lars Mescheder and Sebastian Nowozin and Andreas Geiger},
title = {Adversarial Variational Bayes: Unifying Variational Autoencoders and Generative Adversarial Networks},
booktitle = {International Conference on Machine learning (ICML)},
year = {2017}
}

Toroidal Constraints for Two Point Localization Under High Outlier Ratios
F. Camposeco, T. Sattler, A. Cohen, A. Geiger and M. Pollefeys
Conference on Computer Vision and Pattern Recognition (CVPR), 2017
F. Camposeco, T. Sattler, A. Cohen, A. Geiger and M. Pollefeys
Conference on Computer Vision and Pattern Recognition (CVPR), 2017
Abstract: Localizing a query image against a 3D model at large scale is a hard problem, since 2D-3D matches become more and more ambiguous as the model size increases. This creates a need for pose estimation strategies that can handle very low inlier ratios. In this paper, we draw new insights on the geometric information available from the 2D-3D matching process. As modern descriptors are not invariant against large variations in viewpoint, we are able to find the rays in space used to triangulate a given point that are closest to a query descriptor. It is well known that two correspondences constrain the camera to lie on the surface of a torus. Adding the knowledge of direction of triangulation, we are able to approximate the position of the camera from \emphtwo matches alone. We derive a geometric solver that can compute this position in under 1 microsecond. Using this solver, we propose a simple yet powerful outlier filter which scales quadratically in the number of matches. We validate the accuracy of our solver and demonstrate the usefulness of our method in real world settings.
Latex Bibtex Citation:
@inproceedings{Camposeco2017CVPR,
author = {Federico Camposeco and Torsten Sattler and Andrea Cohen and Andreas Geiger and Marc Pollefeys},
title = {Toroidal Constraints for Two Point Localization Under High Outlier Ratios},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}
Latex Bibtex Citation:
@inproceedings{Camposeco2017CVPR,
author = {Federico Camposeco and Torsten Sattler and Andrea Cohen and Andreas Geiger and Marc Pollefeys},
title = {Toroidal Constraints for Two Point Localization Under High Outlier Ratios},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}

A Multi-View Stereo Benchmark with High-Resolution Images and Multi-Camera Videos
T. Schöps, J. Schönberger, S. Galliani, T. Sattler, K. Schindler, M. Pollefeys and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2017
T. Schöps, J. Schönberger, S. Galliani, T. Sattler, K. Schindler, M. Pollefeys and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2017
Abstract: Motivated by the limitations of existing multi-view stereo benchmarks, we present a novel dataset for this task. Towards this goal, we recorded a variety of indoor and outdoor scenes using a high-precision laser scanner and captured both high-resolution DSLR imagery as well as synchronized low-resolution stereo videos with varying fields-of-view. To align the images with the laser scans, we propose a robust technique which minimizes photometric errors conditioned on the geometry. In contrast to previous datasets, our benchmark provides novel challenges and covers a diverse set of viewpoints and scene types, ranging from natural scenes to man-made indoor and outdoor environments. Furthermore, we provide data at significantly higher temporal and spatial resolution. Our benchmark is the first to cover the important use case of hand-held mobile devices while also providing high-resolution DSLR camera images. We make our datasets and an online evaluation server available at http://www.eth3d.net.
Latex Bibtex Citation:
@inproceedings{Schoeps2017CVPR,
author = {Thomas Schöps and Johannes Schönberger and Silvano Galliani and Torsten Sattler and Konrad Schindler and Marc Pollefeys and Andreas Geiger},
title = {A Multi-View Stereo Benchmark with High-Resolution Images and Multi-Camera Videos},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}
Latex Bibtex Citation:
@inproceedings{Schoeps2017CVPR,
author = {Thomas Schöps and Johannes Schönberger and Silvano Galliani and Torsten Sattler and Konrad Schindler and Marc Pollefeys and Andreas Geiger},
title = {A Multi-View Stereo Benchmark with High-Resolution Images and Multi-Camera Videos},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}

Semantic Multi-view Stereo: Jointly Estimating Objects and Voxels
A. Ulusoy, M. Black and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2017
A. Ulusoy, M. Black and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2017
Abstract: Dense 3D reconstruction from RGB images is a highly ill-posed problem due to occlusions, textureless or reflective surfaces, as well as other challenges. We propose object-level shape priors to address these ambiguities. Towards this goal, we formulate a probabilistic model that integrates multi-view image evidence with 3D shape information from multiple objects. Inference in this model yields a dense 3D reconstruction of the scene as well as the existence and precise 3D pose of the objects in it. Our approach is able to recover fine details not captured in the input shapes while defaulting to the input models in occluded regions where image evidence is weak. Due to its probabilistic nature, the approach is able to cope with the approximate geometry of the 3D models as well as input shapes that are not present in the scene. We evaluate the approach quantitatively on several challenging indoor and outdoor datasets.
Latex Bibtex Citation:
@inproceedings{Ulusoy2017CVPR,
author = {Ali Osman Ulusoy and Michael Black and Andreas Geiger},
title = {Semantic Multi-view Stereo: Jointly Estimating Objects and Voxels},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}
Latex Bibtex Citation:
@inproceedings{Ulusoy2017CVPR,
author = {Ali Osman Ulusoy and Michael Black and Andreas Geiger},
title = {Semantic Multi-view Stereo: Jointly Estimating Objects and Voxels},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}

Slow Flow: Exploiting High-Speed Cameras for Accurate and Diverse Optical Flow Reference Data (oral)
J. Janai, F. Güney, J. Wulff, M. Black and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2017
J. Janai, F. Güney, J. Wulff, M. Black and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2017
Abstract: Existing optical flow datasets are limited in size and variability due to the difficulty of capturing dense ground truth. In this paper, we tackle this problem by tracking pixels through densely sampled space-time volumes recorded with a high-speed video camera. Our model exploits the linearity of small motions and reasons about occlusions from multiple frames. Using our technique, we are able to establish accurate reference flow fields outside the laboratory in natural environments. Besides, we show how our predictions can be used to augment the input images with realistic motion blur. We demonstrate the quality of the produced flow fields on synthetic and real-world datasets. Finally, we collect a novel challenging optical flow dataset by applying our technique on data from a high-speed camera and analyze the performance of the state-of-the-art in optical flow under various levels of motion blur.
Latex Bibtex Citation:
@inproceedings{Janai2017CVPR,
author = {Joel Janai and Fatma Güney and Jonas Wulff and Michael Black and Andreas Geiger},
title = {Slow Flow: Exploiting High-Speed Cameras for Accurate and Diverse Optical Flow Reference Data},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}
Latex Bibtex Citation:
@inproceedings{Janai2017CVPR,
author = {Joel Janai and Fatma Güney and Jonas Wulff and Michael Black and Andreas Geiger},
title = {Slow Flow: Exploiting High-Speed Cameras for Accurate and Diverse Optical Flow Reference Data},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}

OctNet: Learning Deep 3D Representations at High Resolutions (oral)
G. Riegler, A. Ulusoy and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2017
G. Riegler, A. Ulusoy and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2017
Abstract: We present OctNet, a representation for deep learning with sparse 3D data. In contrast to existing models, our representation enables 3D convolutional networks which are both deep and high resolution. Towards this goal, we exploit the sparsity in the input data to hierarchically partition the space using a set of unbalanced octrees where each leaf node stores a pooled feature representation. This allows to focus memory allocation and computation to the relevant dense regions and enables deeper networks without compromising resolution. We demonstrate the utility of our OctNet representation by analyzing the impact of resolution on several 3D tasks including 3D object classification, orientation estimation and point cloud labeling.
Latex Bibtex Citation:
@inproceedings{Riegler2017CVPR,
author = {Gernot Riegler and Ali Osman Ulusoy and Andreas Geiger},
title = {OctNet: Learning Deep 3D Representations at High Resolutions},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}
Latex Bibtex Citation:
@inproceedings{Riegler2017CVPR,
author = {Gernot Riegler and Ali Osman Ulusoy and Andreas Geiger},
title = {OctNet: Learning Deep 3D Representations at High Resolutions},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}

Computer Vision for Autonomous Vehicles: Problems, Datasets and State-of-the-Art
J. Janai, F. Güney, A. Behl and A. Geiger
Arxiv, 2017
J. Janai, F. Güney, A. Behl and A. Geiger
Arxiv, 2017
Abstract: Recent years have witnessed amazing progress in AI related fields such as computer vision, machine learning and autonomous vehicles. As with any rapidly growing field, however, it becomes increasingly difficult to stay up-to-date or enter the field as a beginner. While several topic specific survey papers have been written, to date no general survey on problems, datasets and methods in computer vision for autonomous vehicles exists. This paper attempts to narrow this gap by providing a state-of-the-art survey on this topic. Our survey includes both the historically most relevant literature as well as the current state-of-the-art on several specific topics, including recognition, reconstruction, motion estimation, tracking, scene understanding and end-to-end learning. Towards this goal, we first provide a taxonomy to classify each approach and then analyze the performance of the state-of-the-art on several challenging benchmarking datasets including KITTI, ISPRS, MOT and Cityscapes. Besides, we discuss open problems and current research challenges. To ease accessibility and accommodate missing references, we will also provide an interactive platform which allows to navigate topics and methods, and provides additional information and project links for each paper.
Latex Bibtex Citation:
@article{Janai2017ARXIV,
author = {Joel Janai and Fatma Güney and Aseem Behl and Andreas Geiger},
title = {Computer Vision for Autonomous Vehicles: Problems, Datasets and State-of-the-Art},
journal = {Arxiv},
year = {2017}
}
Latex Bibtex Citation:
@article{Janai2017ARXIV,
author = {Joel Janai and Fatma Güney and Aseem Behl and Andreas Geiger},
title = {Computer Vision for Autonomous Vehicles: Problems, Datasets and State-of-the-Art},
journal = {Arxiv},
year = {2017}
}
2016

