Submitted on 28 Nov. 2024 09:49 by mingqi wang (palomar college)
|
Method
Detailed Results
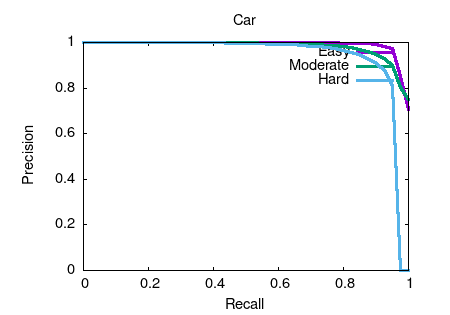
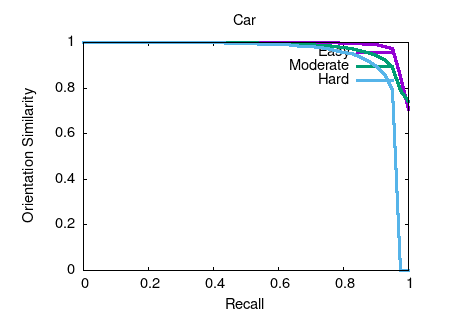
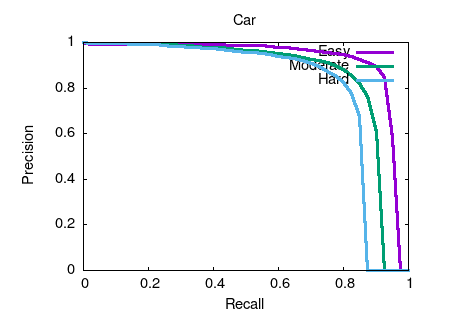
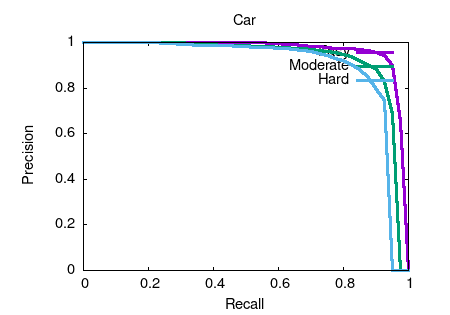
Object detection and orientation estimation results. Results for object detection are given in terms of average precision (AP) and results for joint object detection and orientation estimation are provided in terms of average orientation similarity (AOS).
|