Map-Based Probabilistic Visual Self-Localization
M. Brubaker, A. Geiger and R. Urtasun
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2016
M. Brubaker, A. Geiger and R. Urtasun
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2016
Abstract: Accurate and efficient self-localization is a critical problem for autonomous systems. This paper describes an affordable solution to vehicle self-localization which uses odometry computed from two video cameras and road maps as the sole inputs. The core of the method is a probabilistic model for which an efficient approximate inference algorithm is derived. The inference algorithm is able to utilize distributed computation in order to meet the real-time requirements of autonomous systems in some instances. Because of the probabilistic nature of the model the method is capable of coping with various sources of uncertainty including noise in the visual odometry and inherent ambiguities in the map (e.g., in a Manhattan world). By exploiting freely available, community developed maps and visual odometry measurements, the proposed method is able to localize a vehicle to 4m on average after 52 seconds of driving on maps which contain more than 2,150km of drivable roads.
Latex Bibtex Citation:
@article{Brubaker2016PAMI,
author = {Marcus A. Brubaker and Andreas Geiger and Raquel Urtasun},
title = {Map-Based Probabilistic Visual Self-Localization},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2016}
}
Latex Bibtex Citation:
@article{Brubaker2016PAMI,
author = {Marcus A. Brubaker and Andreas Geiger and Raquel Urtasun},
title = {Map-Based Probabilistic Visual Self-Localization},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2016}
}

Probabilistic Duality for Parallel Gibbs Sampling without Graph Coloring
L. Mescheder, S. Nowozin and A. Geiger
Arxiv, 2016
L. Mescheder, S. Nowozin and A. Geiger
Arxiv, 2016
Abstract: We present a new notion of probabilistic duality for random variables involving mixture distributions. Using this notion, we show how to implement a highly-parallelizable Gibbs sampler for weakly coupled discrete pairwise graphical models with strictly positive factors that requires almost no preprocessing and is easy to implement. Moreover, we show how our method can be combined with blocking to improve mixing. Even though our method leads to inferior mixing times compared to a sequential Gibbs sampler, we argue that our method is still very useful for large dynamic networks, where factors are added and removed on a continuous basis, as it is hard to maintain a graph coloring in this setup. Similarly, our method is useful for parallelizing Gibbs sampling in graphical models that do not allow for graph colorings with a small number of colors such as densely connected graphs.
Latex Bibtex Citation:
@article{Mescheder2016ARXIV,
author = {Lars Mescheder and Sebastian Nowozin and Andreas Geiger},
title = {Probabilistic Duality for Parallel Gibbs Sampling without Graph Coloring},
journal = {Arxiv},
year = {2016}
}
Latex Bibtex Citation:
@article{Mescheder2016ARXIV,
author = {Lars Mescheder and Sebastian Nowozin and Andreas Geiger},
title = {Probabilistic Duality for Parallel Gibbs Sampling without Graph Coloring},
journal = {Arxiv},
year = {2016}
}

Deep Discrete Flow
F. Güney and A. Geiger
Asian Conference on Computer Vision (ACCV), 2016
F. Güney and A. Geiger
Asian Conference on Computer Vision (ACCV), 2016
Abstract: Motivated by the success of deep learning techniques in matching problems, we present a method for learning context-aware features for solving optical flow using discrete optimization. Towards this goal, we present an efficient way of training a context network with a large receptive field size on top of a local network using dilated convolutions on patches. We perform feature matching by comparing each pixel in the reference image to every pixel in the target image, utilizing fast GPU matrix multiplication. The matching cost volume from the network's output forms the data term for discrete MAP inference in a pairwise Markov random field. We provide an extensive empirical investigation of network architectures and model parameters. At the time of submission, our method ranks second on the challenging MPI Sintel test set.
Latex Bibtex Citation:
@inproceedings{Guney2016ACCV,
author = {Fatma Güney and Andreas Geiger},
title = {Deep Discrete Flow},
booktitle = {Asian Conference on Computer Vision (ACCV)},
year = {2016}
}
Latex Bibtex Citation:
@inproceedings{Guney2016ACCV,
author = {Fatma Güney and Andreas Geiger},
title = {Deep Discrete Flow},
booktitle = {Asian Conference on Computer Vision (ACCV)},
year = {2016}
}

Semantic Instance Annotation of Street Scenes by 3D to 2D Label Transfer
J. Xie, M. Kiefel, M. Sun and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2016
J. Xie, M. Kiefel, M. Sun and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2016
Abstract: Semantic annotations are vital for training models for object recognition, semantic segmentation or scene understanding. Unfortunately, pixelwise annotation of images at very large scale is labor-intensive and only little labeled data is available, particularly at instance level and for street scenes. In this paper, we propose to tackle this problem by lifting the semantic instance labeling task from 2D into 3D. Given reconstructions from stereo or laser data, we annotate static 3D scene elements with rough bounding primitives and develop a probabilistic model which transfers this information into the image domain. We leverage our method to obtain 2D labels for a novel suburban video dataset which we have collected, resulting in 400k semantic and instance image annotations. A comparison of our method to state-of-the-art label transfer baselines reveals that 3D information enables more efficient annotation while at the same time resulting in improved accuracy and time-coherent labels.
Latex Bibtex Citation:
@inproceedings{Xie2016CVPR,
author = {Jun Xie and Martin Kiefel and Ming-Ting Sun and Andreas Geiger},
title = {Semantic Instance Annotation of Street Scenes by 3D to 2D Label Transfer},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2016}
}
Latex Bibtex Citation:
@inproceedings{Xie2016CVPR,
author = {Jun Xie and Martin Kiefel and Ming-Ting Sun and Andreas Geiger},
title = {Semantic Instance Annotation of Street Scenes by 3D to 2D Label Transfer},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2016}
}

Patches, Planes and Probabilities: A Non-local Prior for Volumetric 3D Reconstruction
A. Ulusoy, M. Black and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2016
A. Ulusoy, M. Black and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2016
Abstract: We propose a non-local structured prior for volumetric multi-view 3D reconstruction. Towards this goal, we present a random field model based on ray potentials in which assumptions about 3D surface patches such as planarity or Manhattan world constraints can be efficiently encoded as probabilistic priors. We further derive an inference algorithm that reasons jointly about voxels, pixels and image segments, and estimates marginal distributions of appearance, occupancy, depth, normals and planarity. Key to tractable inference is a novel hybrid representation that spans both voxel and pixel space and that integrates non-local information from 2D image segmentations in a principled way. We compare our non-local prior to commonly employed local smoothness assumptions and a variety of state-of-the-art volumetric reconstruction baselines on challenging outdoor scenes with textureless and reflective surfaces. Our experiments indicate that regularizing over larger distances has the potential to resolve ambiguities where local regularizers fail.
Latex Bibtex Citation:
@inproceedings{Ulusoy2016CVPR,
author = {Ali Osman Ulusoy and Michael Black and Andreas Geiger},
title = {Patches, Planes and Probabilities: A Non-local Prior for Volumetric 3D Reconstruction},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2016}
}
Latex Bibtex Citation:
@inproceedings{Ulusoy2016CVPR,
author = {Ali Osman Ulusoy and Michael Black and Andreas Geiger},
title = {Patches, Planes and Probabilities: A Non-local Prior for Volumetric 3D Reconstruction},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2016}
}
2015

Exploiting Object Similarity in 3D Reconstruction
C. Zhou, F. Güney, Y. Wang and A. Geiger
International Conference on Computer Vision (ICCV), 2015
C. Zhou, F. Güney, Y. Wang and A. Geiger
International Conference on Computer Vision (ICCV), 2015
Abstract: Despite recent progress, reconstructing outdoor scenes in 3D from movable platforms remains a highly difficult endeavor. Challenges include low frame rates, occlusions, large distortions and difficult lighting conditions. In this paper, we leverage the fact that the larger the reconstructed area, the more likely objects of similar type and shape will occur in the scene. This is particularly true for outdoor scenes where buildings and vehicles often suffer from missing texture or reflections, but share similarity in 3D shape. We take advantage of this shape similarity by locating objects using detectors and jointly reconstructing them while learning a volumetric model of their shape. This allows us to reduce noise while completing missing surfaces as objects of similar shape benefit from all observations for the respective category. We evaluate our approach with respect to LIDAR ground truth on a novel challenging suburban dataset and show its advantages over the state-of-the-art.
Latex Bibtex Citation:
@inproceedings{Zhou2015ICCV,
author = {Chen Zhou and Fatma Güney and Yizhou Wang and Andreas Geiger},
title = {Exploiting Object Similarity in 3D Reconstruction},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2015}
}
Latex Bibtex Citation:
@inproceedings{Zhou2015ICCV,
author = {Chen Zhou and Fatma Güney and Yizhou Wang and Andreas Geiger},
title = {Exploiting Object Similarity in 3D Reconstruction},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2015}
}

FollowMe: Efficient Online Min-Cost Flow Tracking with Bounded Memory and Computation
P. Lenz, A. Geiger and R. Urtasun
International Conference on Computer Vision (ICCV), 2015
P. Lenz, A. Geiger and R. Urtasun
International Conference on Computer Vision (ICCV), 2015
Abstract: One of the most popular approaches to multi-target tracking is tracking-by-detection. Current min-cost flow algorithms which solve the data association problem optimally have three main drawbacks: they are computationally expensive, they assume that the whole video is given as a batch, and they scale badly in memory and computation with the length of the video sequence. In this paper, we address each of these issues, resulting in a computationally and memory-bounded solution. First, we introduce a dynamic version of the successive shortest-path algorithm which solves the data association problem optimally while reusing computation, resulting in faster inference than standard solvers. Second, we address the optimal solution to the data association problem when dealing with an incoming stream of data (i.e., online setting). Finally, we present our main contribution which is an approximate online solution with bounded memory and computation which is capable of handling videos of arbitrary length while performing tracking in real time. We demonstrate the effectiveness of our algorithms on the KITTI and PETS2009 benchmarks and show state-of-the-art performance, while being significantly faster than existing solvers.
Latex Bibtex Citation:
@inproceedings{Lenz2015ICCV,
author = {Philip Lenz and Andreas Geiger and Raquel Urtasun},
title = {FollowMe: Efficient Online Min-Cost Flow Tracking with Bounded Memory and Computation},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2015}
}
Latex Bibtex Citation:
@inproceedings{Lenz2015ICCV,
author = {Philip Lenz and Andreas Geiger and Raquel Urtasun},
title = {FollowMe: Efficient Online Min-Cost Flow Tracking with Bounded Memory and Computation},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2015}
}

Joint 3D Estimation of Vehicles and Scene Flow (oral)
M. Menze, C. Heipke and A. Geiger
ISPRS Workshop on Image Sequence Analysis (ISA), 2015
M. Menze, C. Heipke and A. Geiger
ISPRS Workshop on Image Sequence Analysis (ISA), 2015
Abstract: Three-dimensional reconstruction of dynamic scenes is an important prerequisite for applications like mobile robotics or autonomous driving. While much progress has been made in recent years, imaging conditions in natural outdoor environments are still very challenging for current reconstruction and recognition methods. In this paper, we propose a novel unified approach which reasons jointly about 3D scene flow as well as the pose, shape and motion of vehicles in the scene. Towards this goal, we incorporate a deformable CAD model into a slanted-plane conditional random field for scene flow estimation and enforce shape consistency between the rendered 3D models and the parameters of all superpixels in the image. The association of superpixels to objects is established by an index variable which implicitly enables model selection. We evaluate our approach on the challenging KITTI scene flow dataset in terms of object and scene flow estimation. Our results provide a prove of concept and demonstrate the usefulness of our method.
Latex Bibtex Citation:
@inproceedings{Menze2015ISA,
author = {Moritz Menze and Christian Heipke and Andreas Geiger},
title = {Joint 3D Estimation of Vehicles and Scene Flow},
booktitle = {ISPRS Workshop on Image Sequence Analysis (ISA)},
year = {2015}
}
Latex Bibtex Citation:
@inproceedings{Menze2015ISA,
author = {Moritz Menze and Christian Heipke and Andreas Geiger},
title = {Joint 3D Estimation of Vehicles and Scene Flow},
booktitle = {ISPRS Workshop on Image Sequence Analysis (ISA)},
year = {2015}
}

Towards Probabilistic Volumetric Reconstruction using Ray Potentials (oral, best paper award)
A. Ulusoy, A. Geiger and M. Black
International Conference on 3D Vision (3DV), 2015
A. Ulusoy, A. Geiger and M. Black
International Conference on 3D Vision (3DV), 2015
Abstract: This paper presents a novel probabilistic foundation for volumetric 3-d reconstruction. We formulate the problem as inference in a Markov random field, which accurately captures the dependencies between the occupancy and appearance of each voxel, given all input images. Our main contribution is an approximate highly parallelized discrete-continuous inference algorithm to compute the marginal distributions of each voxel's occupancy and appearance. In contrast to the MAP solution, marginals encode the underlying uncertainty and ambiguity in the reconstruction. Moreover, the proposed algorithm allows for a Bayes optimal prediction with respect to a natural reconstruction loss. We compare our method to two state-of-the-art volumetric reconstruction algorithms on three challenging aerial datasets with LIDAR ground truth. Our experiments demonstrate that the proposed algorithm compares favorably in terms of reconstruction accuracy and the ability to expose reconstruction uncertainty.
Latex Bibtex Citation:
@inproceedings{Ulusoy2015THREEDV,
author = {Ali Osman Ulusoy and Andreas Geiger and Michael J. Black},
title = {Towards Probabilistic Volumetric Reconstruction using Ray Potentials},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2015}
}
Latex Bibtex Citation:
@inproceedings{Ulusoy2015THREEDV,
author = {Ali Osman Ulusoy and Andreas Geiger and Michael J. Black},
title = {Towards Probabilistic Volumetric Reconstruction using Ray Potentials},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2015}
}

Discrete Optimization for Optical Flow (oral)
M. Menze, C. Heipke and A. Geiger
German Conference on Pattern Recognition (GCPR), 2015
M. Menze, C. Heipke and A. Geiger
German Conference on Pattern Recognition (GCPR), 2015
Abstract: We propose to look at large-displacement optical flow from a discrete point of view. Motivated by the observation that sub-pixel accuracy is easily obtained given pixel-accurate optical flow, we conjecture that computing the integral part is the hardest piece of the problem. Consequently, we formulate optical flow estimation as a discrete inference problem in a conditional random field, followed by sub-pixel refinement. Naive discretization of the 2D flow space, however, is intractable due to the resulting size of the label set. In this paper, we therefore investigate three different strategies, each able to reduce computation and memory demands by several orders of magnitude. Their combination allows us to estimate large-displacement optical flow both accurately and efficiently and demonstrates the potential of discrete optimization for optical flow. We obtain state-of-the-art performance on MPI Sintel and KITTI.
Latex Bibtex Citation:
@inproceedings{Menze2015GCPR,
author = {Moritz Menze and Christian Heipke and Andreas Geiger},
title = {Discrete Optimization for Optical Flow},
booktitle = {German Conference on Pattern Recognition (GCPR)},
year = {2015}
}
Latex Bibtex Citation:
@inproceedings{Menze2015GCPR,
author = {Moritz Menze and Christian Heipke and Andreas Geiger},
title = {Discrete Optimization for Optical Flow},
booktitle = {German Conference on Pattern Recognition (GCPR)},
year = {2015}
}

Joint 3D Object and Layout Inference from a single RGB-D Image (oral, best paper award)
A. Geiger and C. Wang
German Conference on Pattern Recognition (GCPR), 2015
A. Geiger and C. Wang
German Conference on Pattern Recognition (GCPR), 2015
Abstract: Inferring 3D objects and the layout of indoor scenes from a single RGB-D image captured with a Kinect camera is a challenging task. Towards this goal, we propose a high-order graphical model and jointly reason about the layout, objects and superpixels in the image. In contrast to existing holistic approaches, our model leverages detailed 3D geometry using inverse graphics and explicitly enforces occlusion and visibility constraints for respecting scene properties and projective geometry. We cast the task as MAP inference in a factor graph and solve it efficiently using message passing. We evaluate our method with respect to several baselines on the challenging NYUv2 indoor dataset using 21 object categories. Our experiments demonstrate that the proposed method is able to infer scenes with a large degree of clutter and occlusions.
Latex Bibtex Citation:
@inproceedings{Geiger2015GCPR,
author = {Andreas Geiger and Chaohui Wang},
title = {Joint 3D Object and Layout Inference from a single RGB-D Image},
booktitle = {German Conference on Pattern Recognition (GCPR)},
year = {2015}
}
Latex Bibtex Citation:
@inproceedings{Geiger2015GCPR,
author = {Andreas Geiger and Chaohui Wang},
title = {Joint 3D Object and Layout Inference from a single RGB-D Image},
booktitle = {German Conference on Pattern Recognition (GCPR)},
year = {2015}
}

Object Scene Flow for Autonomous Vehicles
M. Menze and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2015
M. Menze and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2015
Abstract: This paper proposes a novel model and dataset for 3D scene flow estimation with an application to autonomous driving. Taking advantage of the fact that outdoor scenes often decompose into a small number of independently moving objects, we represent each element in the scene by its rigid motion parameters and each superpixel by a 3D plane as well as an index to the corresponding object. This minimal representation increases robustness and leads to a discrete-continuous CRF where the data term decomposes into pairwise potentials between superpixels and objects. Moreover, our model intrinsically segments the scene into its constituting dynamic components. We demonstrate the performance of our model on existing benchmarks as well as a novel realistic dataset with scene flow ground truth. We obtain this dataset by annotating 400 dynamic scenes from the KITTI raw data collection using detailed 3D CAD models for all vehicles in motion. Our experiments also reveal novel challenges which can't be handled by existing methods.
Latex Bibtex Citation:
@inproceedings{Menze2015CVPR,
author = {Moritz Menze and Andreas Geiger},
title = {Object Scene Flow for Autonomous Vehicles},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2015}
}
Latex Bibtex Citation:
@inproceedings{Menze2015CVPR,
author = {Moritz Menze and Andreas Geiger},
title = {Object Scene Flow for Autonomous Vehicles},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2015}
}

Displets: Resolving Stereo Ambiguities using Object Knowledge
F. Güney and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2015
F. Güney and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2015
Abstract: Stereo techniques have witnessed tremendous progress over the last decades, yet some aspects of the problem still remain challenging today. Striking examples are reflecting and textureless surfaces which cannot easily be recovered using traditional local regularizers. In this paper, we therefore propose to regularize over larger distances using object-category specific disparity proposals (displets) which we sample using inverse graphics techniques based on a sparse disparity estimate and a semantic segmentation of the image. The proposed displets encode the fact that objects of certain categories are not arbitrarily shaped but typically exhibit regular structures. We integrate them as non-local regularizer for the challenging object class 'car' into a superpixel based CRF framework and demonstrate its benefits on the KITTI stereo evaluation.
Latex Bibtex Citation:
@inproceedings{Guney2015CVPR,
author = {Fatma Güney and Andreas Geiger},
title = {Displets: Resolving Stereo Ambiguities using Object Knowledge},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2015}
}
Latex Bibtex Citation:
@inproceedings{Guney2015CVPR,
author = {Fatma Güney and Andreas Geiger},
title = {Displets: Resolving Stereo Ambiguities using Object Knowledge},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2015}
}

Handbook of Driver Assistance Systems
. WinnerandH., . HakuliandS., . LotzandF., . SingerandC., . GeigerandAndreas et al.
Springer Vieweg, 2015
. WinnerandH., . HakuliandS., . LotzandF., . SingerandC., . GeigerandAndreas et al.
Springer Vieweg, 2015
Abstract: This fundamental work explains in detail systems for active safety and driver assistance, considering both their structure and their function. These include the well-known standard systems such as Anti-lock braking system (ABS), Electronic Stability Control (ESC) or Adaptive Cruise Control (ACC). But it includes also new systems for protecting collisions protection, for changing the lane, or for convenient parking. The book aims at giving a complete picture focusing on the entire system. First, it describes the components which are necessary for assistance systems, such as sensors, actuators, mechatronic subsystems, and control elements. Then, it explains key features for the user-friendly design of human-machine interfaces between driver and assistance system. Finally, important characteristic features of driver assistance systems for particular vehicles are presented: Systems for commercial vehicles and motorcycles.
Latex Bibtex Citation:
@book{Winner2015eng,
author = { WinnerandH. and HakuliandS. and LotzandF. and SingerandC. and GeigerandAndreas and others},
title = {Handbook of Driver Assistance Systems},
publisher = {Springer Vieweg},
year = {2015}
}
Latex Bibtex Citation:
@book{Winner2015eng,
author = { WinnerandH. and HakuliandS. and LotzandF. and SingerandC. and GeigerandAndreas and others},
title = {Handbook of Driver Assistance Systems},
publisher = {Springer Vieweg},
year = {2015}
}

Handbuch Fahrerassistenzsysteme
. WinnerandH., . HakuliandS., . LotzandF., . SingerandC., . GeigerandAndreas et al.
Springer Vieweg, 2015
. WinnerandH., . HakuliandS., . LotzandF., . SingerandC., . GeigerandAndreas et al.
Springer Vieweg, 2015
Abstract: In diesem Grundlagenwerk werden Fahrerassistenzsysteme für aktive Sicherheit und Fahrerentlastung in Aufbau und Funktion ausführlich erklärt. Darüber hinaus enthält es eine Übersicht der Rahmenbedingungen für die Fahrerassistenzentwicklung sowie Erläuterungen der angewandten Entwicklungs- und Testwerkzeuge. Die Beschreibung umfasst die heute bekannten Assistenzsysteme für die Fahrzeugstabilisierung (z. B. ABS und ESC), die Bahnführung (z. B. ACC, Einparkassistenz) und die Navigation sowie einen Ausblick auf die zukünftigen Entwicklungen, insbesondere der zunehmenden Automatisierung des Fahrens. Die Darstellung bezieht Funktionsprinzipien und Ausführungsformen der dazu erforderlichen Komponenten wie Sensoren, Aktoren, mechatronische Subsysteme und Betätigungselemente ein. Außerdem werden Konzepte der Datenfusion und Umfeldrepräsentation sowie der nutzergerechten Gestaltung der Mensch-Maschine-Schnittstelle zwischen Assistenzsystem und Fahrer vorgestellt. Kapitel über die Besonderheiten von Fahrerassistenzsystemen bei Nutzfahrzeugen und Motorrädern runden den umfassenden Ansatz ab.
Latex Bibtex Citation:
@book{Winner2015,
author = { WinnerandH. and HakuliandS. and LotzandF. and SingerandC. and GeigerandAndreas and others},
title = {Handbuch Fahrerassistenzsysteme},
publisher = {Springer Vieweg},
year = {2015}
}
Latex Bibtex Citation:
@book{Winner2015,
author = { WinnerandH. and HakuliandS. and LotzandF. and SingerandC. and GeigerandAndreas and others},
title = {Handbuch Fahrerassistenzsysteme},
publisher = {Springer Vieweg},
year = {2015}
}
2014

3D Traffic Scene Understanding from Movable Platforms
A. Geiger, M. Lauer, C. Wojek, C. Stiller and R. Urtasun
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2014
A. Geiger, M. Lauer, C. Wojek, C. Stiller and R. Urtasun
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2014
Abstract: In this paper, we present a novel probabilistic generative model for multi-object traffic scene understanding from movable platforms which reasons jointly about the 3D scene layout as well as the location and orientation of objects in the scene. In particular, the scene topology, geometry and traffic activities are inferred from short video sequences. Inspired by the impressive driving capabilities of humans, our model does not rely on GPS, lidar or map knowledge. Instead, it takes advantage of a diverse set of visual cues in the form of vehicle tracklets, vanishing points, semantic scene labels, scene flow and occupancy grids. For each of these cues we propose likelihood functions that are integrated into a probabilistic generative model. We learn all model parameters from training data using contrastive divergence. Experiments conducted on videos of 113 representative intersections show that our approach successfully infers the correct layout in a variety of very challenging scenarios. To evaluate the importance of each feature cue, experiments using different feature combinations are conducted. Furthermore, we show how by employing context derived from the proposed method we are able to improve over the state-of-the-art in terms of object detection and object orientation estimation in challenging and cluttered urban environments.
Latex Bibtex Citation:
@article{Geiger2014PAMI,
author = {Andreas Geiger and Martin Lauer and Christian Wojek and Christoph Stiller and Raquel Urtasun},
title = {3D Traffic Scene Understanding from Movable Platforms},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2014}
}
Latex Bibtex Citation:
@article{Geiger2014PAMI,
author = {Andreas Geiger and Martin Lauer and Christian Wojek and Christoph Stiller and Raquel Urtasun},
title = {3D Traffic Scene Understanding from Movable Platforms},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2014}
}

Simultaneous Underwater Visibility Assessment, Enhancement and Improved Stereo
M. Roser, M. Dunbabin and A. Geiger
International Conference on Robotics and Automation (ICRA), 2014
M. Roser, M. Dunbabin and A. Geiger
International Conference on Robotics and Automation (ICRA), 2014
Abstract: Vision-based underwater navigation and obstacle avoidance demands robust computer vision algorithms, particularly for operation in turbid water with reduced visibility. This paper describes a novel method for the simultaneous underwater image quality assessment, visibility enhancement and disparity computation to increase stereo range resolution under dynamic, natural lighting and turbid conditions. The technique estimates the visibility properties from a sparse 3D map of the original degraded image using a physical underwater light attenuation model. Firstly, an iterated distance-adaptive image contrast enhancement enables a dense disparity computation and visibility estimation. Secondly, using a light attenuation model for ocean water, a color corrected stereo underwater image is obtained along with a visibility distance estimate. Experimental results in shallow, naturally lit, high-turbidity coastal environments show the proposed technique improves range estimation over the original images as well as image quality and color for habitat classification. Furthermore, the recursiveness and robustness of the technique allows real-time implementation onboard an Autonomous Underwater Vehicles for improved navigation and obstacle avoidance performance.
Latex Bibtex Citation:
@inproceedings{Roser2014ICRA,
author = {Martin Roser and Matthew Dunbabin and Andreas Geiger},
title = {Simultaneous Underwater Visibility Assessment, Enhancement and Improved Stereo},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2014}
}
Latex Bibtex Citation:
@inproceedings{Roser2014ICRA,
author = {Martin Roser and Matthew Dunbabin and Andreas Geiger},
title = {Simultaneous Underwater Visibility Assessment, Enhancement and Improved Stereo},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2014}
}

Calibrating and Centering Quasi-Central Catadioptric Cameras
M. Schönbein, T. Strauss and A. Geiger
International Conference on Robotics and Automation (ICRA), 2014
M. Schönbein, T. Strauss and A. Geiger
International Conference on Robotics and Automation (ICRA), 2014
Abstract: Non-central catadioptric models are able to cope with irregular camera setups and inaccuracies in the manufacturing process but are computationally demanding and thus not suitable for robotic applications. On the other hand, calibrating a quasi-central (almost central) system with a central model introduces errors due to a wrong relationship between the viewing ray orientations and the pixels on the image sensor. In this paper, we propose a central approximation to quasi-central catadioptric camera systems that is both accurate and efficient. We observe that the distance to points in 3D is typically large compared to deviations from the single viewpoint. Thus, we first calibrate the system using a state-of-the-art non-central camera model. Next, we show that by remapping the observations we are able to match the orientation of the viewing rays of a much simpler single viewpoint model with the true ray orientations. While our approximation is general and applicable to all quasi-central camera systems, we focus on one of the most common cases in practice: hypercatadioptric cameras. We compare our model to a variety of baselines in synthetic and real localization and motion estimation experiments. We show that by using the proposed model we are able to achieve near non-central accuracy while obtaining speed-ups of more than three orders of magnitude compared to state-of-the-art non-central models.
Latex Bibtex Citation:
@inproceedings{Schoenbein2014ICRA,
author = {Miriam Schönbein and Tobias Strauss and Andreas Geiger},
title = {Calibrating and Centering Quasi-Central Catadioptric Cameras},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2014}
}
Latex Bibtex Citation:
@inproceedings{Schoenbein2014ICRA,
author = {Miriam Schönbein and Tobias Strauss and Andreas Geiger},
title = {Calibrating and Centering Quasi-Central Catadioptric Cameras},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2014}
}

Omnidirectional 3D Reconstruction in Augmented Manhattan Worlds
M. Schönbein and A. Geiger
International Conference on Intelligent Robots and Systems (IROS), 2014
M. Schönbein and A. Geiger
International Conference on Intelligent Robots and Systems (IROS), 2014
Abstract: This paper proposes a method for high-quality omnidirectional 3D reconstruction of augmented Manhattan worlds from catadioptric stereo video sequences. In contrast to existing works we do not rely on constructing virtual perspective views, but instead propose to optimize depth jointly in a unified omnidirectional space. Furthermore, we show that plane-based prior models can be applied even though planes in 3D do not project to planes in the omnidirectional domain. Towards this goal, we propose an omnidirectional slanted-plane Markov random field model which relies on plane hypotheses extracted using a novel voting scheme for 3D planes in omnidirectional space. To quantitatively evaluate our method we introduce a dataset which we have captured using our autonomous driving platform AnnieWAY which we equipped with two horizontally aligned catadioptric cameras and a Velodyne HDL-64E laser scanner for precise ground truth depth measurements. As evidenced by our experiments, the proposed method clearly benefits from the unified view and significantly outperforms existing stereo matching techniques both quantitatively and qualitatively. Furthermore, our method is able to reduce noise and the obtained depth maps can be represented very compactly by a small number of image segments and plane parameters.
Latex Bibtex Citation:
@inproceedings{Schoenbein2014IROS,
author = {Miriam Schönbein and Andreas Geiger},
title = {Omnidirectional 3D Reconstruction in Augmented Manhattan Worlds},
booktitle = {International Conference on Intelligent Robots and Systems (IROS)},
year = {2014}
}
Latex Bibtex Citation:
@inproceedings{Schoenbein2014IROS,
author = {Miriam Schönbein and Andreas Geiger},
title = {Omnidirectional 3D Reconstruction in Augmented Manhattan Worlds},
booktitle = {International Conference on Intelligent Robots and Systems (IROS)},
year = {2014}
}
2013

Understanding High-Level Semantics by Modeling Traffic Patterns
H. Zhang, A. Geiger and R. Urtasun
International Conference on Computer Vision (ICCV), 2013
H. Zhang, A. Geiger and R. Urtasun
International Conference on Computer Vision (ICCV), 2013
Abstract: In this paper, we are interested in understanding the semantics of outdoor scenes in the context of autonomous driving. Towards this goal, we propose a generative model of 3D urban scenes which is able to reason not only about the geometry and objects present in the scene, but also about the high-level semantics in the form of traffic patterns. We found that a small number of patterns is sufficient to model the vast majority of traffic scenes and show how these patterns can be learned. As evidenced by our experiments, this high-level reasoning significantly improves the overall scene estimation as well as the vehicle-to-lane association when compared to state-of-the-art approaches. All data and code will be made available upon publication.
Latex Bibtex Citation:
@inproceedings{Zhang2013ICCV,
author = {Hongyi Zhang and Andreas Geiger and Raquel Urtasun},
title = {Understanding High-Level Semantics by Modeling Traffic Patterns},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2013}
}
Latex Bibtex Citation:
@inproceedings{Zhang2013ICCV,
author = {Hongyi Zhang and Andreas Geiger and Raquel Urtasun},
title = {Understanding High-Level Semantics by Modeling Traffic Patterns},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2013}
}

Vision meets Robotics: The KITTI Dataset
A. Geiger, P. Lenz, C. Stiller and R. Urtasun
International Journal of Robotics Research (IJRR), 2013
A. Geiger, P. Lenz, C. Stiller and R. Urtasun
International Journal of Robotics Research (IJRR), 2013
Abstract: We present a novel dataset captured from a VW station wagon for use in mobile robotics and autonomous driving research. In total, we recorded 6 hours of traffic scenarios at 10-100 Hz using a variety of sensor modalities such as high-resolution color and grayscale stereo cameras, a Velodyne 3D laser scanner and a high-precision GPS/IMU inertial navigation system. The scenarios are diverse, capturing real-world traffic situations and range from freeways over rural areas to inner-city scenes with many static and dynamic objects. Our data is calibrated, synchronized and timestamped, and we provide the rectified and raw image sequences. Our dataset also contains object labels in the form of 3D tracklets and we provide online benchmarks for stereo, optical flow, object detection and other tasks. This paper describes our recording platform, the data format and the utilities that we provide.
Latex Bibtex Citation:
@article{Geiger2013IJRR,
author = {Andreas Geiger and Philip Lenz and Christoph Stiller and Raquel Urtasun},
title = {Vision meets Robotics: The KITTI Dataset},
journal = {International Journal of Robotics Research (IJRR)},
year = {2013}
}
Latex Bibtex Citation:
@article{Geiger2013IJRR,
author = {Andreas Geiger and Philip Lenz and Christoph Stiller and Raquel Urtasun},
title = {Vision meets Robotics: The KITTI Dataset},
journal = {International Journal of Robotics Research (IJRR)},
year = {2013}
}

Probabilistic Models for 3D Urban Scene Understanding from Movable Platforms
A. Geiger
Ph.D. Thesis, 2013
A. Geiger
Ph.D. Thesis, 2013
Abstract: Visual 3D scene understanding is an important component in autonomous driving and robot navigation. Intelligent vehicles for example often base their decisions on observations obtained from video cameras as they are cheap and easy to employ. Inner-city intersections represent an interesting but also very challenging scenario in this context: The road layout may be very complex and observations are often noisy or even missing due to heavy occlusions. While Highway navigation and autonomous driving on simple and annotated intersections have already been demonstrated successfully, understanding and navigating general inner-city crossings with little prior knowledge remains an unsolved problem. This thesis is a contribution to understanding multi-object traffic scenes from video sequences. All data is provided by a camera system which is mounted on top of the autonomous driving platform AnnieWAY. The proposed probabilistic generative model reasons jointly about the 3D scene layout as well as the 3D location and orientation of objects in the scene. In particular, the scene topology, geometry as well as traffic activities are inferred from short video sequences. The model takes advantage of monocular information in the form of vehicle tracklets, vanishing lines and semantic labels. Additionally, the benefit of stereo features such as 3D scene flow and occupancy grids is investigated. Motivated by the impressive driving capabilities of humans, no further information such as GPS, lidar, radar or map knowledge is required. Experiments conducted on 113 representative intersection sequences show that the developed approach successfully infers the correct layout in a variety of difficult scenarios. To evaluate the importance of each feature cue, experiments with different feature combinations are conducted. Additionally, the proposed method is shown to improve object detection and object orientation estimation performance.
Latex Bibtex Citation:
@phdthesis{Geiger2013,
author = {Andreas Geiger},
title = {Probabilistic Models for 3D Urban Scene Understanding from Movable Platforms},
school = {KIT},
year = {2013}
}
Latex Bibtex Citation:
@phdthesis{Geiger2013,
author = {Andreas Geiger},
title = {Probabilistic Models for 3D Urban Scene Understanding from Movable Platforms},
school = {KIT},
year = {2013}
}

Lost! Leveraging the Crowd for Probabilistic Visual Self-Localization (oral, best paper runner up award)
M. Brubaker, A. Geiger and R. Urtasun
Conference on Computer Vision and Pattern Recognition (CVPR), 2013
M. Brubaker, A. Geiger and R. Urtasun
Conference on Computer Vision and Pattern Recognition (CVPR), 2013
Abstract: In this paper we propose an affordable solution to self-localization, which utilizes visual odometry and road maps as the only inputs. To this end, we present a probabilistic model as well as an efficient approximate inference algorithm, which is able to utilize distributed computation to meet the real-time requirements of autonomous systems. Because of the probabilistic nature of the model we are able to cope with uncertainty due to noisy visual odometry and inherent ambiguities in the map (e.g., in a Manhattan world). By exploiting freely available, community developed maps and visual odometry measurements, we are able to localize a vehicle up to 3m after only a few seconds of driving on maps which contain more than 2,150km of drivable roads.
Latex Bibtex Citation:
@inproceedings{Brubaker2013CVPR,
author = {Marcus A. Brubaker and Andreas Geiger and Raquel Urtasun},
title = {Lost! Leveraging the Crowd for Probabilistic Visual Self-Localization},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2013}
}
Latex Bibtex Citation:
@inproceedings{Brubaker2013CVPR,
author = {Marcus A. Brubaker and Andreas Geiger and Raquel Urtasun},
title = {Lost! Leveraging the Crowd for Probabilistic Visual Self-Localization},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2013}
}

A New Performance Measure and Evaluation Benchmark for Road Detection Algorithms
J. Fritsch, T. Kuehnl and A. Geiger
International Conference on Intelligent Transportation Systems (ITSC), 2013
J. Fritsch, T. Kuehnl and A. Geiger
International Conference on Intelligent Transportation Systems (ITSC), 2013
Abstract: Detecting the road area and ego-lane ahead of a vehicle is central to modern driver assistance systems. While lane-detection on well-marked roads is already available in modern vehicles, finding the boundaries of unmarked or weakly marked roads and lanes as they appear in inner-city and rural environments remains an unsolved problem due to the high variability in scene layout and illumination conditions, amongst others. While recent years have witnessed great interest in this subject, to date no commonly agreed upon benchmark exists, rendering a fair comparison amongst methods difficult. In this paper, we introduce a novel open-access dataset and benchmark for road area and egolane detection. Our dataset comprises 600 annotated training and test images of high variability from the KITTI autonomous driving project, capturing a broad spectrum of urban road scenes. For evaluation, we propose to use the 2D Bird's Eye View (BEV) space as vehicle control usually happens in this 2D world, requiring detection results to be represented in this very same space. Furthermore, we propose a novel, behavior-based metric which judges the utility of the extracted egolane area for driver assistance applications by fitting a corridor to the road detection results in the BEV. We believe this to be important for a meaningful evaluation as pixel-level performance is of limited value for vehicle control. State-of-the-art road detection algorithms are used to demonstrate results using classical pixel-level metrics in perspective and BEV space as well as the novel behavior-based performance measure. All data and annotations are made publicly available on the KITTI online evaluation website in order to serve as a common benchmark for road terrain detection algorithms.
Latex Bibtex Citation:
@inproceedings{Fritsch2013ITSC,
author = {Jannik Fritsch and Tobias Kuehnl and Andreas Geiger},
title = {A New Performance Measure and Evaluation Benchmark for Road Detection Algorithms},
booktitle = {International Conference on Intelligent Transportation Systems (ITSC)},
year = {2013}
}
Latex Bibtex Citation:
@inproceedings{Fritsch2013ITSC,
author = {Jannik Fritsch and Tobias Kuehnl and Andreas Geiger},
title = {A New Performance Measure and Evaluation Benchmark for Road Detection Algorithms},
booktitle = {International Conference on Intelligent Transportation Systems (ITSC)},
year = {2013}
}
2012

Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite (oral)
A. Geiger, P. Lenz and R. Urtasun
Conference on Computer Vision and Pattern Recognition (CVPR), 2012
A. Geiger, P. Lenz and R. Urtasun
Conference on Computer Vision and Pattern Recognition (CVPR), 2012
Abstract: Today, visual recognition systems are still rarely employed in robotics applications. Perhaps one of the main reasons for this is the lack of demanding benchmarks that mimic such scenarios. In this paper, we take advantage of our autonomous driving platform to develop novel challenging benchmarks for the tasks of stereo, optical flow, visual odometry / SLAM and 3D object detection. Our recording platform is equipped with four high resolution video cameras, a Velodyne laser scanner and a state-of-the-art localization system. Our benchmarks comprise 389 stereo and optical flow image pairs, stereo visual odometry sequences of 39.2 km length, and more than 200k 3D object annotations captured in cluttered scenarios (up to 15 cars and 30 pedestrians are visible per image). Results from state-of-the-art algorithms reveal that methods ranking high on established datasets such as Middlebury perform below average when being moved outside the laboratory to the real world. Our goal is to reduce this bias by providing challenging benchmarks with novel difficulties to the computer vision community.
Latex Bibtex Citation:
@inproceedings{Geiger2012CVPR,
author = {Andreas Geiger and Philip Lenz and Raquel Urtasun},
title = {Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2012}
}
Latex Bibtex Citation:
@inproceedings{Geiger2012CVPR,
author = {Andreas Geiger and Philip Lenz and Raquel Urtasun},
title = {Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2012}
}

Automatic Calibration of Range and Camera Sensors using a single Shot (oral)
A. Geiger, F. Moosmann, O. Car and B. Schuster
International Conference on Robotics and Automation (ICRA), 2012
A. Geiger, F. Moosmann, O. Car and B. Schuster
International Conference on Robotics and Automation (ICRA), 2012
Abstract: As a core robotic and vision problem, camera and range sensor calibration have been researched intensely over the last decades. However, robotic research efforts still often get heavily delayed by the requirement of setting up a calibrated system consisting of multiple cameras and range measurement units. With regard to removing this burden, we present an online toolbox for fully automatic camera-to-camera and camera-to-range calibration. Our system is easy to setup and recovers intrinsic and extrinsic camera parameters as well as the transformation between cameras and range sensors within less than one minute. In contrast to existing calibration approaches, which often require user intervention, the proposed method is robust to varying imaging conditions, fully automatic, and easy to use since a single image and range scan proves sufficient for most calibration scenarios. Experiments using a variety of sensors such as greyscale and color cameras, the Kinect 3D sensor and the Velodyne HDL-64 laser scanner show the robustness of our method in different indoor and outdoor settings and under various lighting conditions.
Latex Bibtex Citation:
@inproceedings{Geiger2012ICRA,
author = {Andreas Geiger and Frank Moosmann and Oemer Car and Bernhard Schuster},
title = {Automatic Calibration of Range and Camera Sensors using a single Shot},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2012}
}
Latex Bibtex Citation:
@inproceedings{Geiger2012ICRA,
author = {Andreas Geiger and Frank Moosmann and Oemer Car and Bernhard Schuster},
title = {Automatic Calibration of Range and Camera Sensors using a single Shot},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2012}
}

Motion-without-Structure: Real-time Multipose Optimization for Accurate Visual Odometry
H. Lategahn, A. Geiger, B. Kitt and C. Stiller
Intelligent Vehicles Symposium (IV), 2012
H. Lategahn, A. Geiger, B. Kitt and C. Stiller
Intelligent Vehicles Symposium (IV), 2012
Abstract: State of the art visual odometry systems use bundle adjustment (BA) like methods to jointly optimize motion and scene structure. Fusing measurements from multiple time steps and optimizing an error criterion in a batch fashion seems to deliver the most accurate results. However, often the scene structure is of no interest and is a mere auxiliary quantity although it contributes heavily to the complexity of the problem. Herein we propose to use a recently developed incremental motion estimator which delivers relative pose displacements between each two frames within a sliding window inducing a pose graph. Moreover, we introduce a method to learn the uncertainty associated with each of the pose displacements. The pose graph is adjusted by non-linear least squares optimization while incorporating a motion model. Thereby we fuse measurements from multiple time steps much in the same sense as BA does. However, we obviate the need to estimate the scene structure yielding a very efficient estimator: Solving the nonlinear least squares problem by a Gauss-Newton method takes approximately 1ms. We show the effectiveness of our method on simulated and real world data and demonstrate substantial improvements over incremental methods.
Latex Bibtex Citation:
@inproceedings{Lategahn2012IV,
author = {Henning Lategahn and Andreas Geiger and Bernd Kitt and Christoph Stiller},
title = {Motion-without-Structure: Real-time Multipose Optimization for Accurate Visual Odometry},
booktitle = {Intelligent Vehicles Symposium (IV)},
year = {2012}
}
Latex Bibtex Citation:
@inproceedings{Lategahn2012IV,
author = {Henning Lategahn and Andreas Geiger and Bernd Kitt and Christoph Stiller},
title = {Motion-without-Structure: Real-time Multipose Optimization for Accurate Visual Odometry},
booktitle = {Intelligent Vehicles Symposium (IV)},
year = {2012}
}

Team AnnieWAY's entry to the Grand Cooperative Driving Challenge 2011
A. Geiger, M. Lauer, F. Moosmann, B. Ranft, H. Rapp, C. Stiller and J. Ziegler
Transactions on Intelligent Transportation Systems (TITS), 2012
A. Geiger, M. Lauer, F. Moosmann, B. Ranft, H. Rapp, C. Stiller and J. Ziegler
Transactions on Intelligent Transportation Systems (TITS), 2012
Abstract: In this paper we present the concepts and methods developed for the autonomous vehicle AnnieWAY, our winning entry to the Grand Cooperative Driving Challenge of 2011. We describe algorithms for sensor fusion, vehicle-to-vehicle communication and cooperative control. Furthermore, we analyze the performance of the proposed methods and compare them to those of competing teams. We close with our results from the competition and lessons learned.
Latex Bibtex Citation:
@article{Geiger2012TITS,
author = {Andreas Geiger and Martin Lauer and Frank Moosmann and Benjamin Ranft and Holger Rapp and Christoph Stiller and Julius Ziegler},
title = {Team AnnieWAY's entry to the Grand Cooperative Driving Challenge 2011},
journal = {Transactions on Intelligent Transportation Systems (TITS)},
year = {2012}
}
Latex Bibtex Citation:
@article{Geiger2012TITS,
author = {Andreas Geiger and Martin Lauer and Frank Moosmann and Benjamin Ranft and Holger Rapp and Christoph Stiller and Julius Ziegler},
title = {Team AnnieWAY's entry to the Grand Cooperative Driving Challenge 2011},
journal = {Transactions on Intelligent Transportation Systems (TITS)},
year = {2012}
}
2011

A Generative Model for 3D Urban Scene Understanding from Movable Platforms (oral)
. GeigerandAndreas, . LauerandMartin and . UrtasunandRaquel
Conference on Computer Vision and Pattern Recognition (CVPR), 2011
. GeigerandAndreas, . LauerandMartin and . UrtasunandRaquel
Conference on Computer Vision and Pattern Recognition (CVPR), 2011
Abstract: 3D scene understanding is key for the success of applications such as autonomous driving and robot navigation. However, existing approaches either produce a mild level of understanding, e.g., segmentation, object detection, or are not accurate enough for these applications, e.g., 3D pop-ups. In this paper we propose a principled generative model of 3D urban scenes that takes into account dependencies between static and dynamic features. We derive a reversible jump MCMC scheme that is able to infer the geometric (e.g., street orientation) and topological (e.g., number of intersecting streets) properties of the scene layout, as well as the semantic activities occurring in the scene, e.g., traffic situations at an intersection. Furthermore, we show that this global level of understanding provides the context necessary to disambiguate current state-of-the-art detectors. We demonstrate the effectiveness of our approach on a dataset composed of short stereo video sequences of 113 different scenes captured by a car driving around a mid-size city.
Latex Bibtex Citation:
@inproceedings{Geiger2011CVPR,
author = { GeigerandAndreas and LauerandMartin and UrtasunandRaquel},
title = {A Generative Model for 3D Urban Scene Understanding from Movable Platforms},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2011}
}
Latex Bibtex Citation:
@inproceedings{Geiger2011CVPR,
author = { GeigerandAndreas and LauerandMartin and UrtasunandRaquel},
title = {A Generative Model for 3D Urban Scene Understanding from Movable Platforms},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2011}
}

Visual SLAM for Autonomous Ground Vehicles
H. Lategahn, A. Geiger and B. Kitt
International Conference on Robotics and Automation (ICRA), 2011
H. Lategahn, A. Geiger and B. Kitt
International Conference on Robotics and Automation (ICRA), 2011
Abstract: In this paper we propose a dense stereo V-SLAM algorithm that estimates a dense 3D map representation which is more accurate than raw stereo measurements. Thereto, we run a sparse VSLAM system, take the resulting pose estimates to compute a locally dense representation from dense stereo correspondences. This dense representation is expressed in local coordinate systems which are tracked as part of the SLAM estimate. This allows the dense part to be continuously updated. Our system is driven by visual odometry priors to achieve high robustness when tracking landmarks. Moreover, the sparse part of the SLAM system uses recently published submapping techniques to achieve constant runtime complexity most of the time. The improved accuracy over raw stereo measurements is shown in a Monte Carlo simulation. Finally, we demonstrate the feasibility of our method by presenting outdoor experiments of a car like robot.
Latex Bibtex Citation:
@inproceedings{Lategahn2011ICRA,
author = {Henning Lategahn and Andreas Geiger and Bernd Kitt},
title = {Visual SLAM for Autonomous Ground Vehicles},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2011}
}
Latex Bibtex Citation:
@inproceedings{Lategahn2011ICRA,
author = {Henning Lategahn and Andreas Geiger and Bernd Kitt},
title = {Visual SLAM for Autonomous Ground Vehicles},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2011}
}

Sparse Scene Flow Segmentation for Moving Object Detection in Urban Environments
P. Lenz, J. Ziegler, A. Geiger and M. Roser
Intelligent Vehicles Symposium (IV), 2011
P. Lenz, J. Ziegler, A. Geiger and M. Roser
Intelligent Vehicles Symposium (IV), 2011
Abstract: This paper presents an approach for object detection utilizing sparse scene flow. For consecutive stereo images taken from a moving vehicle, corresponding interest points are extracted. Thus, for every interest point, disparity and optical flow values are known and consequently, scene flow can be calculated. Adjacent interest points describing similar scene flow are considered to belong to one rigid object. The proposed method does not rely on object classes and allows for a robust detection of dynamic objects in traffic scenes. Leading vehicles are continuously detected for several frames. Oncoming objects are detected within five frames after their appearance.
Latex Bibtex Citation:
@inproceedings{Lenz2011IV,
author = {Philip Lenz and Julius Ziegler and Andreas Geiger and Martin Roser},
title = {Sparse Scene Flow Segmentation for Moving Object Detection in Urban Environments},
booktitle = {Intelligent Vehicles Symposium (IV)},
year = {2011}
}
Latex Bibtex Citation:
@inproceedings{Lenz2011IV,
author = {Philip Lenz and Julius Ziegler and Andreas Geiger and Martin Roser},
title = {Sparse Scene Flow Segmentation for Moving Object Detection in Urban Environments},
booktitle = {Intelligent Vehicles Symposium (IV)},
year = {2011}
}

StereoScan: Dense 3D Reconstruction in Real-time (oral)
A. Geiger, J. Ziegler and C. Stiller
Intelligent Vehicles Symposium (IV), 2011
A. Geiger, J. Ziegler and C. Stiller
Intelligent Vehicles Symposium (IV), 2011
Abstract: This paper proposes a novel approach to build 3d maps from high-resolution stereo sequences in real-time. Inspired by recent progress in stereo matching, we propose a sparse feature matcher in conjunction with an efficient and robust visual odometry algorithm. Our reconstruction pipeline combines both techniques with efficient stereo matching and a multi-view linking scheme for generating consistent 3d point clouds. In our experiments we show that the proposed odometry method achieves state-of-the-art accuracy. Including feature matching, the visual odometry part of our algorithm runs at 25 frames per second, while - at the same time - we obtain new depth maps at 3-4 fps, sufficient for online 3d reconstructions.
Latex Bibtex Citation:
@inproceedings{Geiger2011IV,
author = {Andreas Geiger and Julius Ziegler and Christoph Stiller},
title = {StereoScan: Dense 3D Reconstruction in Real-time},
booktitle = {Intelligent Vehicles Symposium (IV)},
year = {2011}
}
Latex Bibtex Citation:
@inproceedings{Geiger2011IV,
author = {Andreas Geiger and Julius Ziegler and Christoph Stiller},
title = {StereoScan: Dense 3D Reconstruction in Real-time},
booktitle = {Intelligent Vehicles Symposium (IV)},
year = {2011}
}

Joint 3D Estimation of Objects and Scene Layout
A. Geiger, C. Wojek and R. Urtasun
Advances in Neural Information Processing Systems (NIPS), 2011
A. Geiger, C. Wojek and R. Urtasun
Advances in Neural Information Processing Systems (NIPS), 2011
Abstract: We propose a novel generative model that is able to reason jointly about the 3D scene layout as well as the 3D location and orientation of objects in the scene. In particular, we infer the scene topology, geometry as well as traffic activities from a short video sequence acquired with a single camera mounted on a moving car. Our generative model takes advantage of dynamic information in the form of vehicle tracklets as well as static information coming from semantic labels and geometry (i.e., vanishing points). Experiments show that our approach outperforms a discriminative baseline based on multiple kernel learning (MKL) which has access to the same image information. Furthermore, as we reason about objects in 3D, we are able to significantly increase the performance of state-of-the-art object detectors in their ability to estimate object orientation.
Latex Bibtex Citation:
@inproceedings{Geiger2011NIPS,
author = {Andreas Geiger and Christian Wojek and Raquel Urtasun},
title = {Joint 3D Estimation of Objects and Scene Layout},
booktitle = {Advances in Neural Information Processing Systems (NIPS)},
year = {2011}
}
Latex Bibtex Citation:
@inproceedings{Geiger2011NIPS,
author = {Andreas Geiger and Christian Wojek and Raquel Urtasun},
title = {Joint 3D Estimation of Objects and Scene Layout},
booktitle = {Advances in Neural Information Processing Systems (NIPS)},
year = {2011}
}
2010

Efficient Large-Scale Stereo Matching (oral)
. GeigerandAndreas, . RoserandMartin and . UrtasunandRaquel
Asian Conference on Computer Vision (ACCV), 2010
. GeigerandAndreas, . RoserandMartin and . UrtasunandRaquel
Asian Conference on Computer Vision (ACCV), 2010
Abstract: In this paper we propose a novel approach to binocular stereo for fast matching of high-resolution images. Our approach builds a prior on the disparities by forming a triangulation on a set of support points which can be robustly matched, reducing the matching ambiguities of the remaining points. This allows for efficient exploitation of the disparity search space, yielding accurate dense reconstruction without the need for global optimization. Moreover, our method automatically determines the disparity range and can be easily parallelized. We demonstrate the effectiveness of our approach on the large-scale Middlebury benchmark, and show that state-of-the-art performance can be achieved with significant speedups. Computing the left and right disparity maps for a one Megapixel image pair takes about one second on a single CPU core.
Latex Bibtex Citation:
@inproceedings{Geiger2010ACCV,
author = { GeigerandAndreas and RoserandMartin and UrtasunandRaquel},
title = {Efficient Large-Scale Stereo Matching},
booktitle = {Asian Conference on Computer Vision (ACCV)},
year = {2010}
}
Latex Bibtex Citation:
@inproceedings{Geiger2010ACCV,
author = { GeigerandAndreas and RoserandMartin and UrtasunandRaquel},
title = {Efficient Large-Scale Stereo Matching},
booktitle = {Asian Conference on Computer Vision (ACCV)},
year = {2010}
}

Realistic Modeling of Water Droplets for Monocular Adherent Raindrop Recognition using Bezier Curves
M. Roser, J. Kurz and A. Geiger
Asian Conference on Computer Vision (ACCV) Workshops, 2010
M. Roser, J. Kurz and A. Geiger
Asian Conference on Computer Vision (ACCV) Workshops, 2010
Abstract: In this paper, we propose a novel raindrop shape model for the detection of view-disturbing, adherent raindrops on inclined surfaces. Whereas state-of-the-art techniques do not consider inclined surfaces because they assume the droplets as sphere sections with equal contact angles, our model incorporates cubic Bezier curves that provide a low dimensional and physically interpretable representation of a raindrop surface. The parameters are empirically deduced from numerous observations of different raindrop sizes and surface inclination angles. It can be easily integrated into a probabilistic framework for raindrop recognition, using geometrical optics to simulate the visual raindrop appearance. In comparison to a sphere section model, the proposed model yields an improved droplet surface accuracy up to three orders of magnitude.
Latex Bibtex Citation:
@inproceedings{Roser2010ACCVWORK,
author = {Martin Roser and Julian Kurz and Andreas Geiger},
title = {Realistic Modeling of Water Droplets for Monocular Adherent Raindrop Recognition using Bezier Curves},
booktitle = {Asian Conference on Computer Vision (ACCV) Workshops},
year = {2010}
}
Latex Bibtex Citation:
@inproceedings{Roser2010ACCVWORK,
author = {Martin Roser and Julian Kurz and Andreas Geiger},
title = {Realistic Modeling of Water Droplets for Monocular Adherent Raindrop Recognition using Bezier Curves},
booktitle = {Asian Conference on Computer Vision (ACCV) Workshops},
year = {2010}
}

ObjectFlow: A Descriptor for Classifying Traffic Motion
A. Geiger and B. Kitt
Intelligent Vehicles Symposium (IV), 2010
A. Geiger and B. Kitt
Intelligent Vehicles Symposium (IV), 2010
Abstract: We present and evaluate a novel scene descriptor for classifying urban traffic by object motion. Atomic 3D flow vectors are extracted and compensated for the vehicle's egomotion, using stereo video sequences. Votes cast by each flow vector are accumulated in a bird's eye view histogram grid. Since we are directly using low-level object flow, no prior object detection or tracking is needed. We demonstrate the effectiveness of the proposed descriptor by comparing it to two simpler baselines on the task of classifying more than 100 challenging video sequences into intersection and non-intersection scenarios. Our experiments reveal good classification performance in busy traffic situations, making our method a valuable complement to traditional approaches based on lane markings.
Latex Bibtex Citation:
@inproceedings{Geiger2010IV,
author = {Andreas Geiger and Bernd Kitt},
title = {ObjectFlow: A Descriptor for Classifying Traffic Motion},
booktitle = {Intelligent Vehicles Symposium (IV)},
year = {2010}
}
Latex Bibtex Citation:
@inproceedings{Geiger2010IV,
author = {Andreas Geiger and Bernd Kitt},
title = {ObjectFlow: A Descriptor for Classifying Traffic Motion},
booktitle = {Intelligent Vehicles Symposium (IV)},
year = {2010}
}

Visual Odometry based on Stereo Image Sequences with RANSAC-based Outlier Rejection Scheme (oral)
B. Kitt, A. Geiger and H. Lategahn
Intelligent Vehicles Symposium (IV), 2010
B. Kitt, A. Geiger and H. Lategahn
Intelligent Vehicles Symposium (IV), 2010
Abstract: A common prerequisite for many vision-based driver assistance systems is the knowledge of the vehicle's own movement. In this paper we propose a novel approach for estimating the egomotion of the vehicle from a sequence of stereo images. Our method is directly based on the trifocal geometry between image triples, thus no time expensive recovery of the 3-dimensional scene structure is needed. The only assumption we make is a known camera geometry, where the calibration may also vary over time. We employ an Iterated Sigma Point Kalman Filter in combination with a RANSAC-based outlier rejection scheme which yields robust frame-to-frame motion estimation even in dynamic environments. A high-accuracy inertial navigation system is used to evaluate our results on challenging real-world video sequences. Experiments show that our approach is clearly superior compared to other filtering techniques in terms of both, accuracy and run-time.
Latex Bibtex Citation:
@inproceedings{Kitt2010IV,
author = {Bernd Kitt and Andreas Geiger and Henning Lategahn},
title = {Visual Odometry based on Stereo Image Sequences with RANSAC-based Outlier Rejection Scheme},
booktitle = {Intelligent Vehicles Symposium (IV)},
year = {2010}
}
Latex Bibtex Citation:
@inproceedings{Kitt2010IV,
author = {Bernd Kitt and Andreas Geiger and Henning Lategahn},
title = {Visual Odometry based on Stereo Image Sequences with RANSAC-based Outlier Rejection Scheme},
booktitle = {Intelligent Vehicles Symposium (IV)},
year = {2010}
}
2009

Rank Priors for Continuous Non-Linear Dimensionality Reduction
A. Geiger, R. Urtasun and T. Darrell
Conference on Computer Vision and Pattern Recognition (CVPR), 2009
A. Geiger, R. Urtasun and T. Darrell
Conference on Computer Vision and Pattern Recognition (CVPR), 2009
Abstract: Discovering the underlying low-dimensional latent structure in high-dimensional perceptual observations (e.g., images, video) can, in many cases, greately improve performance in recognition and tracking. However, non-linear dimensionality reduction methods are often susceptible to local minima and perform poorly when initialized far from the global optimum, even when the intrinsic dimensionality is known a priori. In this work we introduce a prior over the dimensionality of the latent space that penalizes high dimensional spaces, and simultaneously optimize both the latent space and its intrinsic dimensionality in a continuous fashion. Ad-hoc initialization schemes are unnecessarywith our approach; we initialize the latent space to the observation space and automatically infer the latent dimensionality. We report results applying our prior to various probabilistic non-linear dimensionality reduction tasks, and show that our method can outperform graph-based dimensionality reduction techniques as well as previously suggested initialization strategies. We demonstrate the effectiveness of our approach when tracking and classifying human motion.
Latex Bibtex Citation:
@inproceedings{Geiger2009CVPR,
author = {Andreas Geiger and Raquel Urtasun and Trevor Darrell},
title = {Rank Priors for Continuous Non-Linear Dimensionality Reduction},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2009}
}
Latex Bibtex Citation:
@inproceedings{Geiger2009CVPR,
author = {Andreas Geiger and Raquel Urtasun and Trevor Darrell},
title = {Rank Priors for Continuous Non-Linear Dimensionality Reduction},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2009}
}

Video-based Raindrop Detection for Improved Image Registration
M. Roser and A. Geiger
International Conference on Computer Vision (ICCV) Workshops, 2009
M. Roser and A. Geiger
International Conference on Computer Vision (ICCV) Workshops, 2009
Abstract: In this paper we present a novel approach to improved image registration in rainy weather situations. To this end, we perform monocular raindrop detection in single images based on a photometric raindrop model. Our method is capable of detecting raindrops precisely, even in front of complex backgrounds. The effectiveness is demonstrated by a significant increase in image registration accuracy which also allows for successful image restoration. Experiments on video sequences taken from within a moving vehicle prove the applicability to real-world scenarios.
Latex Bibtex Citation:
@inproceedings{Roser2009ICCVWORK,
author = {Martin Roser and Andreas Geiger},
title = {Video-based Raindrop Detection for Improved Image Registration},
booktitle = {International Conference on Computer Vision (ICCV) Workshops},
year = {2009}
}
Latex Bibtex Citation:
@inproceedings{Roser2009ICCVWORK,
author = {Martin Roser and Andreas Geiger},
title = {Video-based Raindrop Detection for Improved Image Registration},
booktitle = {International Conference on Computer Vision (ICCV) Workshops},
year = {2009}
}

Monocular road mosaicing for urban environments
A. Geiger
Intelligent Vehicles Symposium (IV), 2009
A. Geiger
Intelligent Vehicles Symposium (IV), 2009
Abstract: Marking-based lane recognition requires an unobstructed view onto the road. In practice however, heavy traffic often constrains the visual field, especially in urban scenarios such as urban crossroads. In this paper we present a novel approach to road mosaicing for dynamic environments. Our method is based on a multistage registration procedure and uses blending techniques. We show that under modest assumptions accurate registration is possible from monocular image sequences. We further demonstrate that fusing visual information from previous frames into the current view can greatly extend the camera's field of view.
Latex Bibtex Citation:
@inproceedings{Geiger2009IV,
author = {Andreas Geiger},
title = {Monocular road mosaicing for urban environments},
booktitle = {Intelligent Vehicles Symposium (IV)},
year = {2009}
}
Latex Bibtex Citation:
@inproceedings{Geiger2009IV,
author = {Andreas Geiger},
title = {Monocular road mosaicing for urban environments},
booktitle = {Intelligent Vehicles Symposium (IV)},
year = {2009}
}
2008

Topologically-Constrained Latent Variable Models
R. Urtasun, D. Fleet, A. Geiger, J. Popovic, T. Darrell and N. Lawrence
International Conference on Machine learning (ICML), 2008
R. Urtasun, D. Fleet, A. Geiger, J. Popovic, T. Darrell and N. Lawrence
International Conference on Machine learning (ICML), 2008
Abstract: In dimensionality reduction approaches, the data are typically embedded in a Euclidean latent space. However for some data sets this is inappropriate. For example, in human motion data we expect latent spaces that are cylindrical or a toroidal, that are poorly captured with a Euclidean space. In this paper, we present a range of approaches for embedding data in a non-Euclidean latent space. Our focus is the Gaussian Process latent variable model. In the context of human motion modeling this allows us to (a) learn models with interpretable latent directions enabling, for example, style/content separation, and (b) generalise beyond the data set enabling us to learn transitions between motion styles even though such transitions are not present in the data.
Latex Bibtex Citation:
@inproceedings{Urtasun2008ICML,
author = {Raquel Urtasun and David Fleet and Andreas Geiger and Jovan Popovic and Trevor Darrell and Neil Lawrence},
title = {Topologically-Constrained Latent Variable Models},
booktitle = {International Conference on Machine learning (ICML)},
year = {2008}
}
Latex Bibtex Citation:
@inproceedings{Urtasun2008ICML,
author = {Raquel Urtasun and David Fleet and Andreas Geiger and Jovan Popovic and Trevor Darrell and Neil Lawrence},
title = {Topologically-Constrained Latent Variable Models},
booktitle = {International Conference on Machine learning (ICML)},
year = {2008}
}

Human Body Tracking with Rank Priors for Non-Linear Dimensionality Reduction
A. Geiger
Masters Thesis, 2008
A. Geiger
Masters Thesis, 2008
Abstract: Non-linear dimensionality reduction methods are powerful techniques to deal with high-dimensional datasets. However, they often are susceptible to local minima and perform poorly when initialized far from the global optimum, even when the intrinsic dimensionality is known a priori. In this work we introduce a prior over the dimensionality of the latent space, and simultaneously optimize both the latent space and its intrinsic dimensionality. Ad-hoc initialization schemes are unnecessary with our approach; we initialize the latent space to the observation space and automatically infer the latent dimensionality using an optimization scheme that drops dimensions in a continuous fashion. We report results applying our prior to various tasks involving probabilistic non-linear dimensionality reduction, and show that our method can outperform graph-based dimensionality reduction techniques as well as previously suggested ad-hoc initialization strategies.
Latex Bibtex Citation:
@mastersthesis{Geiger2008,
author = {Andreas Geiger},
title = {Human Body Tracking with Rank Priors for Non-Linear Dimensionality Reduction},
school = {Massachusetts Institute of Technology},
year = {2008}
}
Latex Bibtex Citation:
@mastersthesis{Geiger2008,
author = {Andreas Geiger},
title = {Human Body Tracking with Rank Priors for Non-Linear Dimensionality Reduction},
school = {Massachusetts Institute of Technology},
year = {2008}
}
2006

An All-in-One Solution to Geometric and Photometric Calibration
J. Pilet, A. Geiger, P. Lagger, V. Lepetit and P. Fua
International Symposium on Mixed and Augmented Reality (ISMAR), 2006
J. Pilet, A. Geiger, P. Lagger, V. Lepetit and P. Fua
International Symposium on Mixed and Augmented Reality (ISMAR), 2006
Abstract: We propose a fully automated approach to calibrating multiple cameras whose fields of view may not all overlap. Our technique only requires waving an arbitrary textured planar pattern in front of the cameras, which is the only manual intervention that is required. The pattern is then automatically detected in the frames where it is visible and used to simultaneously recover geometric and photometric camera calibration parameters. In other words, even a novice user can use our system to extract all the information required to add virtual 3D objects into the scene and light them convincingly. This makes it ideal for Augmented Reality applications and we distribute the code under a GPL license.
Latex Bibtex Citation:
@inproceedings{Pilet2006ISMAR,
author = {Julien Pilet and Andreas Geiger and Pascal Lagger and Vincent Lepetit and Pascal Fua},
title = {An All-in-One Solution to Geometric and Photometric Calibration},
booktitle = {International Symposium on Mixed and Augmented Reality (ISMAR)},
year = {2006}
}
Latex Bibtex Citation:
@inproceedings{Pilet2006ISMAR,
author = {Julien Pilet and Andreas Geiger and Pascal Lagger and Vincent Lepetit and Pascal Fua},
title = {An All-in-One Solution to Geometric and Photometric Calibration},
booktitle = {International Symposium on Mixed and Augmented Reality (ISMAR)},
year = {2006}
}